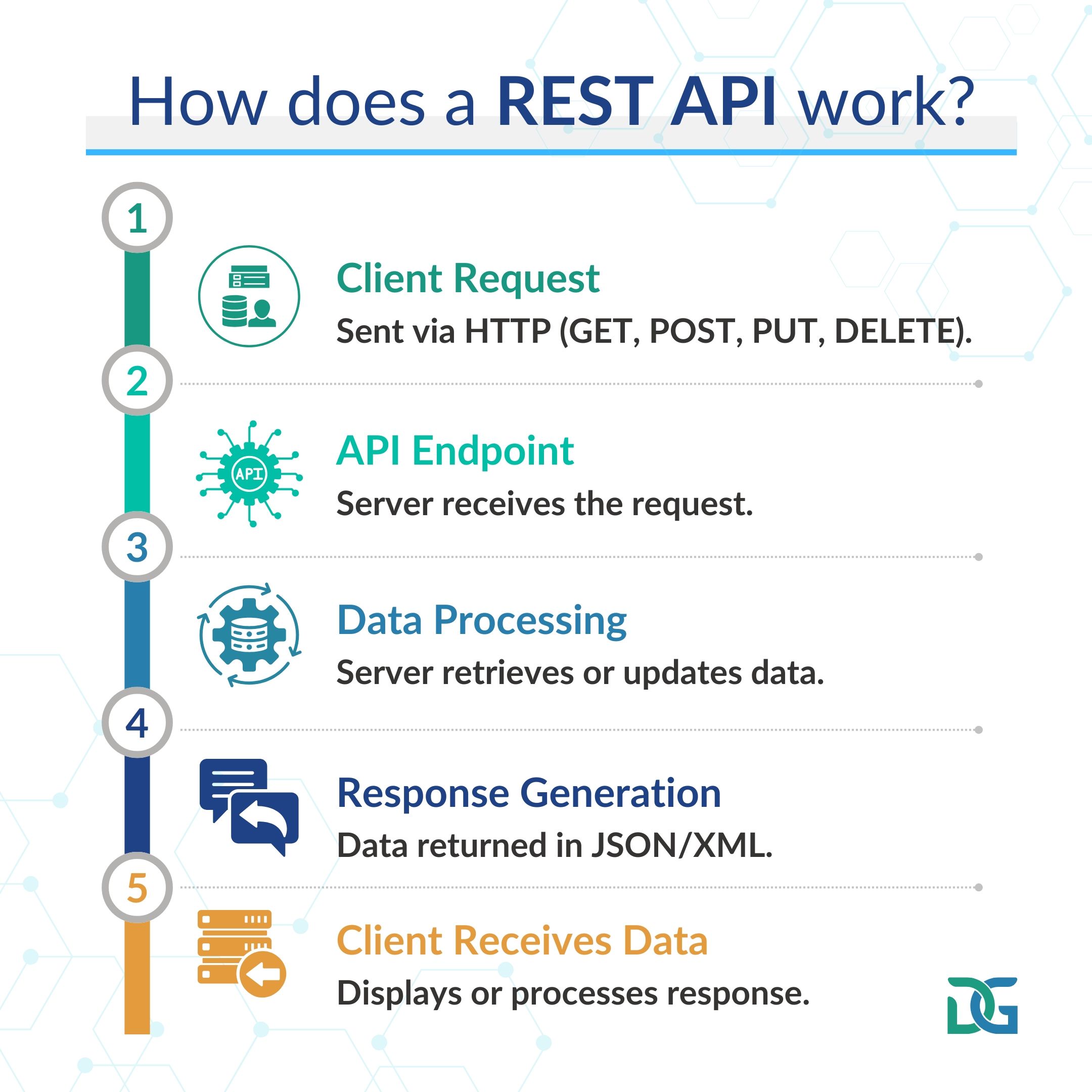
Understanding: A REST API (Representational State Transfer Application Programming Interface) is a way for software systems to communicate with each other over the internet using a standardized set of conventions built on top of HTTP - the same protocol your browser uses to load web pages.
