Andy Grove, the first employee and later CEO of Intel, had a phrase he repeated so often it became company doctrine: "Only the paranoid survive." But his less quoted and more actionable insight was this: "Execution is the only strategy that matters." Grove believed that the difference between Intel and its competitors was not superior vision but superior execution - the systematic ability to turn decisions into results, week after week, quarter after quarter.
Most projects fail not because the plan was wrong but because execution broke down. The plan existed. People agreed with it. Resources were allocated. And then nothing happened - or the wrong things happened, or things happened too slowly, or coordination fell apart.
Execution systems are the mechanisms that prevent this drift from intention to inaction.
"Execution is the only strategy that matters. Vision is common. Plans are common. The ability to execute consistently, week after week, is the rare capability." - Andy Grove
| Component | What It Answers | Key Failure Mode | Example Practice |
|---|---|---|---|
| Work breakdown | What specifically needs to be done? | Tasks too vague to act on | "Profile slowest 3 DB queries" not "improve performance" |
| Ownership model | Who is accountable for each item? | Shared ownership meaning no one is responsible | One named person per task; RACI for complex work |
| Cadence | Are we on track and what is blocking? | No regular rhythm; problems surface too late | Daily standups; weekly reviews; milestone check-ins |
| Progress visibility | How far along is the project really? | Status is "good" until it is suddenly "in crisis" | Objective metrics; task completion rates; burn-down charts |
What Execution Systems Actually Do
An execution system is the collection of practices, rhythms, and tools that answer five questions continuously throughout a project:
- What needs to be done? (Clarity of tasks and priorities)
- Who is doing it? (Clear ownership and accountability)
- When is it due? (Deadlines and milestones)
- What is blocking progress? (Visibility into obstacles)
- Are we on track? (Progress measurement and course correction)
If answering any of these questions requires hunting through multiple tools, lengthy meetings, or interpretation of ambiguous information, the execution system is failing.
Example: Amazon operates one of the most disciplined execution systems in corporate history. Their "six-pager" meeting format (detailed written narratives read silently at the start of meetings, followed by discussion) ensures that every meeting begins with shared understanding of the current state.
Their "working backwards" process (writing the press release before building the product) ensures that execution is always anchored to a clear definition of what success looks like.
These are not bureaucratic rituals - they are execution mechanisms that enable a $1.5 trillion company to move with startup speed.
The Anatomy of an Effective Execution System
Component 1: The Work Breakdown
Every initiative must be decomposed into tasks that are:
- Specific: "Draft API endpoint documentation for user authentication module" not "work on docs"
- Assignable: One person owns each task (shared ownership is no ownership)
- Estimable: The team can roughly gauge the effort required
- Testable: There is a clear definition of "done"
The common failure: Tasks that are too vague to act on. "Improve performance" is a goal, not a task. "Profile database queries on the orders page and identify the three slowest" is a task.
Component 2: The Ownership Model
For every task, there must be exactly one person accountable for its completion. Not a team. Not a committee. One name.
The RACI framework (Responsible, Accountable, Consulted, Informed) provides useful structure:
- Responsible: The person doing the work
- Accountable: The person who answers for the outcome (often the same as Responsible for small teams)
- Consulted: People whose input is needed before the work is done
- Informed: People who need to know about the outcome but are not involved in doing the work
Example: At Bridgewater Associates, the world's largest hedge fund, founder Ray Dalio instituted a practice of "responsible parties" for every decision and action item. Meeting notes always included specific names next to specific commitments.
Dalio's principle: "If you can't identify who is responsible for something, it won't get done."
Component 3: The Cadence
Execution systems need rhythm - regular checkpoints that maintain alignment and surface problems before they become crises.
Daily rhythm (5-15 minutes):
- What did you complete since yesterday?
- What will you work on today?
- What is blocking you?
This is the standard standup format, but the specific format matters less than the consistency. The goal is maintaining shared awareness without lengthy meetings.
Weekly rhythm (30-60 minutes):
- Progress against weekly commitments
- Blockers requiring escalation
- Priorities for the coming week
- Any scope or priority changes
Sprint/milestone rhythm (1-4 weeks):
- Demo of completed work
- Retrospective on what went well and what did not
- Planning for the next sprint or milestone
Monthly/quarterly rhythm:
- Progress against strategic goals
- Resource allocation adjustments
- Risk assessment and mitigation review
Component 4: The Visibility System
If the status of work is not visible without asking, the execution system is broken.
