There is a useful thought experiment for understanding software development workflows: imagine asking two different teams to build the same application, with the same requirements, the same technology stack, the same budget, and developers of identical individual skill.
One team operates with well-designed workflow practices - thoughtful branching, systematic code review, automated testing, and continuous deployment. The other operates ad hoc - developers committing directly to the main branch, testing manually before deployments, reviewing code informally or not at all.
Three months later, the applications will be meaningfully different. Not because the developers are different, but because the process amplifies or diminishes individual capability. The well-organized team's codebase will be more consistent, more tested, and better documented.
Bugs will be caught earlier. Deployments will be more frequent and more reliable. New developers joining will become productive faster. The ad hoc team will have accumulated technical debt that makes every subsequent change harder and riskier.
Development workflows are the organizational technology of software teams. Like physical technology, they can be well or poorly designed, can compound capability or create friction, and can be improved systematically over time. This article examines the workflows that high-performing teams have converged on and the reasoning behind them.
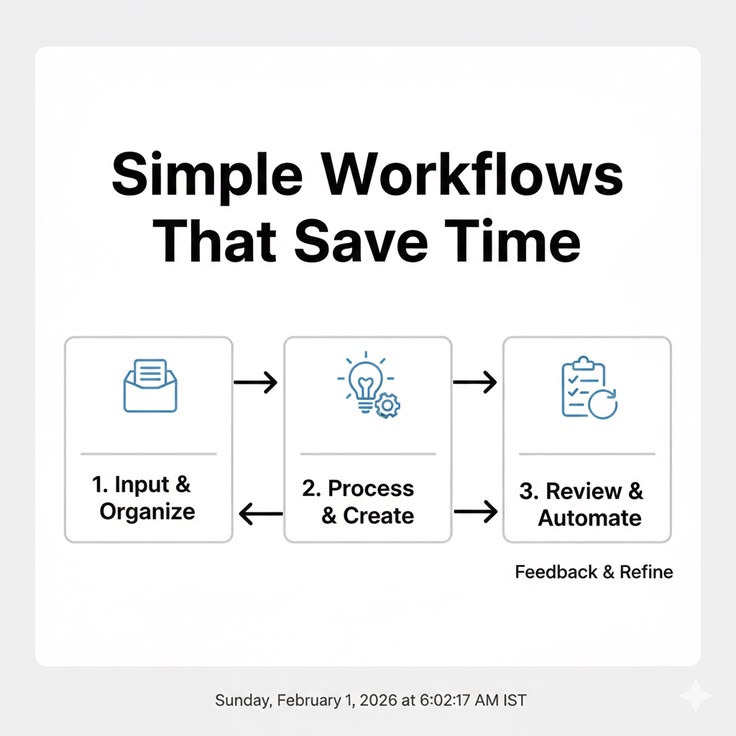
The Foundations: What a Workflow Must Accomplish
A development workflow is the complete system of practices that governs how code moves from an individual developer's machine to users. At minimum, it must answer:
- How is work organized and prioritized?
- How does code get written, reviewed, and integrated?
- How is quality verified before code reaches users?
- How does code get deployed and monitored in production?
- How does the team coordinate and communicate?
Each question has multiple valid answers with different trade-offs. The right answers depend on team size, codebase complexity, deployment frequency, regulatory requirements, and organizational culture. What matters is that the answers are explicit and designed rather than implicit and accidental.
| Workflow Practice | Purpose | Risk If Skipped |
|---|---|---|
| Feature branching | Isolates work in progress from stable code | Unstable main branch, difficult parallel development |
| Code review | Catches bugs, spreads knowledge, maintains standards | Defect accumulation, siloed knowledge |
| Automated testing in CI | Verifies changes do not break existing functionality | Regressions deployed to production |
| Sprint planning | Aligns team on priorities before work begins | Developers work on wrong things |
| Sprint retrospective | Identifies and addresses process problems | Process debt compounds sprint-over-sprint |
| Continuous deployment | Reduces batch size and deployment risk | Infrequent big-bang releases with high failure rates |
'The biggest risk in software development is not moving too slowly. It is moving confidently in the wrong direction. Workflow practices exist not to slow development down, but to ensure that what gets built is correct, that it works, and that the team can keep building on it without the codebase becoming a liability.'
- Kent Beck, creator of Extreme Programming and co-author of the Agile Manifesto (2001)
Agile Development: The Iterative Foundation
The Case for Iteration
The waterfall development model, which dominated software development from the 1970s through the 1990s, organized work as a sequential series of phases: requirements, design, implementation, testing, deployment. Each phase was completed before the next began. Requirements were locked at project start.
The approach failed repeatedly for a straightforward reason: software requirements are discovered through building, not defined beforehand. Users cannot reliably articulate what they want before they have seen something concrete; developers cannot anticipate every constraint before they have encountered it in practice.
Long development cycles before any user feedback meant that teams built wrong things thoroughly and discovered the mismatch only after spending a year on it.
Agile development, articulated in the Agile Manifesto of 2001, responded to these failures with an iterative approach: build a small piece, deliver it to users, gather feedback, incorporate the learning into the next iteration. The cycle repeats continuously.