When you open a weather app and see current conditions for your city, the app is asking a remote server for that data through a REST API. When you post a photo on a social platform, your device sends that photo to the platform's servers through a REST API.
When an e-commerce site confirms your order and charges your card, it is communicating with a payment processor's system through a REST API in real time.
REST is not a protocol, a tool, or a formal specification. It is an architectural style: a set of constraints for how distributed systems should be designed to communicate reliably, scalably, and simply over HTTP.
Understanding REST means understanding how the modern web actually works - because REST APIs are the connective tissue that holds nearly every digital product and service together.
According to a 2023 survey by Postman (the API development platform used by over 30 million developers), 89 percent of developers reported using REST APIs in their work, making REST the dominant API architecture by a wide margin.
RapidAPI's 2023 State of APIs Report found that the number of publicly available APIs exceeded 30,000, the vast majority of them RESTful.
"The key abstraction of information in REST is a resource. Any information that can be named can be a resource." - Roy Fielding, Architectural Styles and the Design of Network-based Software Architectures (2000)
The Origins: Roy Fielding's Dissertation
REST was defined in 2000 by Roy Fielding in his doctoral dissertation at the University of California, Irvine, titled Architectural Styles and the Design of Network-based Software Architectures.
Fielding was not working in the abstract - he was one of the principal authors of the HTTP/1.1 specification (RFC 2616) and a co-founder of the Apache HTTP Server project.
He had spent years building the infrastructure of the web and was trying to articulate the architectural principles that had made the World Wide Web scale so successfully.
Fielding's insight was that the web worked as well as it did because of specific constraints: the way HTTP operated, the way URLs identified resources, the way responses could be cached and layered through intermediaries.
He formalized these observations as a set of six architectural constraints that, if applied consistently to API design, would produce systems with the same desirable properties the web exhibited - scalability, simplicity, loose coupling, and visibility.
Those constraints became REST, and they have since been applied to build the APIs that power virtually every digital product and service.
Fielding's dissertation has been cited over 12,000 times according to Google Scholar and remains the definitive reference for understanding what REST actually means - as opposed to the loose, colloquial usage the term has acquired in industry practice.
It is worth noting that many APIs described as "RESTful" in practice do not fully implement Fielding's constraints. The term has become somewhat diluted in common usage to mean any HTTP-based API that uses JSON and standard HTTP methods.
Fielding himself has written critically about this dilution, arguing that APIs that do not implement hypermedia controls (HATEOAS) should not be called RESTful.
The Six REST Constraints
Fielding defined six constraints that characterize a REST architecture. Not all REST-style APIs implement all of them perfectly, but understanding them clarifies what REST is trying to achieve and why it works as well as it does.
1. Client-Server Architecture
The client (a browser, mobile app, or other API consumer) and the server (which stores and manages data) are separated. The client is responsible for the user interface; the server is responsible for data storage and business logic. Neither knows the internal implementation details of the other.
This separation allows each side to evolve independently. A mobile app can be redesigned without changing the server. The server's database can be migrated from PostgreSQL to MongoDB without the client noticing, as long as the API contract between them remains consistent.
This independence is what makes it possible for a single API to serve a web application, a mobile app, a third-party integration, and an internal analytics dashboard simultaneously.
2. Statelessness
Statelessness is the most operationally significant REST constraint. It means that each request from a client to a server must contain all of the information the server needs to process it. The server does not store any client context between requests.
No session state. No "remember who I am from the last request." If authentication is required, the credentials or token must be sent with every request. If context is needed - which page of results, what filter is applied, what language to respond in - it must be encoded in the request itself.
This constraint has profound implications for scalability. Because no server needs to remember which client it has been talking to, any server instance in a cluster can handle any request.
Add more servers, and you can handle more requests - no shared session storage, no sticky sessions, no complex state synchronization required. This is why stateless architectures dominate cloud computing and why REST APIs scale so well behind load balancers.