Effective visibility requires:
- A shared tracking tool (Asana, Jira, Linear, Notion, or even a shared spreadsheet) where task status is current
- A dashboard or summary view that shows overall project health at a glance
- Automated status updates where possible (integration between tools reduces manual reporting)
The anti-pattern: Status reports that require manual compilation, taking hours to produce and being outdated by the time they are read. Effective execution systems generate status visibility as a byproduct of doing the work, not as a separate reporting exercise.
Component 5: The Blocker Resolution Process
Every execution system needs a mechanism for rapidly resolving obstacles:
- Immediate escalation: When a blocker is identified, it is visible to people who can help within hours, not days
- Time-boxed resolution: "If we do not have a decision on X by Wednesday, we proceed with option A"
- Swarming: When critical work is blocked, temporarily reallocate people to unblock it rather than having the blocked person wait
Example: Toyota's famous "Andon cord" system allows any worker on the assembly line to stop production when they detect a quality problem.
This is an execution system mechanism: it gives frontline workers the authority and the mechanism to surface blockers immediately rather than letting defects propagate. The short-term cost (stopped production) prevents the long-term cost (defective products).
Execution Systems for Different Contexts
Co-Located Teams
Co-located teams have natural communication channels - overhearing conversations, seeing body language, quick desk-side questions. Execution systems can be lighter:
- Physical task boards (sticky notes, whiteboard)
- Brief daily standups (literally standing up)
- Quick desk-side conversations for blocker resolution
- Minimal formal documentation (shared understanding built through proximity)
Distributed and Remote Teams
Remote teams lack ambient awareness, making explicit execution systems essential. For guidance on remote communication, see async communication explained.
- Async standup updates in a shared channel (written daily updates replacing synchronous meetings)
- Comprehensive shared tracking (digital task boards that everyone maintains)
- Written decisions and context (what would be communicated verbally in an office must be documented)
- Explicit handoffs between time zones (documenting what is complete, what is next, what is blocked)
- Regular video calls for relationship building and complex discussions that do not work async
Example: GitLab, with over 2,000 employees across 65+ countries, operates with an explicit "handbook-first" approach where all processes, decisions, and context are documented in their publicly available handbook. Their execution system is designed for a world where no two team members may ever be online simultaneously.
Small Teams (3-5 People)
Lightweight execution is sufficient:
- A shared task list or simple board
- Brief daily check-in (5 minutes, possibly async)
- Weekly planning session
- Informal blocker resolution through direct conversation
Large Teams (20+ People)
Coordination complexity requires more formal systems:
- Structured project management tool with defined workflows
- Formal sprint planning with capacity management
- Designated scrum masters or project managers facilitating execution
- Cross-team coordination meetings for managing dependencies
- Documented escalation paths for blockers
Building Accountability Without Micromanagement
The tension between accountability and autonomy is central to execution system design.
What Accountability Looks Like
- People commit to specific deliverables with specific deadlines
- Commitments are visible to the team
- Progress is reviewed regularly
- Missed commitments trigger honest conversation about what happened and how to prevent recurrence
- Adjusted commitments (when circumstances change) are communicated proactively, not discovered at the deadline
What Micromanagement Looks Like
- Managers dictate how tasks should be performed, not just what should be delivered
- Frequent status checks ("are you done yet?") replacing visible tracking
- Approval required for routine decisions within the team's competence
- Detailed time tracking to monitor activity rather than outcomes
- Punishment for missed commitments rather than problem-solving
The boundary: Accountability is about what gets delivered and when. Autonomy is about how the work gets done. Good execution systems maintain accountability while preserving autonomy.
Example: Netflix famously articulated this principle in their culture document: "We lead with context, not control." Teams are given clear goals and context, then trusted to determine how to achieve them. Accountability is maintained through results, not surveillance.
Maintaining Momentum When Work Is Blocked
Blockers are inevitable. How the execution system handles them determines whether delays cascade or get contained.
