Information: In the summer of 1948, a 32-year-old mathematician named Claude Shannon submitted a paper to the Bell System Technical Journal. Shannon had been working at Bell Labs, the research arm of AT&T, whose core practical problem was figuring out how to transmit more telephone calls through the same physical cables with fewer errors.
But Shannon's paper - "A Mathematical Theory of Communication" - was not primarily an engineering document.
It was a mathematical theory of the most fundamental kind, one that set out to answer a question that had never been rigorously posed: what is information, and how do you measure it?
Shannon's answer was revolutionary in its simplicity. Information, he argued, is not about meaning. Whether a message says "I love you" or "the stock opened at 43" is irrelevant to the information it contains. What matters is surprise - uncertainty reduced.
A message is informative to the extent that it tells you something you did not already know. A completely predictable message - one whose content you could have guessed before receiving it - carries no information at all.
Shannon quantified this intuition precisely, in terms of probability, and derived a unit of measurement: the bit, the answer to a single yes/no question with equal probability. From this foundation, Shannon derived theorems that still astonish in their scope.
He showed that any data source could be compressed to a minimum size determined by its statistical structure, and no further. He showed that any noisy communication channel has a definite maximum transmission rate - the Shannon limit - and that this rate is achievable with suitable encoding.
He showed that error correction is not only possible but, with enough redundancy, can make communication arbitrarily reliable over a noisy channel.
The 1948 paper is 77 pages long. It established information theory as a mathematical discipline.
It also, in a real sense, established the conceptual foundation for everything that followed in the digital age: every computer, every internet protocol, every compressed audio and video stream, every error-correcting code in a hard drive or satellite link, and the mathematical tools of modern artificial intelligence.
Not bad for a summer project.
"The fundamental problem of communication is that of reproducing at one point either exactly or approximately a message selected at another point." - Claude Shannon, A Mathematical Theory of Communication (1948)
Key Definitions
Information: In Shannon's framework, the reduction of uncertainty about a message source; quantified as -log2(p) bits for an event with probability p.
Bit: The basic unit of information; the amount of information required to resolve a single yes/no question with equal probability; physically, a binary digit taking value 0 or 1.
Entropy (H): The average information content per symbol from a source, defined as H = -sum of p(x) log2(p(x)); measures the source's unpredictability or the minimum average number of bits per symbol needed to encode it.
Channel capacity (C): The maximum rate at which information can be reliably transmitted over a noisy channel; Shannon's channel coding theorem proves this limit exists and is achievable.
Error-correcting code: An encoding scheme that adds redundant information to a message so that errors introduced by a noisy channel can be detected and corrected.
Data compression: The reduction of the number of bits needed to represent data, either losslessly (exact reconstruction) or with loss (approximate reconstruction exploiting perceptual or statistical limits).
Kolmogorov complexity: The length of the shortest computer program that can generate a given string; related to but distinct from Shannon entropy, measuring the compressibility of individual objects rather than sources.
Landauer's principle: The physical law stating that erasing one bit of information releases a minimum of kT ln 2 joules of heat, connecting information theory to thermodynamics.
Information Theory's Core Results
| Theorem / concept | What it states | Practical implication | Application |
|---|---|---|---|
| Source coding theorem (Shannon, 1948) | Data can be losslessly compressed to a minimum of H bits per symbol (entropy); no more compression is possible | Sets the theoretical floor for file compression | ZIP, gzip, Huffman coding, LZ77 |
| Channel capacity theorem (Shannon, 1948) | Every noisy channel has a maximum reliable data rate C = B log2(1 + S/N) (Shannon-Hartley) | Sets the ceiling for communication speed over any medium | Wi-Fi standards, 5G design, fiber optic protocols |
| Noisy channel coding theorem | Reliable transmission over any noisy channel is possible at rates below capacity with suitable error-correcting codes | Error correction is always possible; we don't have to accept errors | Hard drive ECC, satellite codes, QR codes, Reed-Solomon |
| Landauer's principle (1961) | Erasing 1 bit of information releases a minimum of kT ln 2 ? 3 � 10^-21 joules at room temperature | Computing has an irreducible physical energy cost tied to information erasure | Thermodynamic limits on computing; reversible computing research |
| Data compression bound | Entropy H is both a lower bound (cannot compress more) and achievable bound (Huffman, arithmetic coding approach H) | Tells engineers when compression is near-optimal | JPEG, MP3, video codecs: exploit source statistics |
| Mutual information I(X;Y) | Measures how much knowing one variable reduces uncertainty about another | Quantifies the information channel actually transmits | Channel equalization, feature selection in ML, neuroscience |
| Kolmogorov complexity | Shortest program that generates a string; measures individual object compressibility | Most strings are incompressible; random sequences are their own shortest description | Randomness testing; theoretical computer science |
Shannon's Founding Insight: Information as Surprise
The Problem Before Shannon
Before 1948, there was no mathematical framework for thinking about information transmission. Engineers at Bell Labs and elsewhere had developed practical techniques for telephony and telegraphy, but these were empirical and specific to particular systems.