Amazon's engineering blog (2023) reported that their internal services handle over 100 billion API calls per day, a scale made possible in large part by the stateless architecture of their service-to-service communication.
3. Cacheability
Responses should explicitly indicate whether they can be cached and for how long. Cached responses reduce server load and latency - often dramatically. HTTP already provides rich caching semantics through headers like Cache-Control, ETag, and Last-Modified, and REST leverages these fully.
A GET request for a product catalog might be cached for 60 minutes. A POST request to create an order should never be cached. A GET request for a user's profile might use an ETag so the client can check whether the data has changed without downloading it again.
Proper cache control headers communicate these policies to clients and to any intermediary caches (CDNs, reverse proxies) between them.
Akamai Technologies (2023) reported that effective caching strategies reduce origin server load by 60-80 percent for typical web applications - a reduction that translates directly into lower infrastructure costs and faster response times for users.
4. Uniform Interface
The uniform interface is what makes REST recognizable and interoperable across different systems, teams, and organizations. It means that all REST APIs follow the same conventions for identifying and manipulating resources:
- Resource identification: Every resource is identified by a URL (Uniform Resource Locator)
- Resource manipulation through representations: Clients interact with resources through representations - typically JSON documents - that contain enough information to modify or delete the resource
- Self-descriptive messages: Each request and response includes enough metadata (content type, status code, caching directives) to describe how to process it
- Hypermedia as the Engine of Application State (HATEOAS): Responses include links to related resources and available actions, allowing clients to navigate the API dynamically
HATEOAS is the most rarely implemented constraint in practice. Most real-world REST APIs return data without navigation links, requiring clients to construct URLs from documentation rather than discovering them from responses. This is the primary reason Fielding argues most "REST" APIs are not truly RESTful.
5. Layered System
A client cannot tell whether it is connected directly to the application server or communicating through an intermediary - a load balancer, a CDN, a caching proxy, an API gateway, or a security layer. This transparency allows intermediaries to be inserted and removed without affecting the client.
In practice, a typical API request might pass through Cloudflare (DDoS protection), an AWS Application Load Balancer (traffic distribution), an API gateway like Kong or AWS API Gateway (rate limiting, authentication), and finally reach the application server.
The client sends a single HTTP request and receives a single HTTP response, unaware of the layers between.
6. Code on Demand (Optional)
Servers can extend client functionality by sending executable code (like JavaScript) that the client runs. This is the only optional constraint. In practice, it applies mainly to web browsers (which receive and execute JavaScript from servers) rather than to typical API clients, which consume data rather than executable code.
Resources and URLs: The Nouns of REST
In REST, everything is a resource: a user, an order, a product, a message, an article, a payment. Resources are the nouns of the API. They are identified by URLs that follow predictable conventions.
Good REST URL design makes APIs intuitive and self-documenting:
GET /articles -> list all articles
GET /articles/42 -> get article with ID 42
POST /articles -> create a new article
PUT /articles/42 -> replace article 42 entirely
PATCH /articles/42 -> partially update article 42
DELETE /articles/42 -> delete article 42Resources can be nested to express relationships:
GET /users/7/orders -> all orders for user 7
GET /users/7/orders/12 -> order 12 belonging to user 7The URL identifies what the resource is. The HTTP method identifies what to do with it.
