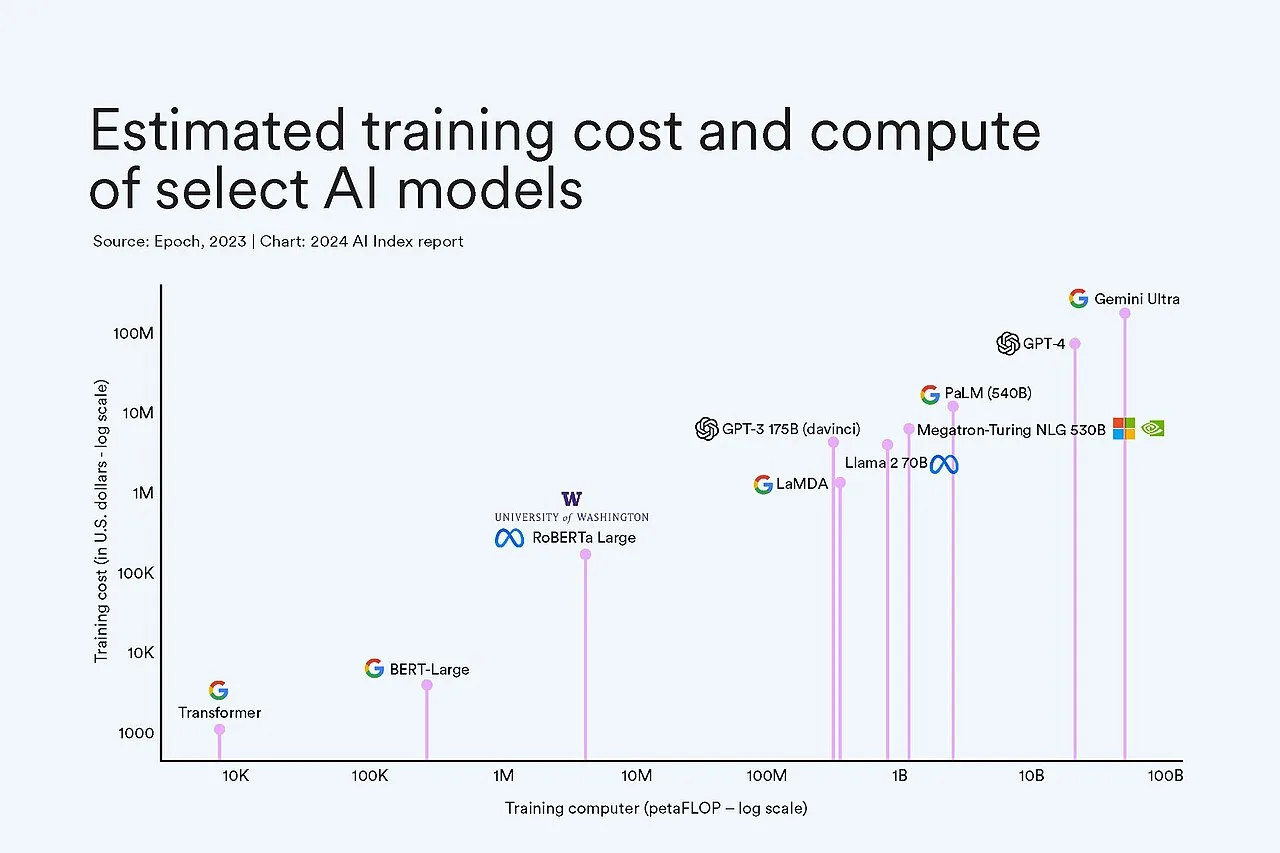
In 2020, OpenAI revealed that training GPT-3 consumed approximately 3.14 million compute hours on specialized GPU clusters, at an estimated cost of several million dollars. The model never saw the real world, never had a conversation, never experienced anything.
It simply processed 570 gigabytes of text - roughly 400 billion tokens - adjusting billions of numerical parameters until the patterns it learned could predict the next word in a sequence with remarkable accuracy.
That process - turning raw data into a system that can generate coherent text, identify images, or recommend products - is what we mean by "training" an AI model. Understanding how it works demystifies much of what AI can and cannot do.
Training is not programming in the traditional sense. A traditionally programmed system follows explicit rules: if condition A is true, do action B. A trained AI model has no explicit rules.
