A data scientist is a professional who uses statistical analysis, machine learning, and programming to extract insights and build predictive models from structured and unstructured data - combining expertise in mathematics, computer science, and domain knowledge to help organizations make better decisions.
The role was famously called "the sexiest job of the 21st century" by Thomas Davenport and DJ Patil in Harvard Business Review in 2012, and the title stuck - but the reality behind it is far messier, more interesting, and more varied than the hype suggested.
Over the decade that followed that headline, companies scrambled to hire data scientists, universities launched hundreds of dedicated programs, and bootcamps promised six-figure salaries to anyone who could learn Python and statistics.
What the hype obscured was a more grounded reality: data scientists spend most of their time cleaning data, arguing about definitions with stakeholders, and building models that turn out to be less accurate than a simple heuristic.
The gap between the glamour of the title and the texture of the daily work is significant, and understanding it honestly is the starting point for anyone seriously considering the career.
This article provides the complete, honest picture: what data scientists actually do day-to-day, the technical and soft skills required, salary ranges by level and country with sources, how the role relates to adjacent positions like data analyst and machine learning engineer, and the career path from junior to principal level.
If you are deciding whether to pursue this path or trying to understand what you are actually hiring for, the information here draws on industry surveys, compensation data, and the experiences of practitioners across company sizes and sectors.
"The ability to take data - to be able to understand it, to process it, to extract value from it, to visualise it, to communicate it - that's going to be a hugely important capability in the next decades." - Hal Varian, Chief Economist at Google, 2009
Key Definitions
Data science is the interdisciplinary field combining statistics, computer science, and domain knowledge to extract insights and build predictive models from structured and unstructured data.
The term was popularized in the 2000s, though the underlying practices draw on decades of work in statistics, operations research, and computer science.
Machine learning (ML) is a subset of artificial intelligence in which models learn patterns from data rather than being explicitly programmed with rules. Most ML work in industry involves supervised learning - training models on labeled examples to predict outcomes on new data.
Feature engineering is the process of selecting and transforming raw data variables into inputs that improve model performance. Often the most impactful and time-consuming part of building a useful model, and the area where domain knowledge matters most.
Data pipeline is the automated system that moves data from source to storage to analysis or model serving. Data scientists often build or depend heavily on data pipelines maintained by data engineers.
A/B testing is a controlled experiment in which two versions of a product or intervention are shown to random user subgroups to measure the causal effect of a change. Statistical rigor in A/B testing is a core data science skill in product-driven companies.
ETL (Extract, Transform, Load) refers to the process of pulling data from source systems, transforming it into a usable format, and loading it into a data warehouse or analytics environment.
What a Data Scientist Does: The Real Day-to-Day
The most honest description of a data scientist's day is: more time wrangling messy data than training models, more time in meetings than running code, and more time explaining results than generating them.
A 2020 survey by Anaconda of 2,360 data professionals found that respondents spent 45% of their time on data preparation tasks - locating data, cleaning it, and transforming it into usable form. Only 19% of time went to model building and training.
The 2023 Kaggle State of Machine Learning survey of over 10,000 respondents confirmed similar proportions, with data cleaning and exploration consuming the largest share of working hours.
This ratio surprises people entering the field from coursework, where clean, well-structured datasets are provided and the interesting part begins immediately.
A Typical Day at a Mid-Size Tech Company
The morning often begins with checking whether any overnight jobs failed. Data pipelines break regularly - databases time out, upstream data schemas change without notice, scheduled jobs run out of memory, and vendor APIs return unexpected formats.
A data scientist who owns production models or dashboards spends real time on monitoring and maintenance that never appears in job descriptions.
By mid-morning, the work might shift to a current project: perhaps building a churn prediction model for the customer success team.
This means querying the data warehouse (using SQL) to pull a training dataset, examining the distribution of the target variable, engineering features from raw event logs, and running initial model experiments in a Jupyter notebook.
The first model will almost certainly not be the last - iteration is the core loop. You might try logistic regression as a baseline, then gradient-boosted trees, then spend an hour investigating why the model performs poorly on a specific customer segment and discovering that the underlying data has a labeling error.
