What Is the Turing Test?
The Turing Test is a criterion for machine intelligence proposed by mathematician Alan Turing in his 1950 paper "Computing Machinery and Intelligence," in which a human interrogator communicates via text with both a human and a machine and attempts to determine which is which.
If the machine cannot be reliably distinguished from the human, Turing argued it is pragmatically justified to attribute intelligence to it.
The test replaced the unanswerable philosophical question "Can machines think?" with an operational, behavioral criterion - one that has since been both widely adopted and extensively criticized as insufficient for measuring genuine understanding or consciousness.
In 1950, a British mathematician published a paper that would shape the course of artificial intelligence research for the next seven decades. Alan Turing asked a deceptively simple question: "Can machines think?" Rather than trying to answer it directly, he proposed a practical alternative, a test based on imitation.
That test, now universally known as the Turing Test, remains one of the most discussed, criticized, and misunderstood ideas in the history of computing.
Understanding the Turing Test today requires more than knowing its basic mechanics. It requires understanding why Turing proposed it, what it actually claims to measure, how modern AI has challenged its assumptions, and what better tests researchers are now developing.
The question of machine intelligence is no longer theoretical. With large language models holding convincing conversations and generating human-quality writing, the Turing Test has moved from thought experiment to something approaching a daily reality.
The Original Proposal: Turing's Imitation Game
Turing's 1950 paper, "Computing Machinery and Intelligence," published in the philosophy journal Mind, did not begin with the question "Can machines think?" It began by saying that the question itself was meaningless because the words "machine" and "think" are too vague to be useful.
Instead, Turing proposed replacing the question with a game.
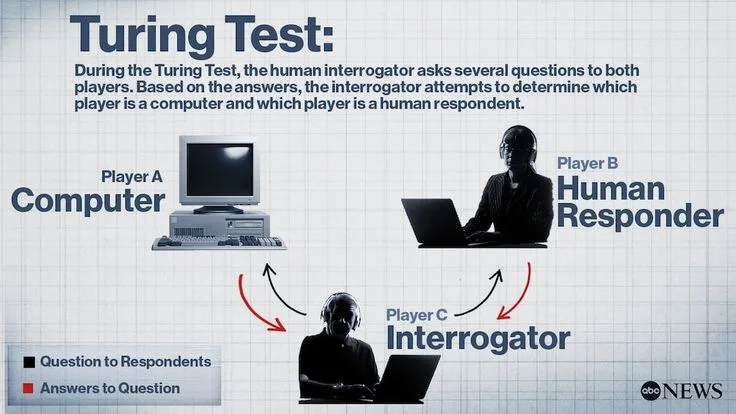
The original formulation, which Turing called the Imitation Game, involved three participants: a man (A), a woman (B), and a human interrogator (C). The interrogator, isolated in a separate room, communicates only through text and must determine which of the two respondents is the woman.
The man tries to deceive the interrogator; the woman tries to help the interrogator make the correct identification.
Turing then asked: what would happen if a machine took the man's role? If the machine could perform as well as a human in this deception, could we conclude it can think?
"I believe that in about fifty years' time it will be possible to programme computers, with a storage capacity of about 10^9, to make them play the imitation game so well that an average interrogator will not have more than 70 percent chance of making the right identification after five minutes of questioning.", Alan Turing, 1950
This was a probabilistic benchmark, not a binary pass/fail. Turing did not claim that passing the test would prove consciousness. He was proposing an operational definition: if a machine behaves indistinguishably from an intelligent entity, treating it as intelligent is pragmatically justified.
Turing's Nine Objections
A feature of the 1950 paper that is often overlooked is its systematic engagement with objections. Turing anticipated nine major objections to the idea of machine intelligence and addressed each in turn:
The Theological Objection: Thinking requires a soul, and machines cannot have souls. Turing dismissed this as placing unwarranted limits on God's power to grant souls to machines if he chose.