Instead, it has billions of numerical parameters - called weights - that were adjusted iteratively to minimize the error between the model's outputs and the correct outputs on a massive training dataset.
The weights encode, in a distributed and opaque way, whatever statistical regularities exist in the training data that are useful for the task.
This distinction between rule-based programming and learned parameters is what gives AI models their distinctive character: they can perform tasks that are too complex or contextual to specify as explicit rules (like recognizing faces or translating languages), but they also fail in ways that explicitly programmed systems would not (like confidently asserting false facts or failing on slightly modified inputs).
"Training a machine learning model is the process of finding a set of parameters that minimizes prediction error on a dataset. Everything else - architecture choices, regularization, optimization algorithms - exists in service of that single goal." - Andrej Karpathy, 2022
The Core Training Loop
| Training Paradigm | Description | Data Requirement | Typical Use Case |
|---|---|---|---|
| Supervised learning | Model trains on labeled input-output pairs; minimizes prediction error | Large labeled dataset; labeling is often expensive | Image classification, spam detection, sentiment analysis |
| Unsupervised learning | Model finds structure in unlabeled data; no explicit labels needed | Large unlabeled dataset | Clustering, dimensionality reduction, anomaly detection |
| Self-supervised learning | Model generates its own labels from structure in the data | Large unlabeled dataset (labels implicit in structure) | Language model pre-training (predict next word); masked image modeling |
| Reinforcement learning | Agent learns by receiving rewards for actions in an environment | Reward function and simulated or real environment | Game-playing AI, robotics control, recommendation optimization |
| Reinforcement learning from human feedback (RLHF) | Human preferences used to train reward model that guides policy optimization | Human preference ratings on model outputs | Fine-tuning large language models for helpful, harmless behavior |
| Transfer learning | Model pre-trained on large dataset is fine-tuned on smaller domain-specific dataset | Small labeled domain dataset plus large pre-training dataset | Adapting general LLMs to medical, legal, or domain-specific tasks |
AI model training follows a consistent logical structure regardless of the specific type of model or task. Understanding this loop clarifies why training works and what its limitations are.
The Four-Step Training Loop
Step 1: Forward pass - The model receives an input (a piece of text, an image, a sequence of data) and produces an output based on its current parameter values. For a language model, the input might be the beginning of a sentence and the output is the model's prediction of what comes next.
For an image classifier, the input is an image and the output is a probability distribution over possible categories.
Step 2: Loss calculation - The model's output is compared to the correct answer (the "label" in supervised learning, or the next token in self-supervised language model training).
The difference between prediction and correct answer is quantified as a "loss" - a single number that measures how wrong the model was. Common loss functions include cross-entropy loss (for classification) and mean squared error (for regression).
Step 3: Backward pass (backpropagation) - The loss is used to calculate gradients: numerical values for each model parameter indicating how much the loss would change if that parameter were increased or decreased slightly.
Backpropagation, first introduced as a practical training algorithm in the 1980s by Rumelhart, Hinton, and Williams, efficiently computes these gradients by propagating error signals backward through the neural network from output to input.
Step 4: Parameter update - Each parameter is adjusted slightly in the direction that would reduce the loss. The size of each adjustment is controlled by the learning rate - a hyperparameter that determines how aggressively the model updates in response to each training example.
This adjustment is done by an optimizer; the most commonly used are variants of Stochastic Gradient Descent (SGD), particularly Adam, which adapts the learning rate for each parameter based on the history of gradients.
This four-step loop repeats millions or billions of times, with each iteration exposing the model to a batch of training examples and adjusting parameters accordingly.
Over time, the model's parameters converge toward values that produce low loss on the training data - meaning the model has "learned" the patterns present in that data.
What the Model Actually Learns
What emerges from this process is not a set of explicit rules but a distributed representation - a pattern of weights across the network that collectively encode statistical regularities in the training data.
For a language model trained on text: the weights encode the statistical structure of language, including grammar, factual associations, common reasoning patterns, and the characteristic style of different types of writing.
The model does not have a rule that says "don't put an adjective after a period and before a noun" - it has weights that make grammatically incorrect sequences statistically unlikely in its outputs.
For an image classifier: the weights encode visual features that distinguish one category from another. Early layers of the network learn low-level features like edges and colors; later layers combine these into more abstract features like textures and shapes; the final layers combine these into category-specific representations.