There was no general theory that could answer basic questions: how much information is contained in an English text, compared to a random sequence of characters? What is the maximum information that can flow through a telephone wire in a given bandwidth? How much redundancy is needed to achieve reliable transmission over a noisy line?
The conceptual difficulty was that "information" seemed inherently semantic - tied to meaning, and meaning seemed impossible to quantify. Shannon's breakthrough was to cleanly separate information from meaning. The receiver of a message does not need to interpret it for the theory to apply.
All that matters is whether the message was one of many possible messages, and how probable each possibility was. A communication system's job is to faithfully reproduce a sequence of symbols at the receiver; what those symbols mean is a separate problem, outside information theory.
Measuring Surprise
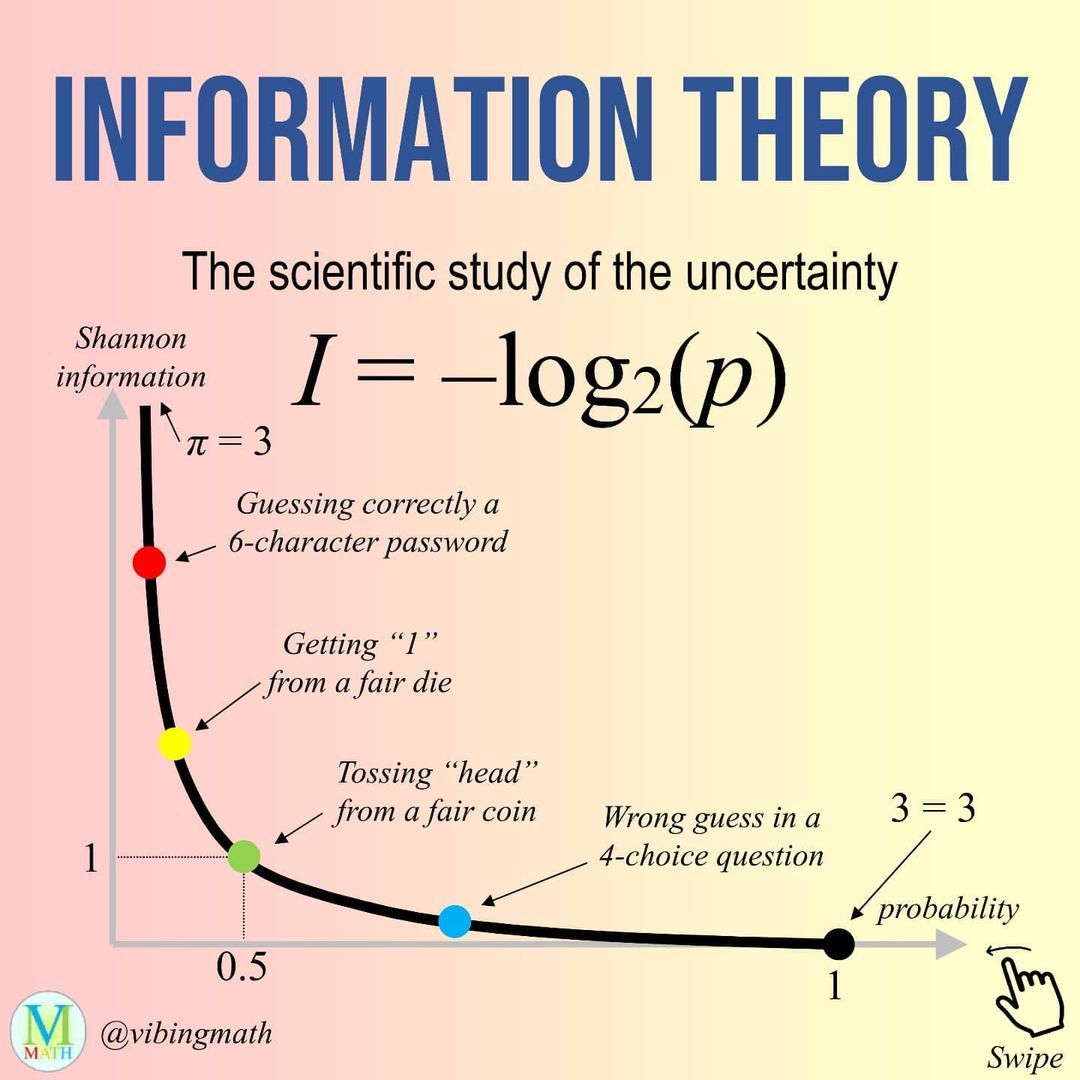
Shannon's measure of the information carried by an event with probability p is:
I(p) = -log2(p) bits
This formula has intuitive properties. An event with probability 1 (a certainty) carries 0 bits of information - you knew it would happen. An event with probability 1/2 carries 1 bit - it resolved one fair binary question. An event with probability 1/4 carries 2 bits.