This separation of noun and verb is a core REST design principle and is what makes well-designed REST APIs readable even to people who have never seen the documentation.Naming conventions matter. The industry consensus, articulated in style guides from Google, Microsoft, and Stripe, is:
| Convention | Example | Why |
|---|---|---|
| Plural nouns for collections | /articles not /article | Collections contain multiple items |
| Lowercase with hyphens | /blog-posts not /blogPosts | URLs are case-sensitive; hyphens are readable |
| No verbs in URLs | /articles not /getArticles | The HTTP method provides the verb |
| Nesting for relationships | /users/7/orders | Expresses the parent-child relationship |
| Query parameters for filtering | /articles?status=published&sort=date | Keeps the URL structure clean |
HTTP Methods: The Verbs of REST
| Method | Purpose | Safe | Idempotent | Typical Response Code |
|---|---|---|---|---|
| GET | Retrieve a resource | Yes | Yes | 200 OK |
| POST | Create a new resource | No | No | 201 Created |
| PUT | Replace a resource entirely | No | Yes | 200 OK |
| PATCH | Partially update a resource | No | No* | 200 OK |
| DELETE | Remove a resource | No | Yes | 204 No Content |
| HEAD | Retrieve headers only (no body) | Yes | Yes | 200 OK |
| OPTIONS | List allowed methods for a resource | Yes | Yes | 200 OK |
Safe means the operation does not modify the resource - calling a safe method is a pure read with no side effects. Idempotent means calling the method multiple times has the same effect as calling it once.
These properties matter enormously for reliability: safe methods can be cached aggressively; idempotent methods can be retried on network failure without risk of creating duplicate records or corrupting data.
The GET/POST/PUT/DELETE pattern maps roughly to the classic database CRUD operations (Create, Read, Update, Delete), which is part of why REST feels intuitive to developers with database experience.
HTTP Status Codes: How Servers Respond
REST uses standard HTTP status codes to communicate what happened with each request.
A well-designed API uses these codes precisely rather than returning 200 OK for every response and encoding errors in the response body - a pattern sometimes called "200 OK with an error message," which breaks HTTP semantics and makes automated error handling unreliable.
| Code | Meaning | When to Use |
|---|---|---|
| 200 OK | Success | Successful GET, PUT, PATCH |
| 201 Created | Resource created | Successful POST that creates a new resource |
| 204 No Content | Success, no body | Successful DELETE |
| 301 Moved Permanently | Resource relocated | URL has permanently changed |
| 304 Not Modified | Cached version is current | Client's cached copy is still valid |
| 400 Bad Request | Client error in request | Malformed JSON, invalid parameters |
| 401 Unauthorized | Authentication required | Missing or expired token |
| 403 Forbidden | Authenticated but not permitted | Valid token but insufficient permissions |
| 404 Not Found | Resource does not exist | Wrong ID or URL |
| 409 Conflict | Resource conflict | Duplicate unique field, version conflict |
| 422 Unprocessable Entity | Validation failed | Valid JSON but business rules violated |
| 429 Too Many Requests | Rate limited | Client exceeding rate limit |
| 500 Internal Server Error | Server error | Unhandled exception on the server |
| 503 Service Unavailable | Server temporarily down | Maintenance, overload, or dependency failure |
Status codes allow clients to handle different outcomes programmatically. A client that receives a 401 knows to re-authenticate. A client that receives a 429 knows to back off and retry after a delay.
A client that receives a 503 knows the server is temporarily unavailable and can retry with exponential backoff. This machine-readable communication layer is what makes API integrations robust.
Authentication in REST APIs
Because REST is stateless, authentication credentials must accompany every request. The three dominant patterns each serve different use cases.
API Keys
The simplest approach: a secret string sent in a request header or query parameter. Used for server-to-server communication and developer tool access where the client is a trusted application.
Authorization: ApiKey sk_live_abc123def456API keys are simple to implement but limited: they identify the application, not the user, and they cannot express fine-grained permissions or expiration. They are appropriate for server-side integrations and development environments; they are not appropriate for user-facing authentication.
Bearer Tokens (JWT)
JSON Web Tokens (JWT) are signed tokens that encode claims about the user - their identity, their permissions, and when the token expires. The server validates the signature mathematically without consulting a database, making JWT authentication fast and scalable.
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...A JWT consists of three parts: a header (algorithm and token type), a payload (claims about the user), and a signature (cryptographic verification).