This distributed, statistical nature of what models learn explains both their power and their limitations. They can recognize patterns too complex and context-dependent to specify as explicit rules. But they also cannot reliably distinguish between true statistical regularities and spurious correlations in the training data.
Types of Learning
The training paradigm varies significantly depending on the availability of labeled data and the nature of the learning task.
Supervised Learning
In supervised learning, the model is trained on a dataset where each input has a corresponding correct output (label). The model learns to map inputs to outputs by minimizing the loss between its predictions and the labels.
Supervised learning requires labeled data - human-annotated examples of the correct output for each input. Creating this labeled data is often expensive and time-consuming.
Image classification datasets like ImageNet (1.4 million images labeled with one of 1,000 categories) required massive crowd-sourced annotation efforts. Medical AI datasets require expert physicians to label thousands of images.
Applications: Image classification, object detection, named entity recognition, sentiment analysis, spam detection, fraud detection. Essentially any task where you can define correct outputs and collect enough labeled examples.
Example: Google's development of its spam filter for Gmail used supervised learning on millions of labeled emails (spam vs.
not spam) provided by Gmail users who clicked "Report spam." The model learned to identify patterns in email content, sender information, and metadata that predicted whether users would classify an email as spam - effectively crowdsourcing the labeling and continuously updating the training data with new examples.
Unsupervised Learning
In unsupervised learning, the model is trained on unlabeled data to discover structure or patterns without being given correct answers. The model must find regularities in the data on its own.
Clustering algorithms (K-means, DBSCAN) group similar data points together without predefined categories. Dimensionality reduction methods (PCA, t-SNE, UMAP) find low-dimensional representations of high-dimensional data that preserve important structure.
Generative models (autoencoders, variational autoencoders) learn to compress and reconstruct data, capturing the essential structure of the data distribution.
Unsupervised learning is valuable when labeled data is unavailable or expensive, but it is harder to evaluate: without a clear correct answer, assessing whether the model has learned something meaningful requires domain expertise and careful analysis.
Self-Supervised Learning
Self-supervised learning occupies a middle ground between supervised and unsupervised learning. The model is trained to predict some part of the input from other parts, creating a supervised learning signal from unlabeled data by using the data itself as labels.
For language models: the model is trained to predict the next word given all preceding words (as in GPT-style models) or to predict masked words given surrounding context (as in BERT-style models).
The training signal comes from the text itself - the actual next word is the label - so no human annotation is needed. This allows training on internet-scale text corpora.
For vision: models can be trained to predict the color of an image from its grayscale version, to predict the relative positions of image patches, or to predict one view of a scene from another. These pretext tasks require no labels while forcing the model to learn useful visual representations.
Self-supervised learning is the paradigm that enabled the scale of current large language models. Training on hundreds of billions of tokens of unlabeled text from the internet would be impossible if each token required human annotation.
Example: The development of BERT (Bidirectional Encoder Representations from Transformers) by Google in 2018 demonstrated the power of self-supervised pre-training for language understanding. BERT was pre-trained on 3.3 billion words of text using masked language modeling (predicting randomly masked words) and next sentence prediction.
After pre-training, the model could be fine-tuned on small labeled datasets for specific tasks - question answering, sentiment analysis, natural language inference - dramatically outperforming models trained from scratch on those small datasets.
BERT's success established self-supervised pre-training followed by supervised fine-tuning as the dominant paradigm for language AI.
Reinforcement Learning
In reinforcement learning (RL), an agent learns to take actions in an environment to maximize cumulative reward. Unlike supervised learning (where correct outputs are provided) or unsupervised learning (where structure is discovered), RL learns from the consequences of actions.
The agent takes actions, receives reward signals (positive for good outcomes, negative for bad ones), and updates its policy (the function mapping states to actions) to maximize future expected reward.
The challenge is that feedback is often delayed and sparse - a chess-playing agent doesn't know which moves were good until the game ends.
Reinforcement learning applications: Game playing (AlphaGo, AlphaStar), robotics control, recommendation systems optimization, and, critically, the alignment training of large language models through Reinforcement Learning from Human Feedback (RLHF).
