In 1945, Vannevar Bush published an essay in The Atlantic titled "As We May Think." Bush, who had directed American scientific research during World War II, described a hypothetical device he called the "memex" - a microfilm-based machine that would allow a person to store and retrieve books, records, and communications, and to build associative trails linking related information across sources.
"The human mind," Bush wrote, "operates by association. With one item in its grasp, it snaps instantly to the next that is suggested by the association of thoughts."
Bush's memex was never built, but the problem it was meant to solve - the problem of finding information within an ever-growing body of human knowledge - became the central challenge of the information age.
When the World Wide Web began growing rapidly in the early 1990s, the problem Bush described became acute: a web of millions, then hundreds of millions, then billions of documents, with no systematic way to navigate it except by knowing where to go or following links from pages you already knew.
The search engine was the solution. What began as simple text matching against a manually maintained index has evolved, over thirty years of continuous development, into one of the most sophisticated information systems ever built - one that processes 8.5 billion queries per day, understands human language with near-human nuance, and returns results within half a second by coordinating across networks of computers spanning six continents.
Understanding how this system works - in the depth that produces useful insight rather than the superficiality of a marketing summary - matters for anyone who creates content or depends on search traffic.
It explains why rankings behave the way they do, why some optimization tactics work and others fail, and what the sustainable path to search visibility actually looks like.
The Three-Stage Pipeline
Every search engine, regardless of the specific technology, operates through three sequential stages: discovering content that exists on the web (crawling), analyzing and storing that content in a form suitable for fast retrieval (indexing), and answering specific queries by identifying and ranking the most relevant indexed content (ranking).
These stages are interdependent: ranking requires indexing, indexing requires crawling, and crawling requires that content exists and is accessible. Failures at any stage cascade downstream. Content that is not crawled cannot be indexed. Content that is not indexed cannot rank.
Content that ranks but loads poorly on mobile devices may receive traffic but will not satisfy the users it attracts.
| Pipeline Stage | What Happens | Can Fail When | Diagnose With |
|---|---|---|---|
| Crawling | Bot discovers and downloads page | Robots.txt blocks, no inlinks, server errors | Google Search Console Coverage |
| Indexing | Content analyzed, quality assessed | Thin content, duplicates, low quality signals | Search Console Indexing reports |
| Ranking | Algorithm scores page for queries | Low authority, poor relevance, weak E-E-A-T | Ranking tools, Search Console Queries |
| Serving | Results presented to user | None (post-ranking) | Not applicable |
"Understanding how this system works - in the depth that produces useful insight rather than the superficiality of a marketing summary - matters for anyone who creates content or depends on search traffic. Rankings behave the way they do for reasons that are understandable and actionable." - Google Search documentation
Stage One: Crawling
The Discovery Problem
The web contains an estimated 5.4 billion indexed pages as of 2024, and substantially more that exist but are not indexed. New pages are created and existing pages change continuously.
The crawling system's task is perpetually incomplete: it must discover new content, revisit existing content to detect changes, and prioritize which pages receive attention given finite computational resources.
Google's crawling system - called Googlebot - approaches this problem as a distributed scheduling and retrieval problem. At any moment, hundreds of thousands of concurrent fetch requests are in flight across Google's server infrastructure.
The system must decide, continuously, which URLs to fetch next, how frequently to revisit each domain, and how to distribute crawling load across domains to avoid overwhelming individual web servers.
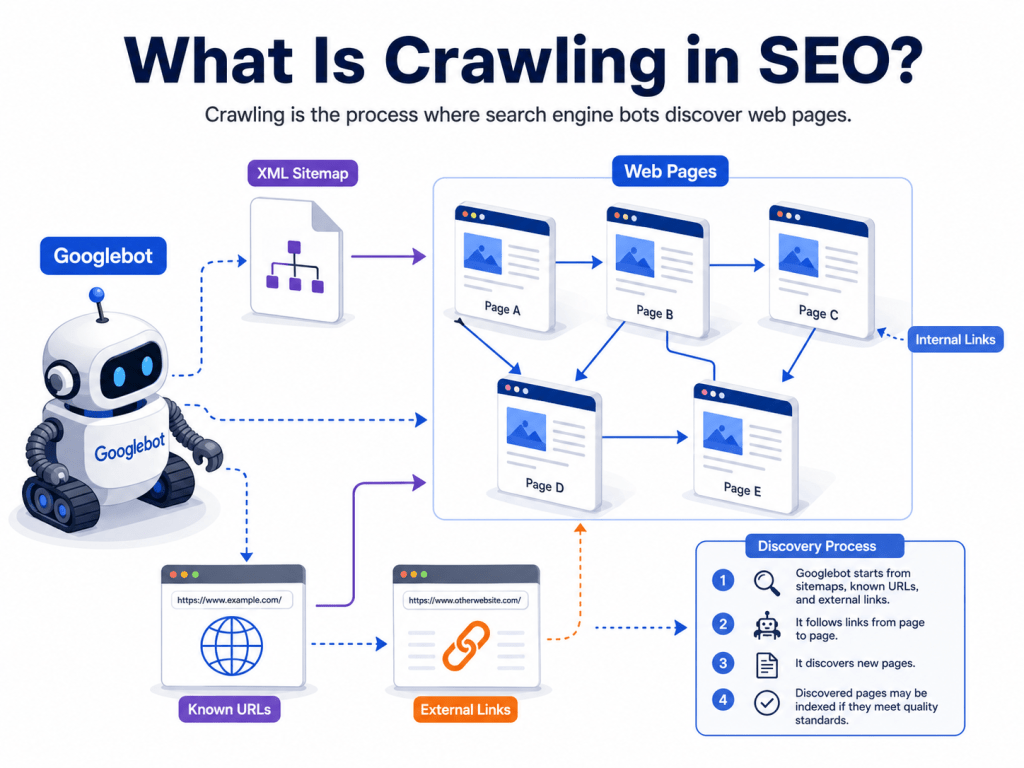
Following Links: The Primary Discovery Mechanism
The fundamental mechanism by which new pages are discovered is the same mechanism Vannevar Bush described in 1945: following associations. Googlebot downloads a page, parses its HTML to extract all links, and adds those links to a queue of URLs to visit.