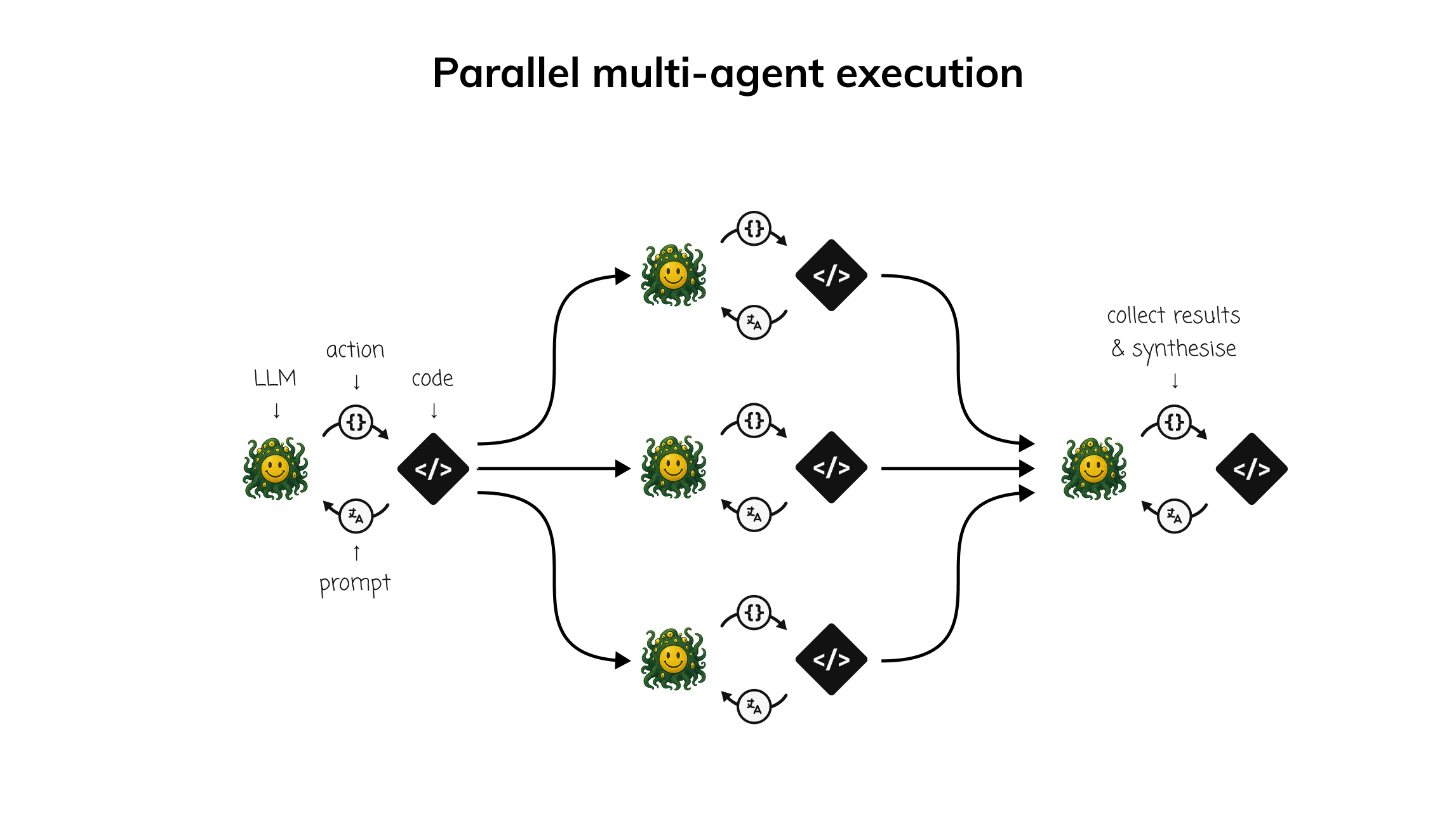
Parallel Work Streams
Structure projects so multiple efforts can progress simultaneously. When one stream is blocked, people shift to another rather than sitting idle.
The Ready Backlog
Maintain a prioritized list of "ready" work - tasks that are fully specified, have no dependencies, and can be started immediately. When primary work is blocked, people pull from the ready backlog.
Time-Boxed Escalation
Set explicit deadlines for blocker resolution: "If this dependency is not resolved by Thursday, we proceed with the workaround." This prevents blockers from becoming indefinite waits.
Temporary Workarounds
When the ideal solution is blocked, implementing a temporary alternative that unblocks downstream work is often preferable to waiting. The cost of delay frequently exceeds the cost of rework.
Signs Your Execution System Needs Change
Slowing velocity despite consistent effort: If the team feels busy but delivery is declining, the system may be creating overhead.
Growing "we didn't know about that" surprises: Information is not flowing through the system as intended.
Meeting proliferation: If you keep adding coordination meetings to compensate for execution system failures, the system itself is the problem.