Example: DeepMind's AlphaGo Zero (2017) was trained exclusively through self-play reinforcement learning, starting from random play and developing superhuman Go playing ability in 40 days without any human game data. The training loop involved games against previous versions of itself, with win/loss as the reward signal.
The result was a player that developed strategies that human Go players had never discovered in thousands of years of playing the game.
The Architecture of Modern Language Models
Understanding what is being trained requires understanding the Transformer architecture, which underlies virtually all state-of-the-art language models since its introduction in 2017.
The Transformer Architecture
The Transformer, introduced by Vaswani et al. at Google in the paper "Attention Is All You Need," replaced the recurrent neural networks that had previously dominated language AI. The key innovation was the attention mechanism: a way for the model to dynamically focus on different parts of the input when processing each token.
Attention mechanism: For each token being processed, the model computes "attention scores" with every other token in the context, determining how much each other token should influence the current token's representation.
Tokens that are semantically related or syntactically connected receive higher attention scores. This allows the model to capture long-range dependencies that recurrent networks struggled with.
Multi-head attention: The Transformer uses multiple parallel attention computations (multiple "heads"), each learning to attend to different types of relationships - one head might learn syntactic dependencies, another semantic similarity, another coreference.
Scale: The key characteristic of current large language models is scale: they have hundreds of billions (GPT-4, Gemini Ultra, Claude) of parameters. This scale comes from stacking many Transformer layers and widening the attention and feed-forward components within each layer.
Empirically, performance on language tasks has been found to improve smoothly and predictably with scale in compute, data, and parameter count - the "scaling laws" documented by Kaplan et al. at OpenAI in 2020.
Pre-Training and Fine-Tuning
The dominant training paradigm for large language models has two stages:
Pre-training: The model is trained on a massive corpus of text using self-supervised learning (next-token prediction). This stage is computationally expensive - training frontier models requires thousands of specialized chips running for weeks or months - but produces a model with broad language capabilities and extensive world knowledge.
Fine-tuning: The pre-trained model is further trained on a smaller, more targeted dataset to adapt it for specific purposes. Instruction fine-tuning trains the model to follow natural language instructions.
RLHF fine-tunes the model to be helpful, harmless, and honest based on human preference ratings. Domain fine-tuning adapts a general model for a specific domain like medicine or law.
This two-stage paradigm allows the computationally expensive pre-training to be shared across many applications, with cheaper fine-tuning customizing the model for each.
Training Challenges and Solutions
The Vanishing/Exploding Gradient Problem
Early deep neural networks suffered from gradients that either became vanishingly small (preventing effective learning in early layers) or explosively large (causing training instability) as they were backpropagated through many layers.
Modern solutions include:
- Residual connections (skip connections that add the layer's input to its output), pioneered in ResNet, which allow gradients to bypass layers directly
- Layer normalization, which normalizes activations at each layer to prevent scale problems
- Careful weight initialization schemes that ensure initial gradients are in a useful range
- Gradient clipping, which caps gradient values at a maximum magnitude
Overfitting
A model that memorizes its training data rather than learning general patterns will perform well on training data but poorly on new data - a failure mode called overfitting.
Solutions:
- Regularization techniques (dropout, weight decay) that penalize complexity and discourage memorization
- Data augmentation that artificially increases the diversity of training examples
- Early stopping that halts training when validation set performance stops improving
- Increasing data size - overfitting becomes less problematic as dataset size increases relative to model size
Computational Cost
Training modern large language models requires compute resources that are only available to major technology companies and well-funded research institutions. This concentration of training capability raises significant questions about who can develop frontier AI models and how the benefits and risks are distributed.
Research directions that aim to improve compute efficiency include:
- Mixture of Experts (MoE) architectures that activate only a fraction of model parameters for each input
- Improved data curation that extracts more learning signal from less data
- Distillation methods that train smaller models to replicate the behavior of larger ones
- Quantization and pruning that reduce model size after training without proportional quality loss
Example: Mistral AI, founded in 2023 by former DeepMind and Meta researchers, released the Mistral 7B model that outperformed Meta's much larger LLaMA 2 13B model on many benchmarks through architectural innovations and careful data curation.
The achievement demonstrated that smaller models with better training can compete with much larger models with standard training - a commercially significant finding that has shaped subsequent model development.
After Training: Evaluation and Deployment
Evaluation
Model evaluation is a field in itself. Training a model well and evaluating it well are distinct challenges.