Each newly visited page yields more links, which yield more pages, which yield more links.
This process, applied at internet scale and running continuously, builds a graph that represents a significant portion of the World Wide Web. The structure of this graph - which pages link to which other pages - is itself one of the most important signals in the ranking system, as described later.
The implication for website owners is direct: pages that are not linked to from anywhere Googlebot can reach will not be discovered through this mechanism.
A page that exists in your content management system but has no internal links pointing to it, no external links, and is not included in any sitemap, is effectively invisible to search engines.
This is why internal link architecture is not merely an organization question - it is a discoverability question.
Sitemaps: The Alternative Discovery Path
XML sitemaps provide a parallel path to discovery: instead of waiting for Googlebot to find your content by following links, you submit a structured list of your content directly. A sitemap declares the URLs that exist on your site, when they were last modified, and optionally how frequently they change.
Submitting sitemaps through Google Search Console does not guarantee that listed pages will be crawled or indexed. It guarantees that the URLs are known to Google.
Crawling those URLs then depends on the same prioritization factors that govern all crawling: the site's authority, the server's response speed, and the content's assessed quality.
The practical value of sitemaps is highest for large sites with deep or complex navigation where Googlebot might miss some pages through link-following alone, and for new content that you want discovered quickly rather than waiting for link-following to reach it.
Crawl Rate and Crawl Budget
Googlebot does not crawl all sites with equal frequency. The frequency and depth of crawling for a given site reflects the site's assessed importance and the efficiency of crawling it.
Sites that are highly authoritative, frequently updated, and technically well-optimized receive more frequent and more thorough crawling. A major news publication might have its pages crawled within minutes of publication. A small personal website might be crawled once a week or less.
The concept of "crawl budget" describes the practical limit on how much Googlebot will crawl a given site in a given period. For most websites - those with fewer than a few thousand pages that are well-maintained and load quickly - crawl budget is not a limiting factor.
For large e-commerce sites with hundreds of thousands of product pages, faceted navigation that generates millions of URL combinations, or substantial duplicate content, crawl budget management becomes a genuine technical priority.
The factors that drain crawl budget without productive results: URLs that return server errors, redirect chains that add round trips without adding content, duplicate pages accessible at multiple URLs, URLs with parameters that create near-duplicate versions of the same content, and pages blocked by robots.txt that are still linked to from within the site (causing Googlebot to fetch URLs it then cannot process).
Robots.txt and Crawl Control
The robots.txt file, placed at the root of a domain, provides instructions to crawlers about which parts of a site they may access. A directive like Disallow: /admin/ tells well-behaved crawlers not to access the /admin/ path.
Robots.txt is advisory, not enforced. Well-behaved crawlers (Googlebot, Bingbot) respect it; malicious scrapers ignore it. The file is appropriate for preventing crawling of administrative interfaces, development environments, or content you genuinely do not want indexed.
It is not appropriate for blocking content you want to rank - blocking a page from crawling prevents it from being indexed.
The noindex meta tag serves a different purpose: it allows a page to be crawled but instructs the search engine not to include it in its index. This is the appropriate mechanism for pages that should be accessible to users (like thank-you pages after form submission) but not indexed.
Stage Two: Indexing
From HTML to Understanding
After Googlebot fetches a page, the content undergoes analysis and storage. Indexing is not simply storing a copy of the page - it is transforming the raw content into representations that allow fast, semantically meaningful retrieval.
The first step is rendering. Modern web pages are dynamic: much of their content is generated by JavaScript after the initial HTML loads. Googlebot can execute JavaScript, but rendering is resource-intensive.
The indexing system must decide, for each page, whether to invest in full JavaScript rendering or to index based on the initial HTML.
Pages where important content is visible only after JavaScript execution may not have that content indexed if the rendering cost is deemed too high relative to the expected value.
The practical implication: important content should be present in the initial server-rendered HTML, not dependent on JavaScript for display. This is particularly important for content that search engines need to understand: main body text, headings, and links.
Language Analysis and Entity Understanding
Once the content is rendered, the indexing system applies natural language processing to understand what the page is about. This has evolved from simple keyword frequency analysis to genuine semantic understanding.