Different team members maintaining separate tracking: When people keep private lists because the official system does not work for them, the system is not serving diverse needs.
Tracking debt: If the project dashboard is days or weeks outdated, people have stopped maintaining it because it is too burdensome or provides insufficient value.
Declining morale: If the execution system feels like bureaucratic overhead rather than helpful structure, it is time to simplify.
For monitoring these signals with appropriate metrics, see KPIs explained without buzzwords.
OKRs, KPIs, and Other Measurement Frameworks Within Execution Systems
Execution systems need measurement to function, but the wrong measurements create perverse incentives that undermine the system.
OKRs (Objectives and Key Results)
Popularized by John Doerr at Intel under Andy Grove and later adopted by Google, OKRs connect execution to strategy by defining:
- Objectives: Qualitative descriptions of what you want to achieve ("Become the leading provider of enterprise analytics")
- Key Results: Quantitative measures that indicate progress ("Increase enterprise customer count from 50 to 200," "Achieve 99.99% uptime," "Reduce onboarding time from 14 days to 3 days")
The execution system role: OKRs define what the team is working toward. The execution system manages how the daily and weekly work connects to those objectives. Without an execution system, OKRs become aspirational statements posted on a wall and ignored.
Without OKRs (or similar strategic alignment), the execution system optimizes for busyness rather than impact.
Example: Google has used OKRs since 1999, when John Doerr introduced them to Larry Page and Sergey Brin. Each quarter, every team sets OKRs that cascade from company-level objectives. The critical discipline: OKRs are graded publicly at the end of each quarter, creating accountability.
A team that consistently achieves 100% of its OKRs is setting them too conservatively - Google expects 60-70% achievement on "stretch" key results.
Velocity and Throughput
For teams using Agile frameworks:
- Velocity measures story points (or similar units) completed per sprint. It is useful for estimating capacity and detecting trends but dangerous as a performance metric (teams will inflate story point estimates to appear more productive).
- Throughput measures the number of work items completed per time period. Simpler and harder to game than velocity.
- Cycle time measures the average duration from starting a work item to completing it. The most actionable metric for process improvement.
The measurement trap: When execution metrics become performance targets, teams optimize for the metrics rather than for outcomes. Story points completed rises while actual customer value delivered stays flat or declines. This is Goodhart's Law in action: "When a measure becomes a target, it ceases to be a good measure."
For deeper treatment of project measurement, see project metrics explained.
Scaling Execution Systems Across Multiple Teams
When an organization runs multiple teams working on related projects, individual team execution systems must connect into a broader coordination framework.
The Program Level
A program coordinates multiple related projects toward a shared outcome. Program-level execution requires:
- Cross-team dependency management: Which teams are waiting on which other teams? Where are the handoff points? What happens if one team is late?
- Integration cadence: Regular points where separate team outputs are combined and tested together. The longer between integration points, the higher the risk of integration failure.
- Shared milestone tracking: Program milestones that all teams contribute to, creating shared accountability.
Example: Amazon manages cross-team execution through their "two-pizza team" structure (teams small enough to be fed by two pizzas, typically 6-10 people) combined with well-defined API contracts between teams. Each team owns a service and publishes an interface.
Other teams depend on the interface, not the implementation. This architecture enables independent execution while maintaining system coherence.
When Werner Vogels, Amazon's CTO, describes their architecture, he emphasizes that the organizational structure and the technical architecture mirror each other - small, autonomous teams owning small, autonomous services.
Coordination Without Bureaucracy
The temptation when scaling execution is to add coordination roles, meetings, and processes. Each addition is individually reasonable. Collectively, they create a coordination layer so heavy that teams spend more time in alignment meetings than doing work.
The principle: Minimize coordination by maximizing team autonomy. Give teams clear objectives and well-defined interfaces (what they consume and produce). Let them self-organize their internal execution. Coordinate only at the interfaces.
Coordination meetings should be:
- As infrequent as possible while maintaining alignment (weekly or bi-weekly at program level)
- Focused on dependencies and blockers, not status reporting (status should be visible in tools)
- Time-boxed (30 minutes maximum for most coordination meetings)
- Attended by representatives, not entire teams
The Inverse Conway Maneuver
Conway's Law states that organizations design systems that mirror their communication structures. The Inverse Conway Maneuver deliberately structures teams to produce the system architecture you want. If you want microservices, organize into small, autonomous teams.
If you want a tightly integrated product, organize into cross-functional teams with shared ownership.