Afternoons frequently involve meetings. A data scientist in a product-embedded role might attend sprint planning, a stakeholder review of recent A/B test results, or a cross-functional discussion about what metrics to track for an upcoming feature launch.
Communication skills matter enormously: the ability to explain a confidence interval, or why a model performs well on average but poorly in a specific segment, to a non-technical audience is what separates scientists who create impact from those who produce reports nobody reads.
Late in the day, there may be code review - examining a colleague's analysis for statistical errors, or verifying whether the logic in a data pipeline matches the business definition of a metric.
Senior data scientists mentor junior colleagues, review their work, and are expected to catch subtle errors in methodology that could lead to incorrect business decisions.
What Varies by Company Type
| Company Type | Typical Focus | Infrastructure Maturity | Breadth vs Depth | Project Cycle |
|---|---|---|---|---|
| Large tech (Google, Meta, Spotify) | Experiment design, causal inference, product analytics | Very mature | Deep specialization | 1-4 weeks |
| Mid-size tech / SaaS | Predictive modeling, dashboard creation, A/B testing | Moderate | Moderate breadth | 2-8 weeks |
| Startups (< 50 people) | Everything - ETL, dashboards, ad hoc analysis, ML | Minimal | Extreme breadth | Days to weeks |
| Finance / Insurance | Credit risk, fraud detection, pricing models | Variable | Deep domain specialization | Months |
| Healthcare | Clinical prediction, population health, NLP on records | Often limited | Regulated, compliance-heavy | Months to years |
| Retail / E-commerce | Recommendation engines, demand forecasting, pricing | Moderate to mature | Moderate | Weeks to months |
At large technology companies, data scientists often sit within product teams and focus heavily on experiment design and causal analysis. The infrastructure is mature, data is abundant, and the primary work is measuring the impact of product changes accurately.
Meta's data science team, for example, runs thousands of A/B tests annually, and data scientists are responsible for designing experiments that can detect small but economically meaningful effects.
At startups, data scientists are often generalists doing work that at larger companies would belong to three separate roles: data engineer, analyst, and ML engineer. The breadth is higher; the depth of infrastructure support is thinner. This can be exhilarating or exhausting depending on your temperament.
At traditional industries - retail, insurance, banking, healthcare - data scientists often work on more traditional predictive modeling with longer project cycles and more regulatory considerations. A credit risk data scientist at a bank may spend six months developing a single model that must pass regulatory review before deployment.
Required Skills: What Actually Matters
Technical Skills
Python is the primary language of modern data science. The 2023 Kaggle survey found that 84% of data science respondents used Python regularly, compared to 37% for R and 46% for SQL as their primary language.
Proficiency includes not just syntax but the scientific Python ecosystem: NumPy and pandas for data manipulation, scikit-learn for machine learning, matplotlib and seaborn for visualization, and increasingly PyTorch or TensorFlow for deep learning.
SQL is non-negotiable. Virtually every organization stores data in relational databases or cloud data warehouses (Snowflake, BigQuery, Redshift, Databricks). A data scientist who cannot write efficient SQL joins, window functions, CTEs, and aggregations is unable to access the data needed for any analysis.
Ironically, SQL fluency often matters more in daily work than ML knowledge - you will use SQL every day and may go weeks without training a model.
Statistics and probability form the theoretical foundation. This means understanding distributions, hypothesis testing, confidence intervals, p-values and their limitations, regression assumptions, Bayesian reasoning, and experimental design.
Without this foundation, it is easy to build models that appear to work but are actually measuring noise - what statisticians call overfitting. The 2005 paper by John Ioannidis, "Why Most Published Research Findings Are False," remains a sobering reminder of how easily statistical methods can mislead even trained researchers.
Machine learning knowledge includes understanding the tradeoffs between model types (linear models, decision trees, gradient boosting, neural networks), knowing when each applies, and recognizing common pitfalls like overfitting, data leakage, and distributional shift.