Google's BERT model (Bidirectional Encoder Representations from Transformers), introduced in 2019, represented a significant advance: it understands the meaning of words in context rather than treating each word in isolation.
The sentence "The bank was steep and covered in mud" means something entirely different from "The bank refused to approve the loan," even though both contain the word "bank." BERT can distinguish between these meanings.
Google's MUM (Multitask Unified Model), introduced in 2021, goes further: it can process multiple types of content simultaneously (text, images) and understands relationships across languages.
A search for information that exists in Japanese but not in English can now surface the Japanese content with an understanding of its relevance to an English query.
Entity extraction identifies specific people, places, organizations, products, events, and concepts in the content.
A page about "the Federal Reserve's 2023 interest rate decisions" is understood as being about a specific institution (the Federal Reserve), a specific time period (2023), and a specific topic (interest rate policy).
This entity-level understanding allows matching pages to queries based on semantic relationships rather than keyword overlap.
The Index Structure
The processed content is stored in a specialized data structure called an inverted index.
Rather than storing pages and searching through them sequentially for each query, the inverted index stores, for each meaningful term, a list of all pages that contain that term and information about how it appears (in the title, in body text, in headers, with what frequency, in proximity to what other terms).
This structure makes retrieval fast: answering a query requires looking up the query terms in the inverted index to get candidate page lists, then intersecting those lists to find pages that contain all relevant terms, then applying ranking signals to order the results.
The scale of this index is difficult to comprehend. Google's index is estimated to span hundreds of billions of web pages. The index must be fast enough to respond to 8.5 billion queries per day, most within half a second. It is one of the largest and most sophisticated database systems ever built.
Deduplication and Canonicalization
The web contains enormous amounts of duplicate content. The same article might be accessible at multiple URLs (with and without trailing slashes, with and without www, in HTTP and HTTPS versions). Syndicating content creates copies across multiple sites.
Faceted navigation on e-commerce sites creates thousands of near-identical product listing pages.
The indexing system identifies duplicate and near-duplicate pages and selects one canonical version to include in the index. The canonical page is typically the one that most pages link to, or the one explicitly designated by a <link rel="canonical"> tag.
Understanding canonicalization prevents the common mistake of diluting ranking signals across multiple URLs for the same content.
If your most important product category page is accessible at three different URLs with no canonical tag declaring the preferred version, the authority that links would otherwise concentrate on one URL is split three ways.
Stage Three: Ranking
The Scale of the Problem
When a user searches for "best productivity strategies," Google's index contains millions of pages with some relevance to this query. The ranking system must evaluate these candidates and order them in a way that puts the most useful results first - in under half a second.
The ranking problem is a multi-dimensional optimization. The goal is not to find the pages that mention the query terms most frequently. It is to find the pages that best answer the actual question the user is asking, from a credible source, in a form they can access easily. Each of these dimensions requires different signals.
Relevance: Does This Page Answer the Question?
The first filtering criterion is relevance: does the page's content address what the user is looking for? Modern relevance assessment goes far beyond keyword matching.
Query intent classification is perhaps the most important advance. Search engines classify queries by the underlying intent:
An informational intent query ("how does compound interest work") seeks an explanation. The ideal result is a clear, thorough explanation, not a product page for a compound interest calculator.
A commercial investigation intent query ("best savings account 2024") signals that the user is comparing options before deciding. The ideal result is a comparison that helps evaluation, not a product page for a single option.
A transactional intent query ("open a high-yield savings account online") signals readiness to act. The ideal result is a product page that enables the action.
A navigational intent query ("Chase bank login") signals that the user wants a specific site. The ideal result is the homepage or login page of Chase Bank.
The search engine's classification of query intent determines which type of content is even eligible to rank for a given query. A page that is the world's best explanation of compound interest is not the right result for a transactional query about opening a savings account, regardless of its quality.
Semantic relevance extends beyond whether a page contains the query terms to whether it covers the topic comprehensively and with appropriate vocabulary.
A page about "machine learning for beginners" that never mentions "training data," "model," "accuracy," or "classification" is unlikely to be considered expert coverage of the topic, even if the keyword phrase appears repeatedly.
Authority: Should This Source Be Trusted?
The insight that founded modern web search - Larry Page's PageRank algorithm, described in a 1998 Stanford paper - was that the structure of links between web pages encodes information about the relative authority of those pages.
A page linked to by many highly-linked pages is more likely to be authoritative than one linked to by few or low-authority pages.
This insight remains central to ranking, though PageRank in its original form is no longer the primary mechanism. Link-based authority signals have been refined to account for the topical relevance of linking sites, the context of the link within the linking page, the anchor text used in the link, and the diversity of the linking sites.
The practical meaning: when The New York Times cites your research, this is a stronger authority signal than when a small blog with few readers does. When a publication in your specific domain links to you, this is a stronger topical authority signal than when a general news site links to you.
When many different independent sites link to you, this is a stronger signal than many links from sites that are part of the same network.
Author expertise and institutional authority are increasingly incorporated as ranking signals, reflected in the E-E-A-T framework. Content from identifiable experts with verifiable credentials, published on platforms with established reputations, benefits from trust signals that content without these attributes lacks.