The server signs the token with a secret key; any subsequent request bearing that token can be validated by checking the signature, without a database lookup.This makes JWTs particularly well-suited for microservice architectures where multiple services need to validate authentication independently.OAuth 2.0
The industry standard for delegated authorization - allowing a third-party application to access resources on a user's behalf without receiving their password. OAuth 2.0 issues access tokens with defined scopes (what the token allows) and expiration times.
It is the mechanism behind "Sign in with Google," "Connect with GitHub," and virtually every third-party integration on the modern web.
OAuth 2.0 is a framework, not a single protocol. Its four grant types (authorization code, implicit, client credentials, and resource owner password) serve different security contexts.
The authorization code flow with PKCE (Proof Key for Code Exchange) is now recommended for virtually all client-facing applications, including single-page applications and mobile apps.
JSON: The Default Language of REST
While REST does not mandate any particular data format, JSON (JavaScript Object Notation) has become the overwhelming standard. It is lightweight, human-readable, and natively supported in virtually every programming language.
A typical REST response for a single resource:
{ "id": 42, "title": "What Is REST API", "author": { "id": 7, "name": "Jane Smith" }, "published_at": "2024-03-15T10:30:00Z", "tags": ["api", "web development", "programming"], "_links": { "self": "/articles/42", "author": "/users/7", "comments": "/articles/42/comments" } }The
_linksfield in this example represents HATEOAS - providing navigation links that allow the client to discover related resources from the response itself.While few APIs implement this fully, the pattern illustrates what Fielding's vision of a truly RESTful API looks like.JSON replaced XML as the preferred format for web APIs around 2012-2015 because it is more compact, less verbose, requires no schema definition, and maps naturally to data structures in JavaScript, Python, Ruby, Go, and most other languages.
XML remains in use in some enterprise, financial services, and legacy SOAP-based contexts, but JSON represents approximately 95 percent of new API implementations according to ProgrammableWeb (2023).
REST vs. GraphQL vs. gRPC
REST is dominant but not universal. Two alternative architectures have gained significant adoption for specific use cases.
GraphQL
Developed internally at Facebook in 2012 and released publicly in 2015, GraphQL is a query language for APIs where clients specify exactly what data they need in a single request.
Where REST requires consuming whatever data structure the server defines for each endpoint, GraphQL lets the client say: "Give me the user's name and their last five orders, including each order's total and status, but not the full order details." This addresses two specific problems with REST:
- Over-fetching: Getting more data than needed (downloading a full user object with 30 fields when you only need the name)
- Under-fetching: Needing multiple sequential requests to get related data (fetching a user, then fetching their orders, then fetching each order's items)
The trade-offs are real. GraphQL has a steeper learning curve, more complex server implementation, less straightforward caching (because queries are POST requests with variable bodies, not cacheable GETs), and can create performance problems if clients construct deeply nested queries that cause expensive database operations.
For simple, stable data structures, REST is typically simpler. For complex, interconnected data with highly variable client needs, GraphQL can be significantly more efficient.
gRPC
gRPC (Google Remote Procedure Call) uses Protocol Buffers - a binary serialization format - rather than JSON, and HTTP/2 rather than HTTP/1.1. It is significantly faster and more efficient than REST for high-volume, low-latency communication, particularly between internal microservices.
gRPC supports bidirectional streaming (both client and server can send messages simultaneously), strongly typed contracts defined in .proto files, and automatic code generation for client and server stubs in multiple languages. Google uses gRPC internally for communication between microservices handling billions of requests per day.
The trade-off: gRPC is not human-readable (binary format requires tooling to inspect), does not work natively in browsers (requiring a proxy like gRPC-Web), and requires both client and server to share the Protocol Buffer schema definition.