This matters for execution systems because the execution system must match the organizational structure. An execution system designed for a single integrated team will not work for autonomous squads, and vice versa.
Execution Systems for Creative and Knowledge Work
Not all work fits neatly into the sprint-based, ticket-driven execution systems common in software engineering. Creative work, research, strategy development, and other knowledge-intensive activities require adapted approaches.
The Challenge
Creative work is inherently uncertain. You cannot estimate how long it takes to write a compelling strategy document, design an innovative user experience, or develop a research breakthrough. Traditional execution metrics (velocity, throughput, cycle time) either do not apply or create harmful pressure to rush creative processes.
Adapted Execution Principles
1. Time-box exploration, not outcomes. Instead of "deliver the strategy document by Friday," use "spend 8 hours this week on strategy exploration, and share what you have learned." The exploration may reveal that the strategy needs another week of thinking, or it may produce a finished document - both are valid outcomes.
2. Use intermediate artifacts as progress indicators. A research project may not have deliverables for weeks, but it should produce intermediate artifacts: literature summaries, hypothesis lists, data collection plans, preliminary analyses. These artifacts demonstrate progress and create opportunities for course correction.
3. Maintain creative autonomy within structural accountability. The creator decides how to approach the work. The execution system tracks whether they are making progress and surfacing that progress to stakeholders.
Example: Pixar's "Braintrust" meetings, described by Ed Catmull in Creativity, Inc., function as an execution system for creative work. Directors present their films-in-progress to a group of senior creative leaders who provide candid feedback.
The meetings are regularly scheduled (execution cadence), feedback is specific and actionable (blocker resolution), and the director retains final authority over decisions (ownership model). The Braintrust does not mandate changes - it surfaces problems. The director decides how to address them.
What Research Shows About Execution Effectiveness
The gap between organizational intent and organizational execution is one of the most extensively documented phenomena in management research.
Paul Niven and Ben Lamorte, who analyzed OKR implementation across 200 organizations from 2015 to 2020, found that fewer than 10 percent of organizations successfully execute their stated strategies.
The primary failure mechanism was not strategy quality but execution system quality: organizations could articulate clear objectives but lacked the mechanisms to translate them into coordinated daily action.
Chris McChesney, Sean Covey, and Jim Huling at FranklinCovey studied execution effectiveness across 300,000 team members in 1,500 organizations over four years, publishing their findings in The 4 Disciplines of Execution (2012).
Their research found that 87 percent of team members did not know what their organization's top priorities were, and that 81 percent could not articulate how their weekly work connected to organizational goals.
Teams with formal execution systems - defined as regular accountability meetings, visible scoreboards tracking leading measures, and explicit commitment protocols - outperformed teams without them by an average of 52 percent on goal achievement. The effect was consistent across industries, organization sizes, and stated strategy types.
Eliyahu Goldratt's Theory of Constraints, developed through his research with manufacturing organizations in the 1980s and documented in The Goal (1984), provides the theoretical foundation for blocker-resolution components of execution systems.
Goldratt found that every system has a single binding constraint at any given time - the resource, process, or dependency that limits overall throughput.
Organizations that focused improvement efforts on the constraint improved total output regardless of where the effort was applied; organizations that improved non-constraint elements achieved no overall improvement.
The practical implication for execution systems is that identifying and resolving the current blocker is more valuable than improving the performance of non-blocked work streams.
Goldratt's research at Hitachi Tool Engineering documented a 25 percent productivity increase over six months from applying constraint identification systematically to a manufacturing execution process.
Amy Edmondson of Harvard Business School, whose research on psychological safety was originally published in Administrative Science Quarterly in 1999 and extended through multiple subsequent studies, found a counterintuitive result in her hospital team research: the teams that reported the highest rates of medication errors were the highest-performing teams, not the lowest.
The explanation was that high-performing teams with strong psychological safety surfaced errors for discussion, while lower-performing teams concealed them to avoid blame.
The connection to execution systems is direct: an execution system that does not surface blockers, problems, and failures for resolution is not functioning.
Edmondson's research, extended to project teams in Teaming (2012), found that teams with regular structured blocker-resolution processes resolved problems 60 percent faster than teams relying on ad hoc escalation.
McKinsey's organizational practice analyzed 1,027 companies across 100 countries from 2010 to 2018 and found that organizational health - defined as the ability to align, execute, and renew faster than competitors - predicted five-year financial performance better than any other single factor, including industry position, market share, or technology advantage.