User Experience: Can People Actually Use This Page?
A page with excellent content and strong authority that takes eight seconds to load on a mobile device, shifts around as elements render, or presents a difficult-to-navigate interface is failing users. Search engines have incorporated user experience signals as ranking factors because they are part of what makes a result genuinely useful.
Core Web Vitals - Largest Contentful Paint, Interaction to Next Paint, and Cumulative Layout Shift - became confirmed ranking signals in 2021. These measure the perceived load speed, responsiveness, and visual stability of a page respectively. They represent the user's experience of page performance, not raw technical metrics.
Mobile-friendliness is not optional. Google has used mobile-first indexing since 2019, meaning it primarily crawls and indexes the mobile version of pages. Content that is present on the desktop version but absent on the mobile version may not be indexed at all.
HTTPS is baseline. Pages still served over HTTP are marked "not secure" in browsers and carry a negative trust signal.
Freshness: Is This Information Current?
For queries where information changes over time, the recency of content affects ranking. News queries, queries about current events, queries that include date references ("2024"), and queries about rapidly evolving topics all benefit from recent content.
The freshness signal works differently across query types. A query about "the Battle of Thermopylae" has no freshness dimension - the best explanation written in 2010 is as relevant as one written in 2024.
A query about "current mortgage rates" requires very recent data to be useful. The ranking system attempts to calibrate freshness weight to the likely information needs of the query.
Content updates can extend the freshness signal of existing pages. Revising a page to reflect current information, add recent data, and update outdated claims signals to the indexing system that the page is being maintained.
The Evolution of Search: From Keywords to Understanding
The Early Web Era
The first generation of web search engines in the early 1990s - WebCrawler, Lycos, AltaVista - operated through term-frequency analysis. A page ranked for "gardening tools" based primarily on how many times "gardening" and "tools" appeared in its text.
This was easy to understand and easy to manipulate: webmasters who stuffed their pages with target keywords could rank well regardless of content quality.
Link-based ranking, pioneered by Google's PageRank algorithm in 1998, added a new dimension that was significantly harder to manipulate at scale. Two pages with equal keyword density would be differentiated by which one had more authoritative pages linking to it.
The Quality Era
A series of major algorithm updates beginning in 2011 represented Google's systematic effort to align rankings with genuine quality:
Panda (February 2011) penalized content farms and sites with thin, low-quality content. Demand Media, which had built a business around producing vast quantities of keyword-targeted content at low cost, lost 40% of its traffic within weeks.
Penguin (April 2012) targeted manipulative link building - paid links, link farms, and other artificial schemes. Sites that had invested heavily in these tactics saw dramatic traffic declines.
Hummingbird (August 2013) was the first major overhaul of the ranking algorithm itself rather than a penalty targeting specific behaviors. It introduced semantic search: understanding the meaning and intent behind queries rather than matching keywords.
"What year did the Titanic sink?" could now be understood as a factual question with a specific answer rather than a request for pages containing those words.
RankBrain (2015) introduced machine learning to query interpretation. For the estimated 15% of queries Google had never seen before (even today, roughly 15% of daily searches are novel), machine learning allowed interpretation by analogy rather than requiring pre-existing data.
BERT (2019) brought transformer-based language models to search. The prepositions in a query now carried meaning: "can you get medicine for someone at a pharmacy" produces results about getting prescriptions on behalf of another person, not generic pharmacy results.
The cumulative effect of this trajectory is a system that has moved from keyword matching to something approaching semantic understanding.
The questions that motivated Vannevar Bush in 1945 - how can a person find information within a vast body of knowledge, following associations between related concepts - are now answered by a system that attempts to understand both the information and the query at the level of meaning.
Practical Implications for Content Creators
Making Content Discoverable
Content that exists but cannot be found by crawlers provides no value in search. The discoverability checklist:
Submit an XML sitemap through Google Search Console, listing all important pages and their modification dates.
Ensure that all important content is linked from within your site through a logical navigation structure - pages deep in the architecture with no internal links pointing to them are difficult for crawlers to discover and remain without authority from your site's internal link equity.
Monitor Google Search Console for crawl errors: pages that return server errors (5xx), client errors (4xx for pages that should exist), or pages that are blocked by robots.txt or noindex tags when they should be accessible. These errors represent missed opportunities for indexing.
Making Content Understandable
Once Googlebot can reach a page, the indexing system needs to understand what it is about. The signals that aid understanding:
A page title that accurately describes the primary topic of the page, in language that matches how people search for that topic. A hierarchy of headings (H1 for the primary topic, H2 for major subtopics, H3 for sub-subtopics) that structures the content for both reading and indexing.
Body content that covers the topic with the vocabulary and depth appropriate to genuine expertise.
Schema.org structured data markup makes implicit information explicit: this is an article, authored by this person, published on this date, about this topic. This markup enables rich results in search (FAQ accordions, article rich snippets, review stars, event cards) and helps the indexing system categorize content correctly.
Making Authority Legitimate
The authority signals that search systems rely on cannot be systematically manufactured. Links from authoritative sources are earned by publishing content that those sources find worth citing.