Requirements evolve as understanding deepens rather than being locked at project start.
Iteration reduces risk by reducing the time between building and learning. A monthly release cycle means that a wrong assumption held for at most a month before correction. A weekly cycle means at most a week. This is not just faster - it is fundamentally a different approach to managing the uncertainty inherent in software development.
Sprint-Based Development
The most widely adopted agile framework is Scrum, which organizes work into fixed-length iterations called sprints (typically one to two weeks). Each sprint produces a potentially shippable increment of the product.
The sprint cycle includes several recurring ceremonies:
Sprint planning begins each sprint. The team examines the product backlog - a prioritized list of features, improvements, and bug fixes - and selects work for the sprint. The product owner explains priorities and acceptance criteria; developers estimate effort and ask clarifying questions.
The sprint ends with a committed sprint goal: a clear statement of what the sprint will accomplish.
The daily standup is a 15-minute daily coordination meeting. Each developer answers three questions: What did I complete yesterday? What am I working on today? What is blocking me? The standup is explicitly not a status report to management; it is a coordination mechanism between developers.
Blockers surfaced at standup get resolved during the day.
The sprint review (or demo) occurs at the sprint's end. The team demonstrates completed work to stakeholders, product managers, and sometimes customers. Working software is the measure of progress - not plans, not documents, not partially completed features. Feedback from the review informs the next sprint's priorities.
The sprint retrospective follows the review. The team reflects on its process rather than its product: What practices worked well? What created friction? What will we try differently next sprint? The retrospective is the mechanism through which teams continuously improve their workflows.
Teams that skip retrospectives accumulate process debt alongside their technical debt.
Example: Spotify's engineering organization scaled agile practices to hundreds of developers through a model published in 2012. They organized developers into small cross-functional "squads" of six to twelve people, each owning a product area end-to-end.
Squads within related areas formed "tribes"; squads with similar roles formed "chapters" to share practices. The model was not prescriptive - squads chose their own tools and ceremonies - but it provided enough structure to coordinate without requiring centralized control.
Versions of this model have been adopted by engineering organizations at ING Bank, Zalando, and dozens of other large technology organizations.
Kanban and Continuous Flow
Some teams find the sprint model's fixed timebox poorly suited to their work. Operations teams, support engineers, and teams with highly variable, unpredictable work items often prefer Kanban: a continuous flow model without sprints.
Kanban visualizes work as items moving through stages on a board (typically: To Do, In Progress, Review, Done). The critical mechanism is the work-in-progress limit: each stage has a maximum number of items that can be in it simultaneously. When the limit is reached, no new items enter that stage until one completes.
Work-in-progress limits force the team to finish things before starting new things. This sounds obvious but runs counter to typical developer instincts. When blocked on one task, the natural impulse is to start another.
WIP limits prevent this, because starting a new task while one is blocked would exceed the limit. Instead, the team swarms on the block - multiple people helping to resolve the blocker so the queue can move.
This approach reduces lead time (the time from starting to completing a work item) by minimizing the accumulated latency of tasks sitting in queues waiting for the next stage.
A task that moves through four stages in sequence, waiting a day at each transition, takes four days longer than necessary regardless of how quickly work is done at each stage.
Version Control Workflows
The Centrality of Git
Git, created by Linus Torvalds in 2005, is the version control system used by virtually every professional software team. Understanding Git's model is foundational to understanding modern development workflows.
Git is a distributed version control system: every developer has a complete copy of the repository's history, not just the current state. Changes are made in local commits, then pushed to shared remote repositories (typically hosted on GitHub, GitLab, or Bitbucket).
The distributed model enables parallel work across a team without constant coordination.
Git's branching model allows parallel lines of development. A branch is a pointer to a specific commit; creating a branch is inexpensive. Developers create branches to isolate their work from others, develop features independently, and merge changes back when complete.
Feature Branch Workflow
The feature branch workflow is the most widely adopted strategy for professional teams:
- A developer creates a branch from the main branch: for a new search feature,
git checkout -b feature/product-search - The developer commits changes to this branch as work progresses
- When ready for review, the developer pushes the branch and opens a pull request (PR) - a formal proposal to merge the branch into main
- The team reviews the PR, leaving comments, requesting changes, and approving when satisfied
- Automated checks (linting, testing, security scanning) run against the PR
- After approval and passing checks, the branch is merged
- The feature branch is deleted
This workflow keeps the main branch stable - it always reflects code that has been reviewed and tested. Multiple developers can work on different features simultaneously without interfering. The pull request serves as both a quality gate and a communication artifact, documenting what changed and why.
GitHub Flow
GitHub Flow simplifies the feature branch workflow for teams that deploy frequently:
- The main branch is always deployable to production
- All work happens on feature branches
- Pull requests trigger review and automated checks
- After approval, branches merge directly to main
- Deployment happens from main, often automatically
GitHub Flow works well for web applications with continuous deployment. Its simplicity prevents the confusion that more complex branching strategies introduce. The key precondition is that main is always stable enough to deploy - which requires comprehensive automated testing.