The "Heads in the Sand" Objection: The consequences of thinking machines would be too dreadful, so we hope they cannot. Turing acknowledged this as psychologically understandable but not an argument.
The Mathematical Objection: Godel's incompleteness theorems show that certain mathematical questions cannot be answered by any formal system. Turing acknowledged this but questioned whether humans are free of equivalent limitations.
The Consciousness Objection: A machine cannot be conscious and therefore cannot truly think. This is the objection that has proved most durable.
The Originality Objection: Machines can only do what they are programmed to do; they cannot originate anything. Turing argued this was empirically false, he anticipated that machines could surprise their creators.
The Lady Lovelace Objection: Ada Lovelace had written that the Analytical Engine could only do what we know how to order it to perform. Turing contested this.
Arguments from Continuity in the Nervous System: The nervous system is not a discrete-state machine. Turing acknowledged the difference but argued it would not matter for the imitation game.
The Informality of Behavior Objection: Human behavior is too complex and informal to be captured in rules. Turing left this as genuinely difficult.
The Extrasensory Perception Objection: If telepathy exists, the test would be compromised. Turing suggested screening the room for telepathic influences.
This structure reveals Turing as a serious philosopher engaging with the hardest objections to his position, not a naive optimist about machine capability. The paper is still worth reading in its entirety.
Turing's Own Background
Turing's interest in machine intelligence was not purely abstract. During World War II, he had worked at Bletchley Park on the electromechanical bombes that broke the German Enigma cipher, directly observing what machines could do that seemed to require human-like reasoning.
His post-war work at the National Physical Laboratory and Manchester University further immersed him in the question of what computation could and could not achieve.
Turing was also profoundly influenced by his familiarity with the question of other minds, the philosophical problem of how we know that other people are conscious, given that we only have access to their behavior.
His test is explicitly an extension of this problem to machines: if we attribute intelligence to other humans based on behavioral evidence, why should the same behavioral evidence be insufficient for machines?
How the Test Works in Practice
The modern version of the Turing Test simplifies the original setup. In the standard formulation:
- A human judge types messages to two respondents simultaneously, one human, one machine.
- Both respondents answer in text, attempting to appear human.
- After a fixed conversation period (typically five minutes in formal contests), the judge decides which is the human.
- If the machine fools the judge more than 30% of the time across multiple judges, some researchers consider it to have passed.
This is the version evaluated at the Loebner Prize, an annual competition founded in 1990 by Hugh Loebner and the Cambridge Center for Behavioral Studies.
The prize has awarded bronze medals each year to the most convincing chatbot, with gold and silver medals reserved for systems that can handle audio and video inputs, awards that have never been claimed.
| Year | Notable Entrant | Result |
|---|---|---|
| 1991 | PC Therapist (Joseph Weintraub) | First Loebner winner |
| 2008 | Elbot | Fooled 25% of judges |
| 2014 | Eugene Goostman | Fooled 33% of judges, generated headlines |
| 2016 | Mitsuku (Steve Worswick) | Won Loebner Prize; went on to win five times |
| 2022 | GPT-4 era models | Not formally entered; informal tests show high deception rates |
The 2014 result with Eugene Goostman attracted significant press coverage, with some outlets declaring that the Turing Test had been officially passed. Most AI researchers pushed back hard. Eugene Goostman was programmed to role-play as a 13-year-old Ukrainian boy, which gave it cover for awkward responses and limited knowledge.
Judges lowered their expectations accordingly. The test's threshold was met, but the achievement said more about the test's flaws than about machine intelligence.
Shane Legg, co-founder of DeepMind, commented at the time that the result demonstrated "how low the bar of the test is, not how intelligent the system is." The episode was useful precisely because it forced the AI community to confront the test's insufficiency as a benchmark for genuine intelligence.
Criticisms of the Turing Test
The test has faced criticism from multiple directions over the past 75 years. Some criticisms attack its validity. Others accept its validity but argue about what it actually measures.