This requires a long-term perspective: producing content that is genuinely useful, well-researched, and accurately sourced over extended periods, building a reputation that causes others to cite and link to your work.
The algorithmic changes of the past decade have systematically penalized artificial authority signals while improving the detection of genuine ones. The sustainable path is alignment between what the algorithms are trying to measure (genuine authority based on merit) and what you are building (genuine authority based on merit).
See also: Indexing and Crawling Explained, Technical SEO Explained, and Content Quality Signals Explained.
What Google's Research Papers and Engineers Reveal About Ranking
The academic and technical literature from Google's research teams provides more precise insight into ranking mechanisms than most SEO commentary, and several foundational papers remain essential reading for understanding how the system actually operates.
The Original PageRank Paper (1998): Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd published "The PageRank Citation Ranking: Bringing Order to the Web" as Stanford Technical Report 1999-66.
The paper's core insight - that the probability distribution of a random web surfer clicking links would converge to a stable distribution reflecting each page's importance - remains the conceptual foundation of link-based authority.
The paper describes the mathematical model in detail: each page's PageRank is the sum of the PageRank of pages linking to it, divided by the number of links on each of those pages.
Google's subsequent development of PageRank has extended this model substantially, but the fundamental principle that the structure of the link graph encodes authority information is unchanged.
BERT's Impact on Search (2019): The technical paper "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," authored by Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova of Google Brain, describes the model architecture that Google introduced into search in October 2019.
Google's Pandu Nayak (VP of Search) described the BERT rollout in a blog post as "the biggest leap forward in the past five years" for search quality.
The critical advance is bidirectionality: earlier language models processed text left-to-right or right-to-left, missing contextual relationships between words separated by intervening text.
BERT processes the entire sentence simultaneously, enabling it to understand that "the bank of the river" and "the bank rejected the loan" use the word "bank" with entirely different meanings.
This directly affected how queries with subtle language distinctions are interpreted.
MUM (Multitask Unified Model, 2021): Google's Pandu Nayak announced MUM at Google I/O 2021, describing it as "1,000 times more powerful than BERT." Nayak explained that MUM can simultaneously understand text in 75 languages, process images, and transfer knowledge across languages - meaning information that exists only in Japanese can be surfaced for an English query if MUM determines it is relevant.
MUM was initially deployed for specific use cases (COVID-related searches, complex informational queries) before broader integration.
Jeff Dean, Google's Senior Vice President of Research, described MUM in a 2021 research blog post as enabling search to "better understand the nuances of human language in the context of complex, multi-step tasks."
Navneet Panda and Content Quality Signals: The engineer whose name the 2011 Panda update bears - Navneet Panda - was credited in multiple Google blog posts for developing a machine learning classifier capable of identifying thin, low-quality content at scale.
In a 2011 Inside Search blog post authored by Amit Singhal (then head of Google Search) and Matt Cutts, Google described using human quality rater assessments to train the classifier, asking raters questions like "Would you trust a friend to give you this page as a recommendation?" and "Would you be comfortable giving this page your credit card information?" The classifier learned to predict these human quality assessments and apply them algorithmically to billions of pages - a methodology that established the template for subsequent quality-focused algorithm updates including the 2022 Helpful Content system.
RankBrain and Machine Learning in Ranking (2015): Google's Greg Corrado described RankBrain to Bloomberg in October 2015 as having become the third most important ranking signal within months of its deployment.
Corrado explained that RankBrain's primary function was interpreting novel queries - the approximately 15% of daily queries that Google had never seen before.
By mapping new queries to conceptually similar known queries, RankBrain could provide relevant results for queries with no historical data, relying on learned semantic relationships rather than explicit pattern matching. By 2016, Google's Gary Illyes confirmed in a tweet that RankBrain was applied to every query, not just novel ones.
Real-World Case Studies: How Search Engine Mechanics Affect Actual Sites
The theoretical mechanics of crawling, indexing, and ranking have concrete practical consequences documented in specific site histories.
Demand Media and the Panda Effect (2011): Demand Media, which operated eHow.com and other content properties, was the canonical example of content farm economics before Panda: it employed thousands of freelance writers to produce short articles targeting specific keyword phrases identified through search volume data, paying approximately $15 per article.
The company went public in January 2011 and was valued at over $1.5 billion. When the Panda update rolled out in February 2011, eHow.com lost approximately 40% of its organic traffic within two weeks, as documented by Sistrix's visibility index data.
The loss of traffic translated directly to revenue decline, and Demand Media began a multi-year restructuring that culminated in the company's breakup.
The case is significant because it demonstrated, with financial consequences at scale, that the quality signals Panda was trained to detect were real and that content farm economics were not sustainable against algorithmic enforcement.
The New York Times Paywall and Crawling (2011): When The New York Times introduced its metered paywall in 2011, it created an interesting case study in crawling and rendering.
The NYT allowed search engine crawlers full access to paywalled content (enabling indexing of full articles) while showing only abstracts to users who had exhausted their free article quota.
This practice - called "first click free" in Google's published guidance - was a documented allowable approach that enabled news content to rank in search results while still maintaining a subscription model.