The rarer the event, the more surprising it is when it occurs, and the more information it carries. The logarithm ensures that the information in two independent events adds up: if event A carries 3 bits and event B (independent of A) carries 4 bits, the joint event carries 7 bits.
For a source that generates symbols from a probability distribution - a language that outputs letters, a sensor that outputs measurements, a gene that encodes nucleotides - the average information per symbol is the entropy:
H = -sum of p(x) log2(p(x))
This is maximized when all symbols are equally probable (maximum uncertainty, maximum average information per symbol) and is zero when one symbol is certain (no uncertainty, no information). A fair coin flip has entropy 1 bit. A biased coin (90% heads, 10% tails) has entropy of about 0.47 bits.
English text has entropy estimated at about 1 to 1.5 bits per character, far below the 4.7 bits that log2(26) = 4.7 would suggest if all letters were equally probable - reflecting the high redundancy of natural language.
Compressing Data: The Source Coding Theorem
Shannon's source coding theorem states that the minimum average number of bits per symbol required to encode a source, using lossless compression, is exactly the entropy H of the source. This is both a lower bound (you cannot do better than H bits per symbol on average) and an achievable bound (you can get as close to H as desired).
Huffman Coding
The most intuitive compression scheme is Huffman coding, invented by David Huffman in 1952. Huffman coding assigns variable-length binary codes to symbols: frequent symbols get short codes, rare symbols get long codes.
In English, the letter 'e' (frequency about 12%) gets a short code; 'q' (frequency about 0.1%) gets a long code.
By matching code length to frequency (code length approximately -log2(p) for symbol with probability p), Huffman coding approaches the entropy bound. Every ZIP file, every file compressed with gzip, ultimately uses variants of this idea.
Lempel-Ziv and Universal Compression
Huffman coding requires knowing the source's probability distribution in advance. Abraham Lempel and Jacob Ziv's 1977 algorithm (LZ77 and LZ78) is universal: it adapts to any source's statistical structure by building a dictionary of repeated patterns found in the data.
The gzip and ZIP formats are based on derivatives of Lempel-Ziv. The insight is that any source with statistical structure - repeated patterns, predictable sequences - can be compressed without prior knowledge of the distribution, simply by exploiting recurrent substrings.
Lossy Compression: JPEG and MP3
When exact reconstruction is not required - as in photography or audio - lossy compression can achieve much higher ratios by discarding information that human perception cannot detect.
JPEG compression exploits two properties of human vision: that the eye is less sensitive to color variation than to brightness variation, and that high-frequency spatial variation (fine texture) is less salient than low-frequency variation (coarse structure).
It transforms image blocks into frequency components using a discrete cosine transform and then quantizes the higher-frequency components more aggressively.
MP3 audio compression exploits auditory masking: sounds that are temporally or spectrally close to louder sounds are inaudible and can be discarded. Both approaches represent the application of perceptual psychology to information theory.
Reliable Communication: The Channel Coding Theorem
Shannon's most surprising theorem concerns communication over noisy channels. A channel is any physical medium through which information passes - a telephone wire, a radio link, a magnetic recording track - that introduces random errors.
The channel capacity C is the maximum rate (in bits per second) at which information can be transmitted with an error probability that can be made arbitrarily small. Shannon proved:
- If you transmit at any rate below capacity, there exist encoding schemes that make the error probability as small as you like.