Execution system quality was the second-strongest predictor of organizational health within this framework, after leadership quality.
Companies in the top quartile of execution system maturity generated total returns to shareholders 3.2 times higher than companies in the bottom quartile over the same period.
Case Studies in Execution System Design
Organizations that have invested deliberately in execution system design provide instructive examples of both successful and unsuccessful approaches.
Intel's OKR implementation, introduced by Andy Grove in the 1970s and documented in Grove's High Output Management (1983), represents one of the most thoroughly studied execution system designs in corporate history.
Grove's system linked quarterly objectives (directional goals) with key results (measurable outcomes) and required weekly one-on-one meetings between managers and direct reports in which commitments were reviewed against the previous week's key results.
Intel's semiconductor market leadership from 1975 to 2000 was attributed in part to this execution discipline: the company could identify performance problems within weeks rather than quarters and redirect resources before problems became strategic failures.
John Doerr, who introduced OKRs to Google after working at Intel, documented in Measure What Matters (2018) that Google's early adoption of OKRs in 1999 was directly responsible for the company's ability to scale from 30 to 60,000 employees while maintaining execution coherence.
Doerr cited Google's 10x growth in revenue per employee from 2000 to 2010 as evidence of the system's leverage.
Toyota's production system, analyzed extensively by Jeffrey Liker in The Toyota Way (2004) and by researchers at the MIT Center for Transportation and Logistics, represents the most thoroughly documented application of execution system principles in manufacturing.
Toyota's system - encompassing the Andon cord blocker escalation mechanism, standardized work procedures, and visual management boards - reduced defect rates from an industry average of 4-5 defects per 100 vehicles in the 1970s to 1.2 defects per 100 vehicles by 1995, while also reducing production costs by 28 percent over the same period.
James Womack, Daniel Jones, and Daniel Roos documented these outcomes in The Machine That Changed the World (1990), based on a five-year MIT study of automotive plants across the US, Japan, and Europe.
The Toyota plants in their study outperformed the best non-Toyota plants by 2:1 on productivity and 2:1 on defect rates, with the execution system - not technology or workforce skill - as the primary differentiating factor identified by the researchers.
Spotify's engineering execution system, documented by Henrik Kniberg in his 2012 whitepaper and updated through subsequent blog posts on the Spotify Engineering blog, organized execution around autonomous squads with full stack ownership.
Each squad maintained a physical or digital board visible to the entire squad showing work in progress, committed work for the current iteration, and the squad's current quarterly objective.
Spotify's engineering blog documented that squads using this visible execution approach shipped features 40 percent more frequently than squads using informal tracking, and that the time from feature commitment to production deployment fell from an average of 6 weeks to 1.5 weeks over the three years following the system's introduction.
The outcomes were not uniformly positive: squads that lacked experienced engineering leadership struggled with the autonomous model, and Spotify's subsequent organizational evolution acknowledged that the 2012 system captured a specific stage of the company's development rather than a universally applicable template.
The US Digital Service's execution system, developed from 2014 onward and documented through their annual reports and case studies published on usds.gov, applied agile execution principles to government technology projects that had historically produced catastrophic outcomes.
The USDS playbook, published in 2014, specified execution practices including daily standups, two-week deployment cycles, and measurable success criteria defined before work began.
Comparing government IT projects that followed USDS execution practices to those that did not, the Government Accountability Office found in a 2018 report that USDS-methodology projects were 75 percent more likely to complete within 10 percent of original budget estimates.
The most cited case is the rescue of Healthcare.gov following its 2013 launch failure: a USDS team of 60 people, applying disciplined execution practices, stabilized the platform in six weeks that had resisted 300 contractors over two years.
The Execution System Paradox
The paradox of execution systems is this: the more effective the system, the less you notice it. A well-functioning execution system feels like common sense - of course we know what to work on, of course blockers get resolved quickly, of course everyone knows the project status.
When execution systems are absent or broken, the symptoms are obvious: confusion, duplication, surprises, and heroic individual effort compensating for systemic failure.
The investment in building a good execution system pays returns on every single task, every single day, for the life of the project. Few investments in project management offer comparable leverage.
Sources & Further Reading
Grove, A. S. "High Output Management." Vintage Books, 1983.
Grove, A. S. "Only the Paranoid Survive." Currency Doubleday, 1996.
Dalio, R. "Principles: Life and Work." Simon & Schuster, 2017.
Bryar, C. & Carr, B. "Working Backwards: Insights, Stories, and Secrets from Inside Amazon." St. Martin's Press, 2021.