The arrangement persisted until 2017, when Google ended the first-click-free requirement. The NYT case illustrates that search engine crawling policies are not static and that the rules governing what crawlers can access versus what users see are separately negotiated.
Wikipedia's Link Authority Distribution: A 2021 study by Ahrefs analyzing the Wikipedia link graph found that Wikipedia's internal linking structure distributes authority in a power-law distribution closely matching PageRank's mathematical model: a small number of highly-linked hub articles accumulate enormous internal authority while the long tail of specific topic articles receives relatively little.
The most-linked Wikipedia pages (Main page, United States, World War II) have hundreds of thousands of inbound links from other Wikipedia articles.
This link structure is why Wikipedia consistently ranks highly across an enormous range of queries: it is a massive, highly-interconnected authority network where the link structure accurately encodes the relative importance of topics.
For website owners, the Wikipedia case demonstrates that the actual distribution of internal links - not just their presence - determines the authority landscape of a site.
Google's Own Search Ranking Leak (2024): In May 2024, thousands of internal Google Search API documents were published by an anonymous source and verified by SEO researchers Rand Fishkin and Mike King.
The documents revealed internal attribute names in Google's ranking system, including references to "siteAuthority" as a concept, "clicks" data as a ranking input (contradicting public statements that clicks are not a direct ranking signal), and "NavBoost" as a system that adjusts rankings based on user interaction data.
Google's Danny Sullivan confirmed some aspects of the documents' authenticity while disputing others.
The leak, while incomplete and subject to interpretation, provided the most direct window into Google's actual engineering implementation of ranking that had ever been publicly available, and generated substantial debate about the gap between Google's public communications and internal engineering reality.
Key Metrics That Reveal How Search Engines Process Your Content
Several metrics provide measurable insight into how search engine mechanics are treating a specific site, offering actionable diagnostic information beyond basic traffic reports.
Crawl Stats Report (Google Search Console): Search Console's Crawl Stats report shows Googlebot's average daily crawl rate for a domain (requests per day), the distribution of response codes received, and the total data downloaded. This report reveals whether Googlebot considers a site important enough to crawl thoroughly.
A healthy established site should show a consistent crawl rate. A site experiencing a sudden drop in crawl rate - without a corresponding drop in content volume - may indicate that Googlebot has detected quality issues that have reduced its assessment of the site's crawl priority.
John Mueller noted in a 2022 office hours session that crawl rate is partly a function of how many pages Google thinks are worth crawling, making crawl rate an indirect signal of Google's quality assessment.
Index Coverage vs. Submitted Sitemap URLs: Comparing the count of indexed pages in Search Console with the count of URLs submitted in the sitemap provides a straightforward quality signal. Ahrefs' industry data suggests that for well-maintained content sites, indexed-to-submitted ratios above 80% are typical.
Ratios below 60% indicate that a significant proportion of content is failing Google's indexing quality threshold - which may be a signal affecting the treatment of other content on the same site.
Mueller has confirmed that the "crawled, currently not indexed" category reflects a quality-based decision rather than a capacity limitation.
Organic CTR vs. Position Benchmarks: Backlinko's analysis of 4 million Google search results (published in 2022, updated from their 2019 study) provides the most widely-cited CTR benchmarks by position: position 1 receives approximately 27.6% CTR, position 2 approximately 15.8%, position 3 approximately 11.0%.
Pages significantly below these benchmarks for their average position have title and meta description optimization opportunities. Google Search Console's Performance report enables this analysis: filtering by query, comparing average position to CTR for specific pages identifies the underperformers.
The implication is that understanding search engine result page presentation - how Google formats and presents results - is part of understanding how search engines work, not just a display consideration.
Keyword Cannibalization Detection: When multiple pages on a site compete for the same query, Google must choose which page to rank. The Search Console Performance report, analyzed by filtering for a specific query and comparing which pages appear in results, identifies cannibalization.
Ahrefs' 2022 study of large content sites found that keyword cannibalization affected 15-30% of content queries on sites that had been publishing for more than five years without systematic content auditing.
The mechanism - multiple pages splitting the authority signals that would otherwise concentrate on one page - is a direct consequence of how Google's indexing and ranking systems evaluate each URL independently before competing pages for the same query.
Sources & Further Reading
- Bush, Vannevar. "As We May Think." The Atlantic, July 1945. View source
- Page, Lawrence, Brin, Sergey, Motwani, Rajeev, and Winograd, Terry. "The PageRank Citation Ranking: Bringing Order to the Web." Stanford InfoLab, 1999.
- Google. "How Google Search Works." google.com. View source
- Google Search Central. "Introduction to Indexing." developers.google.com. View source
- Devlin, Jacob, Chang, Ming-Wei, Lee, Kenton, and Toutanova, Kristina. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." arXiv, 2018. View source
- Moz. "Google Algorithm Update History." moz.com. View source
- Internet Live Stats. "Google Search Statistics." internetlivestats.com. View source
- Ahrefs. "How Do Search Engines Work? Crawling, Indexing, and Ranking." ahrefs.com. View source
- Search Engine Land. "How Search Engines Work: Crawling, Indexing, and Ranking." searchengineland.com. View source
- Google Search Central. "Google's Helpful Content System." developers.google.com. View source
Frequently Asked Questions
What are the three main stages of how search engines work?