- If you transmit at any rate above capacity, errors are unavoidable regardless of the encoding.
This was counterintuitive and profound. Engineers had assumed that noise imposed a hard limit on accuracy - that faster transmission meant more errors, period. Shannon showed that this tradeoff could be almost eliminated with the right encoding, at any rate below capacity.
The result did not tell engineers how to build such codes; finding efficient codes that approach the Shannon limit became the central practical problem of coding theory.
The Hamming Code
Richard Hamming at Bell Labs built the first practical single-error-correcting code in 1950. He was motivated directly by experience: his punch-card calculations on Bell Labs' relay computers would occasionally be ruined by a single flipped bit, requiring him to restart jobs on the weekend.
The Hamming(7,4) code adds 3 check bits to 4 data bits such that any single bit error changes a unique pattern of check bits, identifying the position of the error precisely. The code rate is 4/7 - roughly 57% efficiency - acceptable for many applications.
Reed-Solomon and Beyond
Reed-Solomon codes, developed in 1960, can correct bursts of multiple consecutive errors and are used in CDs, DVDs, Blu-ray discs, hard drives, QR codes, and deep-space communications from the Voyager probes.
Turbo codes (1993) and low-density parity-check (LDPC) codes, independently discovered in the 1960s and rediscovered in the 1990s, approach within a fraction of a decibel of the Shannon limit and are used in 4G and 5G mobile communications.
The theoretical gap between the Shannon limit and achievable performance has narrowed dramatically over seventy years of coding theory development.
Kolmogorov Complexity: Information in Individual Objects
Shannon's entropy measures the average information per symbol from a statistical source. A different but related concept - Kolmogorov complexity, developed independently by Andrei Kolmogorov, Ray Solomonoff, and Gregory Chaitin in the 1960s - measures the information content of individual strings.
The Kolmogorov complexity K(s) of a string s is the length of the shortest computer program that outputs s.
A string of a million identical zeros has very low Kolmogorov complexity - the program is short: "print '0' a million times." A random-looking string has Kolmogorov complexity approximately equal to its own length, because there is no shorter description.
Kolmogorov complexity is not computable (you cannot algorithmically find the shortest program for an arbitrary string), which limits its direct engineering applications.
But it provides a powerful conceptual framework: the "minimum description length" principle, a version of Occam's razor in information-theoretic terms, is that the best model for data is the one that most compresses it.
This principle underpins important approaches to statistical inference and machine learning.
Information Theory in Biology
DNA is the most compact information storage medium yet discovered. The genetic code uses four nucleotides (adenine, guanine, cytosine, thymine/uracil), and since each has probability approximately 1/4, each base pair encodes approximately log2(4) = 2 bits of information.
The human genome contains approximately 3.2 billion base pairs, representing roughly 6.4 gigabits or about 800 megabytes of information - comparable to a CD-ROM. In practice, the effective information content is lower because much of the genome is repetitive, and the entropy is well below 2 bits per base.
This analysis raises immediate evolutionary questions. How much information does natural selection add to genomes per generation? How efficiently are genes encoded relative to the Shannon limit for protein-specifying codes? How is biological information maintained against the noise of mutation and replication errors?
The fidelity of DNA replication is extraordinary: the error rate of DNA polymerase is roughly one error per billion bases copied, before proofreading mechanisms are applied. This is already close to the limits set by the physical noise of the cellular environment.
The efficient coding hypothesis in sensory neuroscience proposes that neural systems encode sensory information efficiently - compressing inputs to remove statistical redundancies and maximizing the information transmitted per neural spike.
Horace Barlow's 1961 proposal that retinal ganglion cells perform efficient coding of visual information has been extensively tested and partially confirmed.
The center-surround receptive fields of retinal neurons perform a spatial decorrelation that removes predictable structure from natural images, consistent with efficient coding principles.
Information Theory and Physics
Landauer's Principle
In 1961, Rolf Landauer at IBM published an analysis showing that the erasure of one bit of information in a physical system necessarily releases a minimum amount of energy: kT ln 2, where k is Boltzmann's constant and T is the temperature in Kelvin.
At room temperature, this is approximately 3 x 10^-21 joules - tiny, but real and measurable. Modern computers consume vastly more energy per bit operation than the Landauer limit, but as transistors shrink toward atomic scales, this limit becomes increasingly relevant.