Git Flow
Git Flow, introduced by Vincent Driessen in 2010, provides more structure for projects with scheduled releases:
- A
mainbranch contains only production-ready release commits - A
developbranch accumulates completed features awaiting the next release feature/*branches branch from and merge back intodeveloprelease/*branches branch fromdevelopfor release preparation, then merge into bothmainanddevelophotfix/*branches branch frommainto fix critical production bugs, then merge into bothmainanddevelop
Git Flow suits projects that cannot deploy continuously - mobile applications that require app store approval, enterprise software with structured release cycles, or libraries with versioned releases. For web applications with continuous deployment capabilities, it introduces complexity without corresponding benefit.
Trunk-Based Development
Trunk-based development is the practice used at Google, Meta, and Microsoft at enormous scale. All developers commit directly to the main branch (the "trunk") multiple times per day. Feature branches exist for at most a day or two before merging.
The practice that makes this viable at scale is feature flags: toggles that enable or disable features for specific users or percentage of traffic. Code for an in-progress feature is deployed behind a disabled flag.
The incomplete feature exists in production but is invisible to users until it is ready. When the feature is complete and validated, the flag is enabled.
Feature flags decouple deployment from release. Code ships continuously; features release on business timelines. A team can merge work-in-progress code to main every day without that code appearing to users until deliberately enabled.
The DORA research program, whose findings are documented in Accelerate by Forsgren, Humble, and Kim, found that trunk-based development practices correlate with elite software delivery performance: more frequent deployments, shorter lead times, and lower change failure rates.
Example: Google employs roughly 25,000 software engineers working in a single, monolithic repository containing over two billion lines of code. Despite this scale, the repository has one trunk. Engineers commit to it directly, multiple times per day.
Automated testing infrastructure validates each commit against thousands of tests. Feature flags control what each user sees. This workflow has been in place for decades and is considered a core contributor to Google's engineering velocity.
Commit Discipline
Commits are the atomic unit of code history. A commit that contains a clear explanation of what changed and why is an asset to future maintainers; a commit with a message of "fix" or "update" is a liability.
Conventional Commits is a widely adopted specification for commit message format:
type(scope): short description
Longer explanation of what changed and why, if needed.
Closes #1234Where type is one of: feat (new feature), fix (bug fix), refactor (code restructuring without behavior change), test (test additions or corrections), docs (documentation), or chore (maintenance tasks).
The benefit of consistent commit message format is tooling: release notes can be generated automatically, changelogs can be created from commit history, and semantic version numbers can be incremented automatically based on whether commits contain breaking changes.
Code Review: The Quality Gate
Why Code Review Is Non-Negotiable
Studies of defect density in software consistently find that code review is one of the most cost-effective quality practices available. Research at Microsoft found that formal code review catches 60-70% of defects before they reach testing or production. The same defects found in production cost an order of magnitude more to fix.
Code review provides additional value beyond defect detection:
- Knowledge transfer: Reviewers learn about code they did not write; authors learn from reviewer suggestions
- Consistency enforcement: Architecture, naming conventions, and design patterns stay consistent across the codebase
- Bus factor reduction: Multiple developers understand each significant change, reducing dependency on any single person
- Mentoring: Senior developers teach through specific, contextual feedback rather than abstract instruction
The Pull Request as a Document
A well-written pull request description communicates:
- What problem this change solves (the why)
- What approach was chosen and why alternatives were rejected
- What testing was done to verify the change
- What the reviewer should pay particular attention to
- Any known limitations or follow-up work needed
A pull request with this information enables reviewers to evaluate the change in context, reduces the number of clarifying questions, and creates a permanent record of the decision-making process. A year later, when someone questions why code is written in a particular way, the pull request provides the answer.
What Reviewers Evaluate
Code review covers multiple dimensions simultaneously:
Correctness: Does the code do what it claims? Are edge cases handled? Does it match the stated requirements? Are error conditions addressed?
Design: Is the approach sound? Is there unnecessary complexity? Could the problem be solved more simply? Does the change fit coherently into the existing architecture?
Readability: Can a developer unfamiliar with this code understand what it does and why? Are variable names descriptive? Is the control flow clear? Do comments explain intent where intent is not obvious from the code?
Tests: Are there tests? Do they cover the important cases, including edge cases and error paths? Are the tests readable and maintainable?
Security: Are inputs validated? Are there SQL injection, XSS, or authentication vulnerabilities? Is sensitive data handled appropriately?
Performance: Are there obvious performance problems? O(n^2) algorithms where O(n) is achievable? Unnecessary database queries in loops?
Example: Stripe's engineering culture treats code review as a core engineering practice, not a bureaucratic gate. Engineers are expected to review pull requests from their teammates within a business day. Reviews are expected to be thorough and educational rather than cursory approvals.
The company's engineering blog attributes much of the reliability of their payment processing infrastructure to the culture of careful review that catches problems before they reach production.
Review Culture: Making It Work
Code review that is technically sound but culturally punishing is counterproductive. Authors who receive harsh or dismissive feedback become reluctant to submit code for review, which defeats the purpose.