Search engines operate through three core stages: 1) Crawling: Automated bots (called crawlers or spiders) discover and visit web pages by following links from known pages. They continuously browse the web looking for new and updated content. 2) Indexing: The search engine processes and stores the content it finds during crawling. It analyzes the text, images, videos, and other content, extracting meaning and storing it in massive databases organized for quick retrieval. The index is like a giant library catalog of the web. 3) Ranking: When someone searches, the engine queries its index and ranks results based on hundreds of factors including relevance, quality, authority, and user experience. The goal is to return the most useful results for that specific query.These three stages happen continuously. Google crawls billions of pages, adds them to its index, and updates rankings in real-time. The entire process is designed to help users find the most relevant, trustworthy information as quickly as possible. Understanding these stages helps explain why some pages appear in search results and others don’t, and why rankings change over time as the search engine discovers new content or updates its understanding of what makes a page valuable.
How do search engine crawlers discover new pages on the web?
Crawlers discover new pages through several methods: Links from known pages: The primary discovery method. Crawlers follow links from pages they’ve already indexed to find new content. This is why backlinks matter, they’re pathways for discovery. Sitemaps: Website owners submit XML sitemaps listing all their pages, giving crawlers a direct map to content. This is especially important for new sites or pages not well-linked internally. Direct submission: Owners can manually submit URLs through tools like Google Search Console, requesting crawling of specific pages. Browser data: Search engines can learn about pages from Chrome browser data (with user permission) or other signals. Social signals: While debated, links shared on social platforms may help discovery even if they’re nofollow.The crawl budget concept: Search engines allocate limited resources to crawling each site. Popular, frequently-updated sites with good structure get crawled more often. Slow sites, sites with errors, or low-quality sites get crawled less. This is called “crawl budget.” To maximize discovery: create a clear site structure with internal links connecting all important pages; submit sitemaps; fix technical errors that block crawlers; improve site speed; and generate natural backlinks. Pages buried deep in your site structure or not linked from anywhere may never be discovered, even if they’re published. Think of crawlers as explorers following paths, if there’s no path to your page, they won’t find it.
What actually happens during the indexing process?
Indexing is where search engines make sense of the content they’ve crawled: 1) Content extraction: The engine parses the HTML, extracting text, identifying headings, images, videos, structured data, and metadata. It distinguishes actual content from navigation, ads, and boilerplate. 2) Language and meaning analysis: Natural language processing identifies the topic, main concepts, entities (people, places, organizations), and semantic relationships. The engine tries to understand what the page is truly about, not just which keywords it contains. 3) Quality signals: The engine evaluates hundreds of quality signals including content depth, expertise signals, user experience metrics, mobile-friendliness, page speed, and security (HTTPS). 4) Link analysis: It evaluates inbound and outbound links, assessing the page’s authority and topical relationships to other pages. 5) Duplicate detection: The engine identifies duplicate content across the web and determines canonical versions.The result: The page is stored in the index with extensive metadata about its content, quality, relationships, and relevance to potential queries. This isn’t just storage, it’s highly processed and organized data. When indexed, your page can appear in search results for relevant queries. Not all crawled pages get indexed: Low-quality pages, duplicates, blocked pages (robots.txt, noindex tags), or pages on untrusted sites may be crawled but not indexed. You can check if your pages are indexed by searching “site:yoursite.com” in Google. If important pages aren’t indexed, there’s usually a quality, technical, or crawling issue preventing it.
How do search engines determine which pages rank highest for a query?
Ranking involves analyzing hundreds of signals across several major categories: Relevance factors: Does the page content match the searcher’s intent? This goes beyond keyword matching to semantic understanding. Search engines analyze synonyms, related concepts, and context. They consider the query’s intent (informational, transactional, navigational) and favor pages that match that intent. Quality and authority signals: E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) matters significantly, especially for YMYL (Your Money Your Life) topics like health, finance, and legal content. Signals include author credentials, site reputation, backlink profile from authoritative sites, content depth and accuracy, and positive user engagement. User experience factors: Page speed, mobile-friendliness, Core Web Vitals (loading, interactivity, visual stability), HTTPS security, intrusive interstitial absence, and accessible design all influence rankings. Google prioritizes pages that provide smooth experiences.Link signals: While less dominant than 15 years ago, quality backlinks from relevant, authoritative sites remain important ranking factors, indicating trust and value. Freshness: For queries where timeliness matters (news, trends, recent events), recency is heavily weighted. For evergreen topics, it matters less. Personalization: Search engines customize results based on your location, search history, and preferences. Someone in New York may see different results than someone in London for the same query. The key insight: There’s no single ranking factor that dominates. Search engines use machine learning models trained on billions of queries to predict which results will satisfy users. The “best” page is the one that best matches the specific query intent while meeting quality and experience thresholds. This is why the same site might rank #1 for one query and not appear at all for a slightly different query, it’s all about relevance to that specific search intent.
Why do search results change so frequently even for the same query?