Leo Breiman's influential 2001 paper "Statistical Modeling: The Two Cultures" articulated the fundamental tension between predictive accuracy and interpretability that data scientists navigate daily.
Data visualization - the ability to turn analysis into clear charts and communicate findings visually - is underrated in most technical curricula but critical in practice.
Edward Tufte's principles of data visualization, articulated in The Visual Display of Quantitative Information (1983), remain foundational: maximize the data-to-ink ratio, avoid chartjunk, and let the data speak.
Soft Skills That Determine Impact
Communication is the meta-skill. Research by Brent Dykes, author of Effective Data Storytelling (2019), found that organizations where data scientists excelled at communicating findings to non-technical stakeholders were 3x more likely to report that data science initiatives delivered measurable business value.
The ability to present statistical findings without jargon, to frame analysis in business terms, and to push back when stakeholders want to misuse or over-interpret results is what separates impactful data scientists from technically competent ones who produce reports nobody acts on.
Intellectual honesty - the willingness to say "the data does not support that conclusion" or "our model has a significant limitation here" - is rarer and more valuable than technical brilliance.
In a field where confirmation bias is a constant risk and stakeholders often have strong priors about what the data should show, the data scientist who speaks truth to power provides outsized value.
Problem framing - the ability to translate a vague business question ("Why are customers leaving?") into a well-defined analytical question ("Among customers who joined in Q1, what behavioral signals in the first 30 days predict cancellation within 90 days?") - is perhaps the single most important skill that distinguishes senior data scientists from junior ones.
For more on developing this capability, see our guide on problem framing.
Salary Ranges by Level and Country
The following figures represent total compensation (base salary plus bonus; equity noted separately) as of 2024-2025, drawing on Levels.fyi, Glassdoor, LinkedIn Salary, and the Kaggle State of ML Survey.
United States
| Level | Typical Title | Base Salary (USD) | Total Comp with Equity (USD) |
|---|---|---|---|
| Entry (0-2 years) | Junior / Associate Data Scientist | $85,000-$120,000 | $95,000-$140,000 |
| Mid (2-5 years) | Data Scientist | $120,000-$160,000 | $140,000-$200,000 |
| Senior (5-8 years) | Senior Data Scientist | $150,000-$200,000 | $180,000-$280,000 |
| Staff (8-12 years) | Staff Data Scientist | $190,000-$240,000 | $250,000-$400,000 |
| Principal (12+ years) | Principal Data Scientist | $220,000-$280,000 | $350,000-$500,000+ |
At FAANG-tier companies (Google, Meta, Apple, Amazon, Netflix), total compensation including equity typically adds 30-70% to base salary figures at senior and staff levels. A senior data scientist at Meta might earn a base of $200,000 with $100,000-$200,000 in annual equity grants and a $50,000+ bonus.
The Bureau of Labor Statistics projects 35% employment growth for data scientists through 2032, significantly faster than the average for all occupations. The median annual wage was $108,020 in 2023.