A productive review culture requires psychological safety: authors must feel comfortable submitting work that is not yet perfect; reviewers must feel comfortable raising substantive concerns without fear of conflict.
Practices that support productive review culture:
- Distinguish blocking from non-blocking feedback: Clearly mark which issues must be resolved before merge and which are suggestions
- Explain reasoning: "This approach could cause a race condition because..." is actionable; "Don't do this" is not
- Ask questions rather than issue commands: "Have you considered handling the case where the user object is null?" invites discussion; "Handle null users" closes it down
- Acknowledge good work: Noting when an approach is elegant or well-designed costs nothing and reinforces good practice
- Review the design, not the person: Frame feedback around the code, not the author's judgment
Continuous Integration and Continuous Deployment
Continuous Integration
Continuous Integration (CI) is the practice of automatically building and testing code on every commit or pull request.
The principle is that integration problems - the bugs and conflicts that arise when code from different developers is combined - should be discovered immediately, while the context is fresh and the cost of fixing them is low.
A typical CI pipeline runs:
- Linting and static analysis to catch style violations and common mistakes
- Type checking to catch type errors without running the program
- Unit tests verifying that individual functions behave correctly
- Integration tests verifying that components work together
- Security scanning for known vulnerability patterns
- Code coverage measurement
These checks run automatically when a developer pushes code or opens a pull request. Results appear on the pull request, and broken checks block the merge. No code reaches the main branch without passing automated verification.
The CI principle that integration problems should be detected immediately requires that CI pipelines be fast. A pipeline that takes 45 minutes to run is not a fast feedback loop. Developers have moved on to other work by the time results arrive; reconstructing context to address a CI failure takes additional time.
Most CI systems should run in under 15 minutes; under 10 is better. Achieving fast CI requires investment in test parallelization, caching, and occasionally in reconsidering which tests run on every commit versus which run on a scheduled basis.
Continuous Deployment
Continuous Deployment (CD) extends CI by automatically deploying verified code to production. When the CI pipeline succeeds on the main branch, deployment begins automatically.
Continuous deployment requires a high level of automated test coverage and confidence in the deployment process itself. Organizations that practice it - companies like Amazon, Etsy, and Netflix - have invested significantly in automated testing infrastructure and deployment tooling.
The benefits are substantial: faster delivery of value to users, smaller deployments that are easier to reason about and roll back when problems occur, and elimination of the coordination overhead of scheduled release cycles.
The DORA research finds that high-frequency deployment correlates with lower change failure rates, counterintuitively - frequent small deployments are safer than infrequent large ones.
Example: Amazon is frequently cited for deploying to production every 11.7 seconds on average, a figure from a 2011 velocity conference presentation.
The infrastructure enabling this includes automated testing at every level, canary deployments that route a small percentage of traffic to new code before full rollout, and automated rollback that triggers when error rates exceed thresholds.
The process is not reckless velocity - it is the careful application of automation to make small deployments safe and routine.
Deployment Strategies
Not all deployment strategies treat all traffic identically. Several patterns reduce risk:
Canary deployment routes a small percentage of traffic - 1% to 5% - to the new version before full rollout. Monitoring observes error rates and performance on the canary instances. If metrics look healthy, rollout proceeds. If problems appear, only a small fraction of users was affected and rollout stops.
Blue-green deployment maintains two identical production environments. The "green" environment serves all traffic. When deploying, the new version is deployed to the idle "blue" environment and tested. Traffic switches from green to blue in a single step.
If problems appear, switching back to green is equally instantaneous.
Feature flags allow code to be deployed without being activated. A new feature ships to all servers but is enabled only for internal users, then a small percentage of users, then everyone. If problems appear at any stage, the flag disables the feature without rollback.
Collaborative Practices
Pair Programming
Pair programming places two developers at one workstation: one types (the driver), one thinks ahead and reviews (the navigator). The roles rotate every 15-30 minutes. Both developers are engaged with the same problem simultaneously.
The practice sounds inefficient - two developers working at the rate of one. Research tells a different story. Laurie Williams at North Carolina State University found that paired developers produce code with approximately 15% fewer defects while using approximately 15% more total time than solo developers.
Defect prevention is cheaper than defect correction; the investment in pairing pays back through reduced debugging and testing effort.
Pair programming is particularly valuable for:
- Complex design decisions where diverse perspective prevents expensive mistakes
- Debugging difficult or intermittent problems
- Onboarding new team members into an unfamiliar codebase
- High-stakes code where correctness is critical
It adds less value for straightforward implementation, exploratory research, or administrative work.
Asynchronous Collaboration in Distributed Teams
Remote and distributed teams require explicit design of coordination mechanisms that co-located teams receive informally. The hallway conversation, the whiteboard sketch, the overheard discussion - none of these exist in distributed settings. They must be replaced with intentional practices.
Writing over talking: Decisions documented in writing are accessible asynchronously, searchable later, and not dependent on everyone being present simultaneously. A pull request that documents the reasoning behind an architectural decision is more valuable than a meeting in which that reasoning was discussed verbally and forgotten.