Landauer's principle has a striking implication: information is physical. Computation is not abstract symbol manipulation but a physical process subject to thermodynamic constraints.
Charles Bennett showed that logically reversible computation - computation that does not erase any information - could avoid the Landauer energy cost, leading to the study of reversible computing and quantum computing.
The Black Hole Information Paradox
Stephen Hawking's 1974 discovery that black holes emit thermal radiation and slowly evaporate created one of the deepest puzzles in theoretical physics. Thermal (Hawking) radiation is random - it carries no information about the matter that originally formed the black hole.
If a black hole evaporates completely, the information in the original matter appears to have been destroyed. But the laws of quantum mechanics require that physical evolution is unitary - reversible - and information is conserved. This contradiction is the black hole information paradox.
The resolution has been sought for fifty years. The holographic principle, emerging from string theory and the AdS/CFT correspondence discovered by Juan Maldacena in 1997, proposes that the information of a volume of space is encoded on its boundary surface - analogous to a hologram that encodes a 3D image on a 2D surface.
This suggests information escapes from black holes in subtle correlations in the Hawking radiation. John Wheeler's phrase "it from bit" captures the most radical implication: that the fundamental description of physical reality may be informational rather than material.
Information Theory in Machine Learning and AI
The influence of information theory on contemporary AI is pervasive.
Cross-entropy loss, the most commonly used loss function for classification, measures the information divergence between the true label distribution and the model's predicted distribution. Minimizing cross-entropy is equivalent to maximizing the likelihood of the data under the model.
The categorical cross-entropy loss for a classifier is H(y, p) = -sum of y(i) log p(i), where y is the one-hot true label and p is the predicted probability distribution.
The Kullback-Leibler divergence D_KL(P || Q) measures how much information is lost when the distribution Q is used to approximate P.
It appears throughout Bayesian deep learning: in variational autoencoders, the loss function includes a KL divergence term between the learned latent distribution and a prior, which acts as a regularizer.
In reinforcement learning, KL constraints are used in proximal policy optimization to prevent large policy updates.
The information bottleneck theory (Tishby and Schwartz-Ziv, 2017) proposed that deep neural networks can be understood as learning to compress their inputs while retaining information relevant to the output variable.
This information-theoretic framework for understanding neural network representations has generated substantial research and debate.
Mutual information between random variables X and Y measures how much knowing X reduces uncertainty about Y: I(X;Y) = H(X) + H(Y) - H(X,Y).
Mutual information is used in feature selection (choosing features that are informative about the target), representation learning (learning representations that capture relevant information), and neuroscience (measuring how much neural activity conveys about stimuli).
The Limits of Information Theory
Shannon's theory is spectacularly successful within its domain. But it is worth noting what it does not address.
Shannon explicitly bracketed the question of meaning: information theory measures syntactic information (the statistical structure of symbols) but says nothing about semantic information (what symbols mean) or pragmatic information (what difference it makes).
A book of mathematical theorems and a book of nonsense of the same length carry the same amount of information in Shannon's framework if they have the same statistical structure.
The question of how meaning arises from the physical manipulation of symbols - the relationship between information in Shannon's sense and the kind of information that supports cognition, understanding, and communication - is an open philosophical problem.
Information theory provides the engineering foundations for the digital world; the questions of what digital systems mean and what they understand remain unsettled.
Sources & Further Reading
- Shannon, C. E. (1948). A mathematical theory of communication. Bell System Technical Journal, 27(3), 379-423. DOI: 10.1002/j.1538-7305.1948.tb01338.x
- Shannon, C. E., & Weaver, W. (1949). The Mathematical Theory of Communication. University of Illinois Press.
- Huffman, D. A. (1952). A method for the construction of minimum-redundancy codes. Proceedings of the IRE, 40(9), 1098-1101. DOI: 10.1109/JRPROC.1952.273898
- Ziv, J., & Lempel, A. (1977). A universal algorithm for sequential data compression. IEEE Transactions on Information Theory, 23(3), 337-343. DOI: 10.1109/TIT.1977.1055714
- Hamming, R. W. (1950). Error detecting and error correcting codes. Bell System Technical Journal, 29(2), 147-160. DOI: 10.1002/j.1538-7305.1950.tb00463.x
- Landauer, R. (1961). Irreversibility and heat generation in the computing process. IBM Journal of Research and Development, 5(3), 183-191. DOI: 10.1147/rd.53.0183
- Hawking, S. W. (1974). Black hole explosions? Nature, 248, 30-31. DOI: 10.1038/248030a0
- Kolmogorov, A. N. (1965). Three approaches to the quantitative definition of information. Problems of Information Transmission, 1(1), 1-7.