Search results are highly dynamic for several reasons: Continuous recrawling and reindexing: Search engines constantly recrawl pages, discovering updated content. When a page is updated with more comprehensive information or better optimization, its ranking can improve. Competitors updating their content can push your ranking down. Algorithm updates: Major search engines update their ranking algorithms regularly. Google makes thousands of small tweaks yearly and several major updates. These adjust how different ranking factors are weighted, sometimes causing significant ranking shifts. New content publication: Fresh content on a topic can outrank older content, especially for trending or time-sensitive queries. A new, comprehensive guide might quickly outrank older, thinner content. Link profile changes: As sites gain or lose backlinks, their authority and rankings shift. A page gaining high-quality backlinks will generally improve in rankings over time.User behavior signals: Search engines track how users interact with results. If many people click a result but quickly return to search (called “pogo-sticking”), it signals low satisfaction, potentially dropping that result’s ranking. Conversely, results with high click-through rates and engagement may rise. Personalization: Your individual results change based on your location, device, search history, and preferences. Someone else searching the same term sees different results. Query interpretation evolution: Search engines continuously refine how they interpret query intent. What Google thinks you mean by a query can shift as language usage evolves. Volatility by niche: Some topics (health, finance, news) see more frequent ranking changes due to their importance and Google’s heightened quality focus. Others are more stable. The reality: Search rankings are never truly “fixed.” The top result today could drop next week if competitors improve or algorithms change. This is why SEO requires ongoing effort, not one-time optimization.
What's the difference between how search engines worked 15 years ago versus today?
Search engines have evolved dramatically: Then (2010): Keyword-focused. Algorithms primarily matched exact keywords in content to queries. You could rank by repeating keywords many times (keyword stuffing). Link quantity mattered more than quality, sites bought thousands of low-quality links. Content quality was secondary to optimization tactics. Search was primarily text-based and desktop-focused. Results were less personalized. Now (2026): Intent and semantics-focused. Algorithms use natural language processing and machine learning to understand meaning, context, and user intent beyond exact keywords. They recognize synonyms, related concepts, and query intent (“best pizza” means local restaurants, not pizza recipes). Quality over quantity in everything, links, content depth, user experience. Mobile-first: Google indexes mobile versions preferentially. Page speed and mobile UX are critical ranking factors.User experience prioritized: Core Web Vitals (loading speed, interactivity, visual stability) directly impact rankings. Poor UX can prevent ranking even with great content. E-E-A-T emphasis: Expertise, Experience, Authoritativeness, and Trustworthiness are critical, especially for YMYL topics. Author credentials, site reputation, and content accuracy matter significantly. AI and machine learning: Systems like Google’s BERT, MUM, and RankBrain understand language nuance, handle conversational queries, and predict relevance far better than keyword matching ever could. Rich results: Search results now include featured snippets, knowledge panels, image carousels, video results, and structured data-driven rich results, not just 10 blue links. Voice and visual search: Engines optimize for voice queries (“near me” searches, questions) and image/visual searches.Personalization: Results heavily customized by location, device, search history, and user preferences. The shift: From gaming algorithms with tactics to genuinely serving users with valuable content and great experiences. The best SEO today is simply creating the best possible content and experience for your target audience. Manipulation tactics that worked 15 years ago now risk penalties. Search engines are far better at identifying and rewarding quality than they once were.
How can website owners help search engines understand and rank their content better?
Website owners can optimize for better search engine understanding: Technical foundations: Create XML sitemaps and submit them via Google Search Console. Implement clean URL structures. Use HTTPS. Ensure mobile-friendliness. Optimize page speed and Core Web Vitals. Fix crawl errors, broken links, and redirect chains. Create a logical site architecture with clear internal linking so crawlers can discover all important pages. Use robots.txt appropriately to guide (not block) crawlers. Structured data markup: Implement Schema.org structured data to explicitly tell search engines what your content represents, articles, products, recipes, events, FAQs, reviews, etc. This enables rich results and improves understanding. Content optimization: Write clear, descriptive title tags and meta descriptions. Use semantic HTML (H1, H2, proper heading hierarchy). Create comprehensive, in-depth content that thoroughly covers topics. Write for humans first, but be clear about your topic and include relevant terminology naturally. Answer related questions comprehensively.Semantic clarity: Use clear language. Define technical terms. Use synonyms and related concepts naturally. Structure content logically with headings, lists, and clear sections. Help both search engines and humans quickly understand what the page covers. E-E-A-T signals: Display author credentials for expertise-required topics. Include about pages, author bios, and editorial policies. Cite authoritative sources. Build backlinks from reputable, relevant sites in your industry. Demonstrate experience and expertise in your content. User experience: Fast loading, mobile-friendly, easy navigation, clear calls-to-action, no intrusive interstitials, accessible design. Search engines heavily weight how users experience your site. Fresh, maintained content: Keep important pages updated. Add new content regularly. Review and improve older content. Remove or redirect outdated pages.Monitoring and iteration: Use Google Search Console to see how Google views your site, identify issues, and understand which queries drive traffic. Monitor rankings and adjust strategy based on performance. The philosophy: Help search engines do their job. Make your content easy to discover, understand, and verify as high-quality. The less ambiguity about what your page is about and why it’s valuable, the better search engines can match it to relevant queries. Most “SEO” is just making great content discoverable and accessible.