Explicit communication norms: Distributed teams need explicit agreements about expected response times, which channels are used for what kinds of communication, and how urgency is signaled. Without these norms, the absence of immediate response creates anxiety; with them, asynchronous response becomes the comfortable default.
Video calls for high-bandwidth communication: Some communication is difficult in writing - disagreements that require negotiation, complex technical explanations that benefit from shared visual workspace, relationship-building that benefits from visual and auditory cues.
Video calls should be reserved for these high-bandwidth needs, not used as a default for every conversation.
Example: GitLab's public handbook, exceeding 2,000 pages, documents every process, tool, decision framework, and norm in their engineering organization. The handbook is the primary coordination mechanism for 2,000+ employees in 65+ countries.
A developer joining GitLab can find the answer to almost any procedural question without asking anyone. The investment in documentation is the infrastructure that makes distributed coordination possible at scale.
Managing Technical Debt Within the Workflow
What Technical Debt Is and How It Accumulates
Technical debt is a metaphor introduced by Ward Cunningham for the accumulated cost of expedient decisions: code that was written quickly under deadline pressure, architecture that was designed for smaller scale than the system has reached, tests that were skipped to ship faster, documentation that was deferred indefinitely.
The metaphor is useful because it captures the compound nature of the problem. Like financial debt, technical debt accumulates interest: each piece of deferred work makes subsequent work harder, and the harder subsequent work is, the more likely it is to generate new debt.
A codebase with significant technical debt has slow, error-prone development velocity even with highly skilled developers - not because the developers are bad, but because the debt taxes every change they make.
Technical debt accumulates through several mechanisms:
- Deadline-driven shortcuts: Decisions made under time pressure that are known to be suboptimal
- Knowledge decay: Code that was appropriate when written but has become outdated as requirements changed
- Scope creep: Systems extended beyond their original design assumptions
- Neglected maintenance: Dependency updates, deprecated API migrations, and security patches deferred
Debt Management in the Workflow
The most effective approach to technical debt is continuous small repayment rather than periodic large repayment efforts.
The Boy Scout Rule - leave code better than you found it - applied consistently across a team produces steady debt reduction without dedicated effort. Every developer who touches a module improves it slightly: renames a confusing variable, extracts a repeated pattern, adds a missing test. Over months, these small improvements compound.
Dedicated debt reduction time - typically 20% of sprint capacity - ensures that significant improvements happen alongside feature work. Leaving this entirely to "when we have time" means it never happens; time is always occupied by feature work unless explicitly protected.
Refactoring before extending is a practice of cleaning up a module before adding new functionality to it. The argument is that adding features to messy code is slower and more error-prone than cleaning up the mess first, then adding the features. The refactoring investment pays back immediately in the quality of the feature work.
The relationship between technical debt, code quality, and workflow is explored further in how software is actually built and in the principles of API design that help systems remain maintainable as they evolve.
Workflow Maturity: A Progression
Teams do not arrive at sophisticated workflows fully formed. Workflow maturity develops incrementally, and the appropriate workflow depends on team size, codebase complexity, and deployment frequency requirements.
Stage 1 - Ad hoc: Developers commit directly to main, deploy manually, review informally or not at all. Works for very small teams early in a project; becomes problematic as the team grows.
Stage 2 - Feature branches and pull requests: Work happens on branches; changes require PR review before merging. Automated tests run on PRs. Deployments are scripted. This stage handles most small-to-medium teams effectively.
Stage 3 - Continuous integration: CI pipeline runs automatically on every PR and commit. Broken builds block merges. Test coverage is measured and maintained. Linting and security scanning are automated. Deployments are more frequent and more reliable.
Stage 4 - Continuous deployment: Successful CI on main triggers automatic deployment to production. Feature flags decouple deployment from release. Monitoring with automated alerting detects problems before users do. Rollback is automated and fast.
Stage 5 - Full observability and experimentation: Distributed tracing, structured logging, and real user monitoring provide immediate visibility into production behavior. Feature flags support systematic A/B testing. Deployment pipelines include canary rollouts. Incidents trigger automated runbooks.
Each stage requires investment to reach. The appropriate investment depends on what the current stage is costing in bugs, deployment risk, development speed, and developer time.
What Research Shows About Development Workflows
The most rigorous large-scale research on software development workflow effectiveness comes from the DORA (DevOps Research and Assessment) program, a multi-year study led by Dr. Nicole Forsgren (then at DevOps Research and Assessment, subsequently at Google and Microsoft Research), Jez Humble, and Gene Kim.
Published in Accelerate: The Science of Lean Software and DevOps (2018), the research surveyed more than 23,000 respondents across organizations of every size and industry between 2014 and 2017, making it the largest empirical study of software delivery practices ever conducted.
The study identified four key metrics - deployment frequency, lead time for changes, change failure rate, and time to restore service - and found that elite-performing organizations outperformed low performers by extraordinary margins: 208 times more frequent deployments, 106 times shorter lead times, 7 times lower change failure rates, and 2,604 times faster recovery from incidents.
The gap is categorical, not marginal: elite teams operate in an entirely different performance regime.