International Markets
| Country | Entry-Level Range | Senior Range | Notes |
|---|---|---|---|
| United Kingdom | GBP 35,000-55,000 | GBP 75,000-110,000 | London 20-30% above national average |
| Germany | EUR 45,000-65,000 | EUR 80,000-110,000 | Berlin and Munich highest markets |
| Canada | CAD 70,000-100,000 | CAD 120,000-170,000 | Toronto and Vancouver lead |
| India | INR 800,000-1,500,000 | INR 2,500,000-6,000,000 | Top companies in Bangalore, Hyderabad |
| Australia | AUD 80,000-115,000 | AUD 140,000-190,000 | Sydney highest-paying market |
| Netherlands | EUR 40,000-60,000 | EUR 70,000-100,000 | Amsterdam tech hub growing |
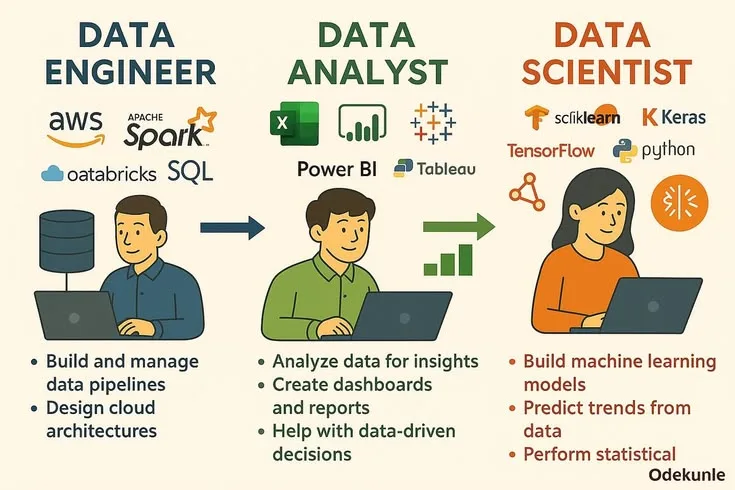
Data Scientist vs Data Analyst vs Machine Learning Engineer
These three titles are frequently confused, and the confusion is compounded by companies using them inconsistently. Understanding the distinctions is important for both career planning and organizational design.
Data analysts focus on describing what happened and why. The primary tools are SQL, Excel, and BI dashboards (Tableau, Looker, Power BI).
Analysts answer questions like "How did revenue change last quarter?" and "Which customer segments are churning fastest?" They surface patterns and communicate them clearly. They typically do not build predictive models or run controlled experiments.
Data scientists focus on prediction, inference, and experimentation. They use statistical modeling and machine learning to answer questions like "Which customers are most likely to churn next month?" and "What would revenue have been if we had launched this feature six months earlier?" The scope includes A/B test design, model building, causal inference, and statistical analysis that goes beyond what basic BI tools support.
Machine learning engineers focus on production systems. They take models that data scientists develop and build the software infrastructure to serve those models reliably at scale - handling deployment, version control, monitoring for model drift, latency optimization, and integration with production applications.
This role requires stronger software engineering skills and less statistical depth than a data science role.
| Dimension | Data Analyst | Data Scientist | ML Engineer |
|---|---|---|---|
| Primary question | What happened? | What will happen? Why? | How do we deploy and scale it? |
| Core tools | SQL, Excel, Tableau, Looker | Python, SQL, Jupyter, scikit-learn | Python, Docker, Kubernetes, MLflow |
| Key skills | Business acumen, visualization, SQL | Statistics, ML, experimentation | Software engineering, DevOps, ML |
| Typical output | Dashboards, reports, ad hoc analyses | Models, experiments, analytical findings | Production ML systems, APIs, pipelines |
| Entry salary (US) | $60,000-$85,000 | $90,000-$130,000 | $110,000-$150,000 |
In practice, the lines blur significantly. Many data scientists deploy their own models at smaller companies. Many analysts do light predictive work. The distinction is most meaningful at companies large enough to have all three roles as separate functions.
Career Path: Junior to Principal
Understanding how careers actually progress is essential for setting realistic expectations in data science.
Junior / Associate Data Scientist (0-2 years): Works on well-scoped problems with significant guidance from senior team members. Learns the data stack, gets comfortable with the codebase and infrastructure, and builds foundational skills in SQL, Python, and basic modeling.
Impact is largely through completing assigned analyses accurately and on time. The primary learning mode is execution - doing the work and getting feedback on methodology and communication.
Data Scientist (2-5 years): Works more independently, scopes own analyses, and begins identifying problems worth solving rather than just answering questions asked by stakeholders. Starts influencing product or business decisions directly through analysis.
May mentor junior team members. Begins developing the judgment about when a simple analysis suffices versus when a more sophisticated approach is warranted - a distinction that separates competent analysts from true data scientists.
Senior Data Scientist (5-8 years): Leads significant projects end-to-end, influences team direction, and handles ambiguous, high-stakes problems with minimal guidance. Often the primary data science voice in cross-functional discussions with product managers, engineers, and executives.