- Tishby, N., Pereira, F. C., & Bialek, W. (2000). The information bottleneck method. Proceedings of the 37th Allerton Conference.View source
- Cover, T. M., & Thomas, J. A. (2006). Elements of Information Theory (2nd ed.). Wiley-Interscience. DOI: 10.1002/047174882X
Related Articles
Frequently Asked Questions
What is information theory and why does it matter?
Information theory is the mathematical study of information: how it can be quantified, stored, transmitted, and processed. It was founded by Claude Shannon in a landmark 1948 paper, ‘A Mathematical Theory of Communication,’ published in the Bell System Technical Journal. Before Shannon, there was no precise, mathematical answer to questions like: how much information is in a message? How efficiently can a message be compressed without losing content? How much information can a noisy channel reliably transmit? Shannon answered all three questions with mathematical precision, and the answers were foundational for everything that followed in the digital age. Shannon’s framework established the bit as the basic unit of information and showed how the minimum amount of information needed to describe a source depends on the probability distribution of its outputs, what he called the entropy of the source. He proved that data from any source can be compressed close to this minimum entropy limit, and no further. He proved that even a noisy communication channel has a definite capacity, the Shannon limit, and that with suitable error-correcting codes, information can be transmitted at any rate below this capacity with arbitrarily small error probability. These results were not just theoretical: they directly enabled digital communications, the internet, satellite communication, mobile phones, digital audio and video compression, and modern cryptography. Without information theory, the digital world as it exists would not be possible. The theory has also had profound applications in biology (understanding DNA as an information storage system), physics (connecting information to thermodynamics), and machine learning (information-theoretic measures are central to modern AI).
How do you measure information?
Shannon’s key insight was to define information in terms of surprise or uncertainty reduction. A message carries information to the extent that it reduces uncertainty about something. A message that tells you something you already knew, the Sun rose this morning, carries no information. A message that tells you something unexpected carries a great deal. More precisely, Shannon defined the information content of an event with probability p as -log2(p) bits. The base-2 logarithm is natural when encoding with binary digits (bits). An event with probability 1⁄2 carries exactly 1 bit of information, it resolves one yes/no question. An event with probability 1⁄4 carries 2 bits (it resolves two yes/no questions). An event with probability 1⁄8 carries 3 bits. The key property is that the information content of two independent events is the sum of their individual information contents, a requirement that uniquely determines the logarithmic formula. For a source that produces symbols from a probability distribution, the average information per symbol, the entropy H, is H = -sum of p(x) times log2(p(x)) over all possible symbols x. Entropy is maximized when all symbols are equally probable (maximum uncertainty) and minimized when one symbol is certain (no uncertainty, no information). English text has an entropy of approximately 1 bit per character, rather than the 4.7 bits that would be required if all 26 letters were equally probable, meaning English text is highly redundant, which is why it can be compressed significantly. This entropy bound is a theoretical floor: no lossless compression scheme can achieve compression better than the entropy of the source.
What is entropy in information theory?
In information theory, entropy is the measure of uncertainty, unpredictability, or average information content in a source. It is defined mathematically as H = -sum of p(x) log2(p(x)), where the sum is over all possible values x and p(x) is the probability of each value. Intuitively, entropy measures how surprised you expect to be by the next symbol from the source. A coin flip has entropy of 1 bit, maximum for a binary source, since both outcomes are equally likely. A biased coin that comes up heads 90% of the time has lower entropy: you can usually predict the next flip correctly, so each flip carries less information on average. The connection to thermodynamic entropy in physics is not coincidental. Shannon was aware of the parallel and, famously, was advised by John von Neumann to call his measure ‘entropy’ partly because the same formula appeared in statistical mechanics. The connection is real: Landauer’s principle shows that erasing one bit of information must release at least kT ln 2 joules of heat, directly linking information entropy to thermodynamic entropy. Entropy is central to a number of practical applications beyond compression. In machine learning, cross-entropy loss measures the difference between a predicted probability distribution and the true distribution, and minimizing it is equivalent to maximizing the likelihood of the data. The KL divergence (Kullback-Leibler divergence) measures how one probability distribution diverges from a reference distribution and is used extensively in variational inference and other statistical methods. Differential entropy extends the concept to continuous distributions, though with some additional subtleties.