DORA research also identified the specific practices that predict elite performance. Trunk-based development (committing to the main branch at least daily) was among the strongest technical predictors of high performance, with teams practicing it showing deployment frequency 4 times higher than teams using long-lived feature branches.
Continuous integration and comprehensive automated testing combined with trunk-based development formed what DORA researchers called a "technical practices cluster" that explained most of the variance in delivery performance between elite and low-performing teams.
The 2022 State of DevOps Report, the largest in the series with over 32,000 respondents, found that these relationships had strengthened over time as the industry matured around proven practices.
Laurie Williams at North Carolina State University has produced the most empirically rigorous research on pair programming specifically. Her 2000 study, "Strengthening the Case for Pair Programming," published in IEEE Software, compared paired and solo developers on identical tasks across multiple skill levels.
Paired developers produced code with 15% fewer defects while using approximately 15% more total programmer-hours - a result that makes economic sense when post-delivery defect costs are included.
A 2007 follow-up study by Hannay and colleagues at Simula Research Laboratory in Norway, published in IEEE Transactions on Software Engineering, surveyed 18 pair programming experiments and found the defect reduction benefit was consistent across studies, with an average of 12 to 18 percent fewer defects in paired code.
However, they also found that the productivity benefit depended heavily on task complexity: paired developers showed the greatest advantage on complex, unfamiliar problems and no significant advantage on routine well-defined tasks.
Research on code review effectiveness at Microsoft Research, published by Alberto Bacchelli and Christian Bird in "Expectations, Outcomes, and Challenges of Modern Code Review" (ICSE 2013), surveyed 873 Microsoft developers and analyzed 570 code reviews.
The study found that the primary benefit of code review, as measured by actual review outcomes, was knowledge transfer and team awareness - not defect detection, which developers cited as the primary motivation.
Only 15% of review comments addressed actual defects; the majority addressed code quality improvements, alternative approaches, and knowledge sharing. The research suggests that code review's value compounds over time through team capability building rather than delivering its primary return through defect prevention.
The impact of sprint length and iteration pace on software quality was studied by Rashina Hoda and colleagues at the University of Auckland, in research published in IEEE Transactions on Software Engineering in 2013.
The study found that teams using shorter iterations (one week) identified requirement misunderstandings 3 times earlier than teams using longer iterations (four weeks), reducing the cost of requirement changes by approximately 60%.
Teams with shorter cycles also reported higher satisfaction with their ability to respond to changing requirements.
The research supports the Agile Manifesto's emphasis on short iterations as a mechanism for managing uncertainty rather than a preference for speed per se.
Real-World Case Studies in Development Workflows
Spotify's Squad model, published by Henrik Kniberg and Anders Ivarsson in 2012, documents how one of the most widely imitated workflow innovations in the industry was developed and evolved.
Spotify organized its approximately 700 engineers (at the time of the paper) into small "squads" of six to twelve people, each owning a product area end-to-end and choosing their own tools, ceremonies, and workflows.
Squads with related domains formed "tribes"; squads with similar roles across tribes formed "chapters" for sharing practices.
The model reduced coordination overhead by pushing autonomy to the squad level while maintaining alignment through shared mission and metrics.
By 2014, Spotify reported that its deployment frequency had increased from quarterly to daily for most teams, with no increase in change failure rates - a result they attributed primarily to small team size and autonomous ownership rather than to any specific technical tool.
The model has been adopted, in whole or part, by ING Bank, Zalando, and dozens of other engineering organizations globally, making it one of the most influential workflow innovations of the 2010s.
Amazon's deployment transformation, described by CTO Werner Vogels in multiple public forums and studied by DORA researchers, took Amazon from monthly releases to deploying to production 23,000 times per day by 2014.
The transformation required not just technical infrastructure - automated deployment pipelines, extensive automated testing, canary deployments - but organizational restructuring around the "two-pizza team" rule and the elimination of separate development and operations teams.
A 2011 Velocity conference presentation by Jon Jenkins documented the technical details: a deployment coordination system called Apollo that tracked which code was deployed where, automated rollback triggers based on error rate thresholds, and a culture of every developer owning their code in production.
The measurable outcomes included a 75% reduction in deployment-related incidents despite a 10-fold increase in deployment frequency, a counterintuitive result that Amazon uses to illustrate the safety benefits of frequent small deployments.
Etsy's transition from monthly to continuous deployment, documented by CTO Chad Dickerson and engineers in multiple conference talks and blog posts between 2009 and 2012, is among the most detailed accounts of a workflow transformation at an established company.
When Dickerson joined Etsy in 2008, the company deployed monthly with significant coordination overhead and frequent deployment failures. The transformation to continuous deployment required cultural change - developers became responsible for deploying and monitoring their own code - as much as technical change.
The specific practices Etsy developed included a "deploy train" system where any engineer could deploy at any time, a comprehensive post-deployment monitoring dashboard visible to all engineers, and a "just deploy it" culture enforced from leadership.
By 2012, Etsy was deploying 50 or more times per day with a change failure rate below 2% - and reported that engineer satisfaction with their work had increased substantially as a side effect of the increased ownership and agency that continuous deployment enabled.