Mentors junior and mid-level scientists. At this level, knowing what not to build - what analyses would be technically interesting but not business-valuable - becomes as important as technical execution.
Staff Data Scientist (8-12 years): Works across multiple teams or a major product area. Identifies opportunities that individual teams are not seeing, shapes methodology standards across the organization, and contributes to hiring and team building.
Comparable to a senior engineering lead in organizational influence. DJ Patil, who served as US Chief Data Scientist under President Obama, described this level as "the person who sees the forest, not just the trees."
Principal Data Scientist (12+ years): Company-wide technical leadership. Sets the direction for how data science is practiced across the organization, identifies the most important problems to apply data science to, and is typically a recognized expert outside the company in their domain.
This is a rare role that requires combining deep technical expertise with strategic business thinking - perhaps fewer than 5% of data scientists reach this level.
The AI and LLM Revolution: How Data Science Is Changing
The emergence of large language models (LLMs) and generative AI since 2022 has significantly altered the data science landscape.
Tools like GitHub Copilot, ChatGPT, and specialized coding assistants can now write basic Python code, generate SQL queries, and even prototype machine learning pipelines. This has raised legitimate questions about which data science tasks will be automated.
Andrew Ng, co-founder of Coursera and a leading AI researcher, argued in a 2023 essay that LLMs would augment rather than replace data scientists, handling routine coding tasks while freeing practitioners to focus on problem formulation, experimental design, and stakeholder communication - the higher-judgment aspects of the role.
The Kaggle 2023 survey found that 65% of data science respondents were already using AI coding assistants, primarily for code generation and debugging, but that the tools were not yet reliable enough for critical statistical analysis or experimental design without human oversight.
The implication for aspiring data scientists: invest more heavily in statistical reasoning, experimental design, and communication - the skills that are hardest for AI to replicate - and less in memorizing syntax or library APIs. The ability to formulate the right question remains distinctly human.
How to Get Started
For career changers: A bootcamp or structured self-study program covering Python, SQL, and basic statistics is a viable entry point, but the key differentiator is building a portfolio of real projects.
Not toy datasets from Kaggle competitions (though those have value for learning), but work that demonstrates you can frame a business question, source messy data, analyze it rigorously, and communicate findings clearly. The portfolio should show judgment, not just technique.
For recent graduates: A degree in statistics, computer science, mathematics, economics, or a quantitative social science is the standard background. Master's degrees are increasingly common (the Burtch Works 2023 survey found that 71% of data scientists held a master's or PhD), though not strictly required at all companies.
Domain knowledge - healthcare, finance, climate, logistics - increasingly differentiates candidates for specialized roles.
For analysts looking to transition: The jump from data analyst to data scientist is achievable and common. The gap is usually in machine learning skills and statistical depth.
Targeted study of ML fundamentals (Andrew Ng's Machine Learning Specialization on Coursera remains a solid foundation) combined with project work closes that gap over 6-12 months for motivated practitioners.
The transition is easier at your current employer, where you already have domain knowledge and stakeholder relationships.
For related guidance on building professional skills systematically, see our articles on analytical thinking skills and deep work.
Pros and Cons: An Honest Assessment
Pros:
- High salary ceiling with strong demand projected through 2032
- Intellectually stimulating work that combines mathematical rigor with real-world problem solving
- Applicable across virtually every industry, providing career flexibility
- Generally remote-friendly - the 2023 Kaggle survey found 62% of data scientists worked remotely at least part-time
- Continuous learning is built into the role, keeping work fresh
Cons:
- Much of the daily work is unglamorous data cleaning, not sophisticated modeling
- Results are frequently ambiguous, ignored, or overridden by stakeholder opinions
- Career progression stalls without strong communication and stakeholder management skills
- The field moves rapidly, requiring continuous investment in learning new tools and techniques
- Imposter syndrome is pervasive - the breadth of required knowledge (statistics, engineering, domain expertise, communication) means almost everyone feels inadequate in at least one area
- Many organizations still struggle to integrate data science effectively, leading to frustration when good analysis fails to influence decisions
The Most Important Skill Nobody Talks About
The most important skill difference between data scientists who advance quickly and those who plateau is not technical - it is the ability to identify which questions are worth answering. Building a perfect model for the wrong problem is a common and expensive failure mode.