It is the right choice for internal service-to-service communication where performance is critical; REST remains the standard for public-facing APIs where developer experience and accessibility matter.
| Feature | REST | GraphQL | gRPC |
|---|---|---|---|
| Protocol | HTTP/1.1 or HTTP/2 | HTTP/1.1 or HTTP/2 | HTTP/2 |
| Data format | JSON (typical) | JSON | Protocol Buffers (binary) |
| Client flexibility | Low (server defines responses) | High (client defines queries) | Low (schema-defined) |
| Caching | Easy (HTTP caching) | Complex (POST-based) | Custom implementation |
| Browser support | Native | Native | Requires proxy |
| Learning curve | Low | Medium | High |
| Best for | Public APIs, simple CRUD | Complex data, mobile clients | Internal services, streaming |
| Adoption | ~89% of developers | ~35% of developers | ~11% of developers |
Adoption figures from Postman's 2023 State of the API Report.
What Makes a REST API "Good"
A technically RESTful API can still be frustrating to use if it violates common conventions or neglects developer experience. The best APIs in production - Stripe, Twilio, GitHub - share characteristics that go beyond the six REST constraints.
Consistent and Predictable Naming
Plural nouns for collections (/articles, not /article or /getArticles). Consistent casing. Predictable patterns that let a developer guess an endpoint's URL correctly before reading the documentation.
Meaningful Error Messages
Errors should return appropriate 4xx/5xx status codes with structured error bodies that explain what went wrong and, ideally, how to fix it. Stripe's API is widely regarded as the gold standard here: every error includes a type, a code, a human-readable message, and a documentation URL.
Versioning
Major breaking changes should be introduced through versioned URLs (/v1/articles, /v2/articles) or header-based versioning, to avoid breaking existing clients. The industry has not converged on a single versioning strategy, but URL-based versioning is the most common and the most visible.
Pagination, Filtering, and Sorting
List endpoints should return paginated results with metadata about total count and navigation links. They should support query parameters for filtering (?status=published&author_id=7) and sorting (?sort=created_at&order=desc).
Returning unbounded result sets is a reliability hazard - a collection with 10 million records should never be returned in a single response.
Rate Limiting
APIs should enforce and communicate rate limits using standard headers (X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset) and return 429 Too Many Requests when limits are exceeded. Rate limiting protects both the API provider and well-behaved clients from the effects of misbehaving ones.
Documentation
OpenAPI Specification (formerly Swagger) documents endpoints, parameters, request bodies, and response schemas in a machine-readable format that can generate interactive documentation, client SDKs, and test suites.
A 2023 survey by SmartBear found that 65 percent of developers rated documentation quality as the most important factor when evaluating a new API - above performance, pricing, and even functionality.
"A REST API is a product. Its users are developers. Good API design means those developers can figure out how to use it without reading the source code." - widely attributed, API design community
Building Your First REST API: A Practical Orientation
For developers new to API development, the practical landscape of REST frameworks is broad but well-mapped.
| Language | Popular REST Frameworks | Notable Example |
|---|---|---|
| JavaScript/Node.js | Express.js, Fastify, Nest.js | Express powers millions of APIs globally |
| Python | FastAPI, Django REST Framework, Flask | FastAPI combines performance with automatic docs |
| Go | Gin, Echo, Chi | Gin is used at scale by companies like Stripe |
| Java | Spring Boot, Quarkus | Spring Boot dominates enterprise Java |
| Ruby | Rails (API mode), Sinatra | Rails API mode strips frontend concerns |
| Rust | Actix Web, Axum | Emerging for performance-critical APIs |
The choice of framework matters less than the design principles applied. A well-designed REST API in any of these frameworks will follow the same conventions for URL structure, HTTP methods, status codes, and error handling. The constraints are language-agnostic - which is, after all, the point.