GitLab's all-remote workflow, documented in their public handbook of over 2,000 pages, demonstrates how explicit workflow design enables coordination across 2,000 employees in 65+ countries without offices.
GitLab's engineering workflow principles include a documented bias toward asynchronous communication (all significant decisions are written before being discussed verbally), a strong emphasis on merge request quality (including a 1,500-word merge request guide specifying exactly how to describe changes, link issues, and request review), and mandatory documentation of all processes.
The company has measured the impact through engineering metrics: mean time to merge for pull requests averages 2 days globally despite no timezone overlap between many contributors.
GitLab's public benchmark against industry norms (using DORA metrics) shows performance in the elite tier for all four key metrics - evidence that all-remote workflow, when systematically designed, does not reduce engineering velocity relative to co-located alternatives.
Sources & Further Reading
- Forsgren, Nicole, Humble, Jez, and Kim, Gene. Accelerate: The Science of Lean Software and DevOps. IT Revolution Press, 2018. View source
- Driessen, Vincent. "A Successful Git Branching Model." nvie.com, 2010. View source
- Kniberg, Henrik and Ivarsson, Anders. "Scaling Agile at Spotify." Spotify Labs, 2012. View source
- Williams, Laurie and Kessler, Robert. Pair Programming Illuminated. Addison-Wesley, 2002.
- Beck, Kent and Andres, Cynthia. Extreme Programming Explained. Addison-Wesley, 2004.
- Fowler, Martin. "Feature Toggles (aka Feature Flags)." martinfowler.com. View source
- Fowler, Martin. "Continuous Integration." martinfowler.com. View source
- GitLab. "The GitLab Handbook." handbook.gitlab.com. View source
- Conventional Commits. "Conventional Commits Specification v1.0.0." conventionalcommits.org. View source
- Humble, Jez and Farley, David. Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation. Addison-Wesley, 2010.
Frequently Asked Questions
What is a typical agile development workflow?
Agile workflow (commonly Scrum): (1) Sprint planning, team decides what to build in next 1-2 weeks, (2) Daily standups, 15-minute sync on progress and blockers, (3) Development, team works on sprint tasks, (4) Code review, peers review all changes, (5) Sprint review/demo, show completed work to stakeholders, (6) Retrospective, reflect on what went well, what to improve. Sprint cycle: repeating 1-2 week iterations. Each sprint: deliver working software, gather feedback, adjust priorities. Key roles: (1) Product Owner, defines what to build, prioritizes backlog, (2) Scrum Master, facilitates process, removes blockers, (3) Development Team, builds the software. Artifacts: (1) Product backlog, all future work, prioritized, (2) Sprint backlog, tasks for current sprint, (3) Increment, working software at sprint end. Philosophy: iterative not waterfall, working software over documentation, respond to change over following plan. Reality: many teams adapt agile to their needs, pure Scrum uncommon, principles more important than rigid process.
What are common Git workflows and branching strategies?
Git workflows: (1) Feature branch workflow, each feature on separate branch, merge via pull request, (2) Git Flow, structured branches (main, develop, feature, release, hotfix), (3) GitHub Flow, simple: main branch always deployable, feature branches for all changes, (4) Trunk-based development, everyone commits to main frequently, feature flags for incomplete work. Feature branch workflow (most common): (1) Create branch from main (git checkout -b feature-name), (2) Make commits on branch, (3) Push branch to remote, (4) Open pull request, (5) Team reviews, (6) Address feedback, (7) Merge to main, (8) Delete branch. Branch naming: feature/add-login, bugfix/fix-crash, refactor/simplify-auth. Commit messages: clear, explain why (not just what changed). Merge strategies: (1) Merge commit, preserves all commits, (2) Squash, combine commits into one, cleaner history, (3) Rebase, linear history, more complex. Best practices: (1) Small focused branches, easier to review, (2) Regular commits, save progress, (3) Pull main frequently, stay updated, reduce conflicts, (4) Clear descriptions, help reviewers understand changes.
How does continuous integration and deployment (CI/CD) work?
CI/CD automates testing and deployment. Continuous Integration: (1) Developer pushes code, (2) CI server (GitHub Actions, GitLab CI, Jenkins) automatically runs: builds code, runs tests, checks code quality, (3) Results reported, green checkmark or red X on pull request, (4) Prevents merging broken code. Continuous Deployment: (1) Code merged to main branch, (2) CI/CD automatically: builds production artifact, runs tests again, deploys to staging, runs integration tests, deploys to production (or waits for approval), (3) Monitor for issues. Pipeline stages: (1) Build, compile code, install dependencies, (2) Test, unit tests, integration tests, (3) Quality checks, linting, security scanning, (4) Deploy to staging, test in production-like environment, (5) Deploy to production, release to users. Benefits: (1) Fast feedback, know immediately if something breaks, (2) Consistency, same process every time, (3) Confidence, automated tests catch issues, (4) Speed, deploy many times daily, (5) Reduced risk, small changes easier to fix than big releases. Configuration: YAML files defining pipeline steps. Most platforms: GitHub Actions, GitLab CI, CircleCI, Travis CI. Modern development: CI/CD is standard, manual deployment rare.