Senior practitioners spend proportionally more time deciding what to work on than executing the work itself.
Cassie Kozyrkov, former Chief Decision Scientist at Google, has written extensively about this dynamic, arguing that the core value of data science leadership is "deciding what to decide" - choosing which questions, if answered well, would most change the organization's behavior.
This is fundamentally a business skill, not a technical one, and it is why the most impactful data scientists often have unusual career paths that combine technical training with deep domain experience.
If you are entering the field, invest heavily in SQL and communication before optimizing for deep learning knowledge. The majority of data science work at most companies does not use neural networks, but all of it uses SQL and all of it requires persuading someone to act on the results.
Sources & Further Reading
- Davenport, T. H., & Patil, D. J. "Data Scientist: The Sexiest Job of the 21st Century." Harvard Business Review, October 2012.
- Anaconda. "2020 State of Data Science Report." Anaconda, Inc., 2020.
- Kaggle. "State of Data Science and Machine Learning Survey." Kaggle, 2023.
- Bureau of Labor Statistics, US Department of Labor. "Occupational Outlook Handbook: Data Scientists." BLS.gov, 2024. View source
- Levels.fyi. "Data Science Salary Data." 2024. View source
- Ioannidis, J. P. A. "Why Most Published Research Findings Are False." PLoS Medicine, 2(8), e124. 2005.
- Breiman, L. "Statistical Modeling: The Two Cultures." Statistical Science, 16(3), 199-231. 2001.
- Tufte, E. The Visual Display of Quantitative Information. Graphics Press, 1983.
- Dykes, B. Effective Data Storytelling: How to Drive Change with Data, Narrative and Visuals. Wiley, 2019.
- Provost, F., & Fawcett, T. Data Science for Business. O'Reilly Media, 2013.
- Ng, A. "Machine Learning Specialisation." Coursera / DeepLearning.AI, 2022. View source
- Grus, J. Data Science from Scratch. O'Reilly Media, 2nd edition, 2019.
- McKinsey Global Institute. "The Age of Analytics: Competing in a Data-Driven World." McKinsey & Company, 2016.
- Burtch Works. "Data Science Salary Survey." 2023. View source
- Kozyrkov, C. "What Great Data Analysts Do - and Why Every Organization Needs Them." Harvard Business Review, 2019.
- VanderPlas, J. Python Data Science Handbook. O'Reilly Media, 2016.
- LinkedIn Economic Graph. "Jobs on the Rise 2024." LinkedIn, 2024.
Frequently Asked Questions
What does a data scientist do day to day?
Day-to-day work varies by company and seniority but typically involves querying databases to extract data, cleaning and transforming messy datasets, building statistical or machine learning models, and presenting findings to stakeholders. A significant portion, often 50-70% of time, is spent on data wrangling rather than modelling.
What is the difference between a data scientist and a data analyst?
Data analysts focus on describing what happened using SQL, dashboards, and reports. Data scientists go further by building predictive models and running experiments to understand why something happened and what will happen next. In practice the boundary is blurry and job titles vary widely by company.
What skills do you need to become a data scientist?
Core technical skills include Python or R, SQL, statistics and probability, and familiarity with machine learning libraries such as scikit-learn, TensorFlow, or PyTorch. Strong communication is equally important, data scientists must translate complex results into clear business recommendations.
How much do data scientists earn?
In the United States, entry-level data scientists earn \(90,000-\)120,000 per year. Senior data scientists earn \(140,000-\)200,000, and principal or staff-level roles at major tech companies can exceed $300,000 in total compensation including equity. Salaries outside the US are typically 30-60% lower.
How is a data scientist different from a machine learning engineer?
Data scientists focus on analysis, experimentation, and model development. Machine learning engineers take those models and build the production infrastructure to serve them at scale, handling deployment, monitoring, and reliability. At smaller companies, one person often does both jobs.