Key Takeaways
- REST is an architectural style - a set of constraints originally defined by Roy Fielding in his 2000 doctoral dissertation - not a protocol or specification
- The six constraints are client-server separation, statelessness, cacheability, uniform interface, layered system, and optional code on demand
- Statelessness is the most operationally important constraint: every request is self-contained, enabling horizontal scaling to billions of requests per day
- HTTP methods map to operations on resources: GET retrieves, POST creates, PUT replaces, PATCH partially updates, DELETE removes
- HTTP status codes communicate outcomes precisely and should be used correctly rather than returning 200 for everything
- Authentication is handled via API keys, JWT bearer tokens, or OAuth 2.0, with each approach suited to different trust levels and use cases
- GraphQL solves over-fetching and under-fetching for complex data needs; gRPC is faster for internal service communication - but REST remains the default for public-facing APIs
- The best REST APIs treat developer experience as a first-class concern: consistent naming, meaningful errors, comprehensive documentation, and predictable behavior
Sources & Further Reading
- Fielding, R. T. Architectural Styles and the Design of Network-based Software Architectures. Doctoral dissertation, University of California, Irvine, 2000. Available at: View source
- Fielding, R. T., & Taylor, R. N. "Principled Design of the Modern Web Architecture." ACM Transactions on Internet Technology, vol. 2, no. 2, 2002.
- Richardson, L., Amundsen, M., & Ruby, S. RESTful Web APIs. O'Reilly Media, 2013.
- Masse, M. REST API Design Rulebook. O'Reilly Media, 2011.
- Postman. "2023 State of the API Report." postman.com, 2023.
- RapidAPI. "2023 State of APIs Report." rapidapi.com, 2023.
- SmartBear. "State of API 2023." smartbear.com, 2023.
- Fielding, R. T. "REST APIs Must Be Hypertext-Driven." roy.gbiv.com/untangled, 2008.
- Google. "API Design Guide." cloud.google.com/apis/design, 2023.
- Microsoft. "RESTful Web API Design." docs.microsoft.com, 2023.
- Stripe. "API Reference." stripe.com/docs/api, 2024.
- Mozilla Developer Network. "HTTP Status Codes." developer.mozilla.org, 2024.
- IETF. "RFC 7231: Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content." tools.ietf.org, 2014.
- Facebook Engineering. "GraphQL: A Data Query Language." engineering.fb.com, 2015.
- Google. "Introduction to gRPC." grpc.io/docs, 2024.
Frequently Asked Questions
What is a REST API?
A REST API (Representational State Transfer Application Programming Interface) is a way for software systems to communicate with each other over HTTP using a set of architectural constraints defined by Roy Fielding in his 2000 doctoral dissertation. It uses standard HTTP methods (GET, POST, PUT, DELETE) to perform operations on resources identified by URLs, and returns data, typically in JSON format, that represents the current state of those resources.
What are the six REST constraints?
Roy Fielding defined six architectural constraints that make a system RESTful: client-server architecture (separating UI concerns from data storage), statelessness (each request must contain all information needed to process it), cacheability (responses should indicate whether they can be cached), uniform interface (standardized resource identification and manipulation), layered system (clients cannot tell whether they are connected directly or through intermediaries), and optional code on demand (servers can extend client functionality by sending executable code).
What is the difference between GET, POST, PUT, and DELETE in REST?
These HTTP methods correspond to the four basic data operations. GET retrieves a resource without modifying it, it is safe and idempotent. POST creates a new resource; calling it multiple times creates multiple resources. PUT updates an existing resource by replacing it entirely; it is idempotent (calling it multiple times has the same effect as calling it once). DELETE removes a resource. PATCH, a related method, partially updates a resource rather than replacing it entirely.
What is statelessness in a REST API?
Statelessness means that each HTTP request must contain all the information the server needs to process it, the server does not store any session state between requests. Authentication credentials, context, and any other required information must be sent with every request. This makes REST APIs highly scalable because any server instance can handle any request without needing shared session storage.
What is the difference between REST and GraphQL?
REST uses multiple endpoints (one per resource type) where the server defines what data is returned. GraphQL uses a single endpoint where clients specify exactly what data they need using a query language. GraphQL eliminates over-fetching (getting more data than needed) and under-fetching (needing multiple requests to get related data). REST has simpler caching, broader tooling support, and lower learning curve. GraphQL is often preferred for complex, interconnected data or when clients have highly variable data needs.