It Rewards Deception, Not Intelligence
The Turing Test does not measure knowledge, reasoning, or understanding. It measures the ability to convincingly impersonate a human in a text conversation. A system can pass by being evasive, changing the subject, making grammatical errors on purpose, or flattering the judge, all without any genuine comprehension.
ELIZA, created by Joseph Weizenbaum at MIT in the 1960s, was a simple pattern-matching program that simulated a Rogerian psychotherapist by reflecting users' statements back as questions.
Weizenbaum was disturbed to find that users, including his own secretary, developed emotional attachments to ELIZA despite knowing it was a program.
ELIZA could not have passed a rigorous Turing Test, but it demonstrated how easily humans are fooled by the appearance of understanding.
Weizenbaum's experience was so disturbing to him that he devoted his 1976 book Computer Power and Human Reason to arguing that certain human functions should not be delegated to machines, regardless of whether machines could simulate performing them.
The ELIZA effect, the human tendency to attribute understanding and empathy to systems that merely pattern-match, is now a recognized psychological phenomenon studied in human-computer interaction research (Epley, Waytz, & Cacioppo, 2007).
The Chinese Room: Can Symbol Manipulation Mean Understanding?
The most famous philosophical challenge to the Turing Test came from philosopher John Searle in 1980. His Chinese Room argument proceeds as follows:
Imagine a person locked in a room. They do not speak Chinese. Through a slot in the door, they receive pieces of paper with Chinese symbols.
They have a rulebook (written in English) that tells them how to respond: "When you see symbol X followed by symbol Y, output symbol Z." By following the rules precisely, the person produces Chinese responses that a native Chinese speaker outside the room finds perfectly natural.
From outside, the room appears to understand Chinese. From inside, there is no understanding at all, only rule-following.
Searle's point is that programs manipulate symbols according to formal rules, but this syntactic manipulation does not produce semantics, meaning, understanding, or intentionality. A machine could pass the Turing Test through symbol manipulation alone, which means passing the test does not imply genuine intelligence or consciousness.
Defenders of strong AI have offered several rebuttals (the Systems Reply, the Robot Reply, the Brain Simulator Reply), but Searle's argument remains the most cited philosophical challenge to the idea that computation equals cognition.
The Systems Reply argues that while the person in the room does not understand Chinese, the system as a whole, person plus rulebook plus room, does understand. Searle responds by having the person internalize the rulebook: even if they memorize all the rules, there is still no understanding, only syntax.
This exchange has continued for 45 years without clear resolution, suggesting that the question of what constitutes understanding may be more difficult than either side initially acknowledged.
It Measures the Wrong Thing
Psychologist Gary Marcus and others have argued that the Turing Test is poorly calibrated as a benchmark because it tests a narrow slice of intelligence: the ability to hold a five-minute casual conversation.
It does not test mathematical reasoning, spatial navigation, long-term planning, emotional regulation, creativity, or learning from novel experience.
Marcus and Davis (2019) argued in Rebooting AI that the test is specifically poorly calibrated for modern AI systems, which are simultaneously able to beat humans at certain games and unable to correctly interpret common visual metaphors.
The profile of AI capability is so different from human intelligence that the Turing Test's single behavioral dimension provides almost no useful information about the AI's actual capabilities or limitations.
A system could score perfectly on the Turing Test while being completely incapable of solving a basic algebra problem or navigating a new physical environment, capabilities we associate with general intelligence.
The Problem of Sophisticated Deception
A more contemporary criticism is that as AI systems become more capable, the Turing Test becomes actively misleading rather than merely insufficient.
Modern large language models can pass the Turing Test not because they have human-level general intelligence, but because they have been specifically trained on vast quantities of human text and are therefore very good at producing human-like text.
This is a specific capability, not general intelligence, but the Turing Test cannot distinguish between them.