Benchmark evaluation: Standard academic benchmarks (MMLU for multi-task knowledge, HumanEval for coding, BIG-Bench for diverse reasoning) provide standardized comparisons across models. However, benchmark performance can be gamed (models trained or evaluated on test data) and may not reflect real-world performance.
Human evaluation: For qualitative tasks, human evaluators compare outputs across models or rate outputs on specific criteria. Human evaluation is more reliable than benchmarks for capturing real-world quality but is expensive and hard to scale.
Red teaming: Adversarial testing designed to find failure modes - responses the model should not produce, behaviors that violate safety guidelines, capability limitations in high-stakes domains.
Deployment metrics: Ultimately, the most meaningful evaluation is how the model performs in deployment, measured by user engagement, task completion rates, and - for high-stakes applications - outcome metrics like diagnostic accuracy or customer satisfaction.
Deployment Considerations
A trained model that performs well in evaluation may still fail in deployment if:
- Distribution shift: The deployment distribution differs from the training and evaluation distribution
- Adversarial users: Users actively try to elicit outputs that the model was not trained to produce
- Integration failures: The model interacts with other systems in unexpected ways
- Scale: Performance that is acceptable at low volume may degrade at scale due to tail failures that rare inputs expose
Modern AI deployment includes monitoring, filtering, and feedback systems that detect and respond to these problems. The trained model weights are the beginning of a deployed AI system, not the end.
Training AI models is both more mechanical than most people imagine (an optimization process iterating over data to reduce a loss function) and more remarkable (the emergence of sophisticated capabilities from simple objectives applied at scale).
The gap between these two descriptions - between the mechanical process and its emergent results - is what makes AI development both exciting and, in important ways, unpredictable.
See also: AI Safety and Alignment Challenges, AI vs. Human Intelligence Compared, and Prompt Engineering Best Practices.
What Research Shows About AI Training Methods and Scaling
The empirical study of what happens when neural networks are trained at increasing scale has produced some of the most consequential findings in modern AI research, with direct implications for understanding why current large language models behave as they do.
Jared Kaplan, Sam McCandlish, and colleagues at OpenAI published "Scaling Laws for Neural Language Models" in January 2020, documenting that language model performance (measured as cross-entropy loss on test data) improves as a smooth power law with increases in model size, dataset size, and compute budget - across many orders of magnitude.
The paper found that model size and training compute are more important than architectural details for determining language model performance, and established quantitative formulas for predicting how much performance improvement a given increase in compute would produce.
The scaling law finding had an immediate effect on research strategy: if performance scales predictably with compute, the path to improvement is to scale up, which explains the trajectory from GPT-2 (1.5 billion parameters, 2019) to GPT-3 (175 billion parameters, 2020) to GPT-4 (estimated 1+ trillion parameters, 2023) in rapid succession.
Kaplan's research also found that for a fixed compute budget, it is more efficient to train a larger model on less data than a smaller model on more data - a finding later revised by Hoffmann et al.
in DeepMind's 2022 "Chinchilla" paper, which demonstrated that Kaplan's original models were undertrained relative to their size, and that optimal compute allocation trains a model with roughly 20 tokens per parameter.
Paul Christiano at OpenAI (now at the Alignment Research Center) developed Reinforcement Learning from Human Feedback (RLHF) as a practical technique for aligning language model behavior with human preferences.
The foundational paper, "Learning to Summarize from Human Feedback" (Stiennon et al., NeurIPS 2020), trained a reward model on human preferences between pairs of model outputs and used it to fine-tune GPT-3 for summarization.
The RLHF-trained model was preferred by human evaluators 70 percent of the time over a model trained purely on supervised learning with 10 times more data - demonstrating that human feedback is a dramatically more data-efficient signal than labeled examples for tasks where quality is difficult to specify algorithmically.
This result established RLHF as the practical alignment technique subsequently used to train InstructGPT, ChatGPT, and similar conversational AI systems.
Long Ouyang at OpenAI led the InstructGPT paper (2022), which showed that a 1.3 billion parameter RLHF-trained model was preferred by human evaluators over a 175 billion parameter base GPT-3 model on instruction-following tasks 85 percent of the time - a stark demonstration that alignment training can overcome a 100-fold difference in model size.