What does an effective code review process look like?
Code review process: (1) Author submits pull request, describes changes, links to ticket, (2) Automated checks run, tests, linting, build, (3) Reviewer assigned, teammate examines code, (4) Review feedback, comments, questions, suggestions, (5) Discussion, clarify intent, debate approaches, (6) Revisions, author addresses feedback, (7) Approval, reviewer signs off, (8) Merge, changes integrated. What to review: (1) Correctness, does it work, handle edge cases?, (2) Tests, are there tests, do they cover important cases?, (3) Design, is structure sound, maintainable?, (4) Readability, can you understand it?, (5) Security, any vulnerabilities?, (6) Performance, obvious inefficiencies? Good reviews: (1) Timely, review within hours not days, (2) Thorough but focused, critical issues vs nitpicks, (3) Constructive, explain why, suggest alternatives, (4) Questions not commands, ‘Have you considered…’ vs ‘Do this’, (5) Praise good work, recognize cleverness, clarity. Good authors: (1) Small PRs, easier to review, (2) Clear description, explain what and why, (3) Self-review, check your own code first, (4) Responsive, address feedback promptly, (5) Open to feedback, don’t be defensive. Culture matters: psychological safety, learning mindset, shared ownership.
How do remote and distributed teams coordinate development work?
Remote coordination: (1) Asynchronous communication default, written updates, documentation, clear commit messages, (2) Synchronous for complex issues, video calls when needed, (3) Overlap hours, coordinate work when timezones overlap, (4) Clear documentation, don’t rely on verbal explanations. Communication tools: (1) Slack/Teams, quick questions, updates, (2) GitHub/GitLab, code review, technical discussion, (3) Jira/Linear, track tasks, priorities, (4) Confluence/Notion, documentation, decisions, (5) Zoom/Meet, video calls, pair programming. Workflow adaptations: (1) Written standups, async updates in Slack, (2) Recorded demos, watch when convenient, (3) Clear task descriptions, less back-and-forth needed, (4) Decision documentation, write down important decisions, (5) Time-boxing meetings, respect time zones. Challenges: (1) Time zones, limited overlap, (2) Communication gaps, miss context, (3) Isolation, lack of social connection, (4) Knowledge silos, harder to share informally. Solutions: (1) Over-communicate, write more than you think needed, (2) Document everything, don’t assume shared context, (3) Regular video, build relationships, (4) Clear ownership, who’s responsible for what, (5) Respect boundaries, don’t expect instant responses. Remote-first companies: default to distributed practices even if some colocated.
What is pair programming and when is it useful?
Pair programming: two developers work together at one computer. Roles: (1) Driver, types code, implements ideas, (2) Navigator, reviews, suggests direction, thinks strategically. Switch roles regularly (every 15-30 minutes). Benefits: (1) Knowledge sharing, learn from each other, (2) Fewer bugs, real-time review, (3) Better design, discuss approaches immediately, (4) Focus, less distraction with partner, (5) Onboarding, effective for teaching new developers, (6) Complex problems, two perspectives better than one. When useful: (1) Complex features, architecture decisions, (2) Bug hunting, difficult debugging, (3) Learning, junior with senior, (4) Onboarding, new team member learning codebase, (5) Critical code, high-importance, high-risk. When not needed: (1) Simple tasks, straightforward implementations, (2) Research, exploring alone faster, (3) Different work styles, some prefer solo time. Remote pairing: screen sharing, VS Code Live Share, Tuple. Variations: (1) Ping-pong, one writes test, other implements, swap, (2) Strong-style, navigator tells driver what to type, (3) Mob programming, whole team works together. Tradeoffs: two people on one task seems inefficient, but quality and learning benefits often outweigh. Not all day every day, exhaust concentration. Use strategically.
How do you manage technical debt in development workflows?
Technical debt management: (1) Make visible, track in backlog, label issues, (2) Prioritize strategically, balance new features with cleanup, (3) Regular paydown, allocate time each sprint, (4) Don’t accumulate faster than paying, sustainable pace, (5) Refactor continuously, small improvements constantly. Tracking: (1) Tech debt backlog, dedicated list, (2) Code comments, TODO, FIXME markers, (3) Documentation, architectural decision records noting tradeoffs, (4) Metrics, code quality scores, test coverage. Prioritization: (1) Impact, what’s slowing team most?, (2) Risk, what could break badly?, (3) Coupling, what blocks other work?, (4) Learning, what would teach team most? Paydown approaches: (1) Boy Scout Rule, leave code better than found, (2) Dedicated sprints, occasional cleanup sprint, (3) 20% time, allocate percentage to improvements, (4) Strategic refactoring, before adding related features. Prevention: (1) Code review, catch issues early, (2) Definition of done, includes tests, documentation, (3) No shortcuts without tracking, deliberate debt only, (4) Refactor before hard to change, don’t let complexity accumulate. Balance: some debt acceptable, ship quickly, learn, then improve. Too much debt: velocity drops, bugs increase, developers frustrated. Sustainable pace: accumulate debt strategically, pay down regularly, never let it paralyze development.