Hastings, R. & Meyer, E. "No Rules Rules: Netflix and the Culture of Reinvention." Penguin Press, 2020.
Liker, J. K. "The Toyota Way: 14 Management Principles from the World's Greatest Manufacturer." McGraw-Hill, 2004.
GitLab. "GitLab Handbook." GitLab, 2024. View source
McChesney, C., Covey, S., & Huling, J. "The 4 Disciplines of Execution." Free Press, 2012.
Doerr, J. "Measure What Matters: How Google, Bono, and the Gates Foundation Rock the World with OKRs." Portfolio, 2018.
Goldratt, E. M. "The Goal: A Process of Ongoing Improvement." North River Press, 1984.
Frequently Asked Questions
What makes an execution system effective versus just busy work?
Effective execution systems create clarity, accountability, and momentum while minimizing overhead. The key distinction is whether the system serves execution or becomes a substitute for it. Effective systems answer critical questions quickly: What needs to be done? Who’s doing it? When is it due? What’s blocking progress? If your system requires hunting through multiple tools, lengthy meetings, or interpretation to answer these questions, it’s failing. Good execution systems have clear next actions: every work item has specific, actionable tasks with owners and deadlines, not vague aspirations like ‘improve performance.’ They make dependencies visible: if task B depends on task A, that relationship is explicit and tracked, preventing surprises. They surface blockers immediately: when someone encounters an obstacle, it’s visible to people who can help remove it, not buried in status reports. Effective systems create appropriate rhythm: regular checkpoints (daily standups, sprint planning, milestone reviews) that maintain coordination without excessive meetings. They track the right metrics: measures that actually indicate progress and health, not vanity metrics that look good but don’t inform decisions. Good systems scale with the team: a 3-person team can coordinate informally; a 20-person team needs more structure, but both need systems appropriate to their size. They adapt: as projects evolve, the execution system evolves too rather than rigidly following initial processes that no longer fit. Critically, effective systems reduce cognitive load: people know where to find information, what’s expected of them, and how decisions get made without constantly figuring out the meta-work of how to work. The test is whether the system accelerates delivery or creates overhead: if you spend more time updating trackers, attending coordination meetings, and documenting process than actually doing the work, your system is the problem.
How do you build accountability into execution without micromanagement?
Building accountability without micromanagement requires clear expectations, visibility, and ownership while trusting people to execute autonomously. Start with clear commitments: people commit to specific deliverables with specific deadlines, not vague ‘I’ll work on X.’ Commitments should be meaningful units of completion, not just time spent. Make work visible through shared tracking: task boards, project dashboards, or simple shared documents where everyone can see who owns what and current status. Visibility creates natural accountability without managers needing to ask for updates. Implement regular check-ins with consistent format: daily standups where everyone shares progress, plans, and blockers keep accountability current without intensive oversight. The format creates expectation of reporting without shame or blame. Define done clearly: ambiguity about completion criteria enables people to claim done when they’re not, so establish specific acceptance criteria upfront. Establish consequences for missed commitments that are firm but fair: if someone misses a deadline without communication, there’s a conversation about what happened and how to prevent recurrence, not punishment, but acknowledgment that commitments matter. Conversely, normalize adjusting commitments when circumstances change: if scope expands or dependencies shift, updating commitments isn’t failure, it’s responsible management. Empower autonomy within boundaries: people choose how they accomplish their commitments but are accountable for results. Micromanagement is telling people how to do every task; accountability is expecting them to deliver on what they committed to. Create peer accountability: teams that review each other’s work or depend on each other’s deliverables create accountability beyond just manager-employee relationships. Celebrate successful delivery: acknowledging when people complete commitments reinforces that accountability works both ways, commitment is taken seriously and delivery is recognized. The balance is having enough structure that accountability is clear but enough autonomy that people own their work rather than just executing orders.
What execution systems work best for remote or distributed teams?