Jordan Hoffmann and colleagues at DeepMind published "Training Compute-Optimal Large Language Models" (2022, informally called the Chinchilla paper), demonstrating through systematic experiments that the compute-optimal training strategy involves training a model for substantially more tokens than previously assumed.
The paper trained 400 language models ranging from 70 million to 16 billion parameters on datasets ranging from 5 billion to 400 billion tokens, finding that for a given compute budget, the optimal ratio is approximately equal numbers of parameters and training tokens (roughly 20 tokens per parameter).
Applying this finding, DeepMind trained Chinchilla (70 billion parameters, 1.4 trillion tokens) with the same compute budget that Gopher (280 billion parameters, 300 billion tokens) used, and Chinchilla substantially outperformed Gopher despite having four times fewer parameters.
The Chinchilla finding redirected AI research away from simply maximizing model size and toward improving data quality and training duration, influencing the design of Meta's LLaMA models, Google's Gemini, and Anthropic's Claude series.
Geoffrey Hinton, Yann LeCun, and Yoshua Bengio - jointly awarded the 2018 Turing Award for their foundational contributions to deep learning - have each commented on the emergence of capabilities that appear during training as models scale past certain size thresholds.
Jason Wei at Google Brain formalized this observation in "Emergent Abilities of Large Language Models" (2022), documenting over 100 capabilities that appear to emerge discontinuously as models scale: abilities including multi-step arithmetic, analogical reasoning, chain-of-thought reasoning, and certain language translation tasks showed near-zero performance at smaller scales and then sharp capability gains past a threshold model size.
The emergence finding - if it holds at continued scales rather than being a measurement artifact - has significant implications for AI development planning: it suggests that future training runs may produce qualitatively new capabilities that are difficult to predict in advance.
Real-World Case Studies in AI Training and Deployment
GPT-3 and the Economics of Large-Scale Pre-Training. OpenAI's GPT-3, trained in 2020, provided the first public demonstration that a single pre-trained model could perform competently on a wide variety of tasks through in-context learning, without any task-specific fine-tuning.
The training consumed approximately 3.14 million GPU hours on NVIDIA V100 GPUs at an estimated cost of $4.6 million in cloud compute (based on 2020 spot pricing).
The model's ability to perform tasks ranging from translation to code generation to arithmetic via prompting alone - without the task-specific training that prior AI systems required - established the commercial viability of the foundation model paradigm: train once at large scale, deploy many times.
OpenAI's subsequent API, which served GPT-3 to developers, generated revenue that enabled continued model development.
The GPT-3 case demonstrated that the economics of large-scale pre-training are favorable when the cost is amortized across many downstream applications and users, each of whom requires only the cheaper inference cost rather than the full training cost.
DeepMind's AlphaFold 2: Scientific Training Data and Validated Outcomes. AlphaFold 2, described by John Jumper and colleagues at DeepMind in a 2021 Nature paper, was trained on the Protein Data Bank (PDB) - a curated dataset of approximately 170,000 experimentally determined protein structures accumulated over 50 years of structural biology research.
The training methodology combined multiple sequence alignments (showing how related proteins vary across species) with self-supervised learning on structure prediction, using both experimental structures and high-confidence predicted structures generated by earlier model iterations to expand the training set.
AlphaFold 2 achieved a median RMSD (root mean square deviation from experimental structures) of 0.96 angstroms on the CASP14 benchmark, within the margin of experimental error - effectively solving the protein structure prediction problem.
By 2022, DeepMind had released a database of predicted structures for over 200 million proteins, covering essentially every known protein.
The scientific community has since used AlphaFold predictions in over 1 million research projects, according to DeepMind's 2024 impact report, accelerating drug discovery timelines across malaria, antibiotic resistance, and cancer research.
Meta's LLaMA: Open Training and the Democratization of Foundation Models. Meta AI's LLaMA models (released in 2023 and 2024) were trained with a specific design philosophy: use more training tokens than the Chinchilla-optimal amount to produce smaller models that perform better at inference time, rather than larger models that perform better per training token but are more expensive to deploy.
LLaMA 1 (released February 2023) trained a 7 billion parameter model on 1 trillion tokens - roughly 10 times more than Chinchilla would suggest for that model size - and achieved performance comparable to GPT-3 (175 billion parameters) on many benchmarks.