How do error-correcting codes work?
One of Shannon’s most important results was the channel coding theorem, which proved that for any noisy communication channel with capacity C, it is possible to transmit information at any rate below C with an error probability that can be made arbitrarily small, by using suitable error-correcting codes. Shannon proved the existence of good codes but did not construct them; building efficient error-correcting codes became a major practical engineering challenge. Richard Hamming at Bell Labs built the first practical error-correcting code in 1950, motivated by the frustrating experience of having punch-card calculations ruined by single-bit errors on the Bell Labs computers. The Hamming code works by adding redundant check bits to a message such that any single-bit error can be detected and corrected. The insight is to add bits at positions that are powers of 2, each checking a specific subset of the other bits. If an error occurs, the pattern of failed checks identifies the exact position of the erroneous bit, which can then be flipped. More powerful codes, Reed-Solomon codes, convolutional codes, Turbo codes, LDPC codes, have been developed for more challenging applications. Reed-Solomon codes are used in CDs, DVDs, hard drives, and QR codes. They can correct bursts of errors (multiple consecutive corrupted bits), which is the typical pattern in physical storage. Turbo codes and LDPC (low-density parity-check) codes, developed in the 1990s and 2000s, approach the Shannon limit very closely and are used in 4G/5G mobile communications and satellite links. The mathematical theory of error correction involves finite field algebra, combinatorics, and graph theory, a rich field that continues to develop.
What is the connection between information and physics?
The connection between information theory and physics turned out to be far deeper than Shannon himself expected when he borrowed the term ‘entropy’ from thermodynamics. Rolf Landauer proved in 1961 that erasing one bit of information necessarily releases a minimum amount of heat equal to kT ln 2, where k is Boltzmann’s constant and T is the temperature. This Landauer limit is a fundamental physical consequence of the second law of thermodynamics, not just an engineering constraint. It means that computation has a thermodynamic cost: information is not abstract but physical. Charles Bennett showed in the 1970s that logically reversible computation, computation that does not erase information, could in principle be performed with arbitrarily little energy, giving rise to the study of reversible computing and its connection to the physics of computation. The most dramatic manifestation of information in physics is the black hole information paradox. Stephen Hawking showed in 1974 that black holes emit thermal radiation (Hawking radiation) and slowly evaporate. If a black hole evaporates completely, what happens to the information contained in the matter that formed it? Thermal radiation is random, it carries no information. This appears to violate quantum mechanics, which requires that quantum evolution is reversible and information is conserved. The paradox has generated decades of debate. String theory’s holographic principle, developed by Juan Maldacena and others, suggests that the information of a volume of space is encoded on its boundary surface, a result that may resolve the paradox. John Wheeler’s phrase ‘it from bit’ captures the most radical view: that physical reality is fundamentally informational, that all physical entities are derivable from yes/no answers to binary questions.
How is information theory used in AI and machine learning?
Information theory is woven throughout modern machine learning and artificial intelligence. The maximum entropy principle, associated with E. T. Jaynes, holds that when estimating an unknown probability distribution given limited information, one should choose the distribution with maximum entropy consistent with the known constraints. This principle underlies maximum entropy models, including logistic regression, and is a principled basis for Bayesian inference. Cross-entropy loss is the most widely used loss function for classification tasks in deep learning. When a neural network outputs a probability distribution over classes, the cross-entropy between the true label distribution and the predicted distribution measures how well the model is performing. Minimizing cross-entropy is equivalent to maximizing the log-likelihood of the data. The Kullback-Leibler divergence appears throughout Bayesian deep learning and generative models: variational autoencoders minimize a loss that includes a KL divergence term regularizing the learned latent representations. Mutual information, which measures how much information one random variable contains about another, is used in feature selection, representation learning, and the information bottleneck method (Tishby et al., 2000), which proposes understanding neural networks as implementing a compression of inputs that retains only information relevant to the output. Data compression algorithms, Huffman coding, arithmetic coding, Lempel-Ziv, are directly applied in storing and transmitting the large datasets and model weights required by modern AI systems. Information geometry, developed by Shun-ichi Amari, applies differential geometry to probability distributions and provides theoretical tools for understanding optimization on probability manifolds, with applications in neural network training.