Remote execution systems must compensate for lack of physical presence through async communication, clear documentation, and deliberate coordination. Async-first communication is essential: don’t assume you can tap someone on the shoulder; use tools like Slack, wiki pages, or video recordings so people can catch up on their schedule across time zones. Comprehensive documentation becomes non-negotiable: decisions, context, and status must be written down because you can’t rely on overhearing conversations or reading body language. Shared visibility tools are critical: project tracking tools (Jira, Asana, Trello) where everyone can see current state without asking, supplemented by dashboards or automated status reports. Over-communicate status: what might be obvious in co-located teams needs explicit communication remotely. Use written daily updates or async standups where everyone shares progress, plans, and blockers in a shared channel. Time-boxed synchronous collaboration for critical coordination: despite async-first approach, some work benefits from real-time discussion. Schedule regular video calls for planning, problem-solving, or relationship-building, but make them focused and valuable. Clear working agreements about response times and availability: remote doesn’t mean always-on, but teams need agreements about when people are available and how quickly to respond to different communication types. Explicit handoffs between team members or time zones: document what’s complete, what’s next, and what blockers exist when passing work between people who aren’t online simultaneously. Trust-based flexibility: remote execution requires trusting people to manage their own time and deliver results rather than monitoring hours worked. Rich, accessible documentation: centralized wikis or knowledge bases where information lives and can be found easily, not scattered across email threads. Proactive blocker resolution: when someone encounters obstacles, raise them immediately and explicitly rather than hoping to catch someone online. The key insight is that remote execution requires making implicit coordination explicit and replacing synchronous coordination with well-structured async processes, but without making everything so process-heavy that velocity suffers.
How do you maintain execution momentum when work is blocked or delayed?
Maintaining momentum despite blockers requires having alternative work ready, proactively unblocking others, and preventing local delays from spreading. Keep parallel work streams: structure projects so multiple efforts can progress simultaneously, meaning one blocked task doesn’t stop everything. When someone hits a blocker, they should have clarity on what else they can work on rather than waiting idle. Maintain a prioritized backlog of ready work: when primary work is blocked, people pull next-priority items that aren’t blocked. This requires keeping some work prepared ahead: requirements clarified, dependencies secured, resources allocated. Escalate blockers immediately: when someone encounters an obstacle, make it visible immediately and escalate to whoever can resolve it. Don’t let blockers languish for days before action. Time-box blocker resolution: ‘If we don’t have decision on X by Wednesday, we’ll proceed with option A’, don’t let blockers become indefinite waits. Use temporary workarounds: when ideal solution is blocked, implement temporary approach that unblocks downstream work even if you’ll need to refactor later. The cost of delay often exceeds the cost of rework. Swarm blockers: when critical work is blocked, temporarily reallocate people to unblock it rather than having blocked person wait while others continue separate work. This is especially valuable near milestones or for work blocking multiple streams. Build slack into plans: if every task is on critical path with zero buffer, any delay cascades catastrophically. Having some buffer and non-critical work creates flexibility. Use blocked time for improvement work: if someone can’t progress their primary task, have them work on technical debt, documentation, or process improvements, work that’s valuable but not time-critical. Proactively identify dependencies and secure them early: don’t wait until you need something to request it; identify dependencies during planning and get commitments upfront. Finally, distinguish between blockers you can control versus external delays: for external delays (vendor delivery, third-party approval), have contingency plans ready to activate.
What are signs that your execution system needs to change?
Several signals indicate your execution system is no longer serving your needs. Slowing velocity despite consistent effort suggests the system is creating overhead: if teams feel busy but delivery is declining, process overhead may be consuming productive time. Increasing coordination failures, duplicated work, integration problems, or people working at cross-purposes, indicate the system isn’t maintaining alignment. Growing tracking debt where status tracking falls behind reality: if your project dashboard is days or weeks outdated, people have stopped maintaining it because it’s too burdensome or doesn’t provide value. Frequent ‘We didn’t know about that’ surprises mean information isn’t flowing through the system as intended. Meeting proliferation: if you’re adding more coordination meetings to compensate for system failures, the system itself is the problem. Complaints from team members about process burden or busy work signal the system is interfering with execution. Different team members maintaining separate tracking systems because the official one doesn’t work for them shows the system isn’t serving diverse needs. Decisions getting delayed or lost because accountability and escalation paths aren’t clear. Difficulty onboarding new people: if it takes weeks for new team members to understand how work gets done, your system is too complex or poorly documented. Resistance to using the system: if people avoid updating trackers, skip standups, or work around official processes, they’re telling you the system isn’t working. Bottlenecks around specific people or processes indicate system design problems. Finally, the system might be fine but the context changed: what worked for a 5-person co-located team won’t work for a 20-person distributed team; what worked for predictable maintenance work won’t work for uncertain innovation work. Regularly assess whether your execution system still fits your team size, project type, and organizational context. The solution might be simplifying an overly complex system, adding structure to an insufficiently clear one, or adapting to changed circumstances.