LLaMA 2 (July 2023) extended this to 70 billion parameters trained on 2 trillion tokens and incorporated RLHF alignment training using approximately 1 million human preference labels collected through Meta's own annotation program.
The open release of LLaMA model weights (available for research and commercial use) enabled over 30,000 derivative models to be created within a year, according to Hugging Face's tracking data, dramatically lowering the barrier to deploying capable language models and enabling academic researchers without access to large compute budgets to conduct research on frontier-class models.
Google's BERT in Search: Training for Real-World Impact. Google's BERT (Bidirectional Encoder Representations from Transformers), developed by Jacob Devlin and colleagues at Google AI Language and described in a 2018 paper, was the first large-scale demonstration of the self-supervised pre-training paradigm for natural language understanding tasks.
Google subsequently deployed BERT in Google Search in late 2019, describing it at the time as "the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search." In a Google Webmaster Conference presentation, Search Liaison Danny Sullivan described BERT as helping Google better understand the intent behind queries - particularly long, conversational queries and queries where prepositions (like "to" and "for") change meaning substantially.
Google estimated that BERT affected approximately 10 percent of all English-language searches at launch.
The production deployment provided validation at unprecedented scale that self-supervised language model pre-training captures semantic understanding useful for real-world information retrieval - the first deployment of a large pre-trained transformer in a system handling billions of daily queries.
Sources & Further Reading
- Vaswani, Ashish et al. "Attention Is All You Need." NeurIPS, 2017. View source
- Kaplan, Jared et al. "Scaling Laws for Neural Language Models." OpenAI, 2020. View source
- Brown, Tom et al. "Language Models are Few-Shot Learners (GPT-3)." NeurIPS, 2020. View source
- Devlin, Jacob et al. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." NAACL, 2019. View source
- Silver, David et al. "Mastering the game of Go without human knowledge." Nature, 2017. View source
- Goodfellow, Ian, Bengio, Yoshua, and Courville, Aaron. Deep Learning. MIT Press, 2016. View source
- Rumelhart, David, Hinton, Geoffrey, and Williams, Ronald. "Learning representations by back-propagating errors." Nature, 1986. View source
- He, Kaiming et al. "Deep Residual Learning for Image Recognition." CVPR, 2016. View source
- Anthropic. "Claude's Constitution." Anthropic. View source
- Jiang, Albert et al. "Mistral 7B." arXiv, 2023. View source
Frequently Asked Questions
What are the main stages of training an AI model?
Data collection and preparation, model architecture selection, training (optimize parameters to minimize error), validation (test on held-out data), evaluation (measure performance), fine-tuning, and deployment. Iterative process, rarely works first try. Most time: data preparation and evaluation.
Why is data quality more important than quantity?
Garbage in, garbage out: biased data creates biased models, mislabeled data teaches wrong patterns, unrepresentative data fails on real world. Quality matters: accuracy, diversity, relevance. More data helps but: 1000 good examples > 100K bad ones. Diminishing returns from quantity alone.
How much data and compute do you need to train AI?
Varies wildly: simple models (thousands of examples, laptop), large language models (billions of examples, supercomputer clusters, millions in compute). Trend: larger models need more of both. Transfer learning reduces requirements, start with pretrained model, fine-tune with less data/compute.
What is overfitting and how do you prevent it?
Model memorizes training data instead of learning generalizable patterns, performs great on training, poor on new data. Prevention: more diverse data, regularization techniques, early stopping, dropout, and validation monitoring. Balance: fit training data without losing generalization.
How do you know if a trained model is good?
Test on held-out data (never seen during training), measure relevant metrics (accuracy, precision, recall, F1), test edge cases, compare to baseline/alternatives, and validate on real-world distribution. Good training performance insufficient, deployment performance matters.
Why does training large models take so long and cost so much?
Billions of parameters to optimize, trained on massive datasets, millions of gradient updates, requires expensive GPUs/TPUs, and often multiple training runs. Example: GPT-4 training cost estimated at tens of millions. Democratization challenge, only well-funded orgs can train largest models.
Can you retrain or update AI models after deployment?
Yes but challenging: requires new data, retraining time/cost, validation (performance and safety), deployment overhead, and potential for catastrophic forgetting (losing old knowledge). Strategies: continuous learning, fine-tuning, or periodic retraining. Many deployed models become stale over time.