Floridi and Chiriatti (2020) made this argument explicitly in the context of GPT-3, demonstrating that GPT-3 could pass conversational tests while failing dramatically on tasks requiring simple causal reasoning, and that the conversational fluency masked rather than revealed this limitation to casual users.
Why Large Language Models Pass but Are Not Conscious
Modern large language models (LLMs) like GPT-4, Claude, and Gemini can easily hold conversations that fool most people in informal tests. They write with coherent style, make contextually appropriate jokes, express apparent preferences, and generate responses that feel deeply human.
In that narrow sense, they pass something like the Turing Test routinely.
But passing the test tells us little about what is actually happening inside these systems.
LLMs are trained on hundreds of billions of tokens of text using a self-supervised objective: predict the next word. Through this process, they develop extraordinarily rich statistical representations of language and the knowledge encoded within it.
When they "answer" a question about history or express an "opinion" about art, they are generating statistically likely continuations of text given their training.
A useful analogy is the stochastic parrot metaphor introduced by Bender, Gebru, McMillan-Major, and Schmitchell (2021): large language models are systems for stitching together plausible sequences of language tokens based on statistical patterns learned from text, without any grounding in the world the language refers to.
The metaphor is contentious, critics argue it understates what emerges from large-scale language modeling, but it captures something important about the mechanism.
There is currently no scientific consensus that this process produces:
- Consciousness: subjective experience, the "what it is like" quality (qualia)
- Intentionality: genuine reference to things in the world
- Understanding: semantic comprehension rather than syntactic pattern matching
- Self-awareness: accurate introspective access to internal states
This does not mean LLMs are definitely not conscious. It means we do not have good tools to determine the answer. The hard problem of consciousness, explaining why physical processes give rise to subjective experience, remains unsolved even for biological systems, as philosopher David Chalmers articulated in The Conscious Mind (1996).
We attribute consciousness to other humans largely through behavioral inference and analogy to our own experience. LLMs introduce a new category of entity for which our existing frameworks are insufficient.
Butlin et al. (2023), in a paper titled "Consciousness in Artificial Intelligence: Insights from the Science of Consciousness," surveyed 14 major theories of consciousness and evaluated current AI systems against each.
Their conclusion: no current AI systems are clearly conscious by the criteria of any major theory, but the question is genuinely open for future systems, and the field currently lacks the tools to resolve it definitively.
What Better Tests Exist
Researchers have developed several alternative benchmarks that are harder to pass through pattern matching and more directly targeted at specific dimensions of intelligence.
The Winograd Schema Challenge
Proposed by Hector Levesque, Ernest Davis, and Leora Morgenstern in 2012, the Winograd Schema Challenge presents pronoun disambiguation problems that require commonsense reasoning.
Example: "The trophy didn't fit in the suitcase because it was too big. What was too big?"
Answering correctly requires understanding physical reality: objects can be too big to fit in containers. The pronoun "it" is syntactically ambiguous, it could refer to either the trophy or the suitcase, but the correct referent is clear to any human with basic world knowledge.
These problems are extremely difficult to solve through statistical pattern matching because the answer depends on understanding physical and social reality, not just linguistic co-occurrence patterns.
The challenge was proposed specifically as an alternative to the Turing Test, a rigorous test of specific reasoning capability rather than conversational plausibility.
Modern large language models now perform at roughly 90% on the Winograd Schema Challenge, approaching human performance, which has led researchers to develop even harder variants and complementary benchmarks.
ARC-AGI: Measuring Fluid Intelligence
The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI), developed by AI researcher Francois Chollet and launched with a competitive benchmark in 2024, tests a specific form of general intelligence: the ability to infer rules from a small number of examples and apply them to novel cases.
Each ARC-AGI task presents a few input/output pairs of colored grids, and the solver must infer the transformation rule and apply it to a new input. The tasks require core knowledge priors (object permanence, counting, symmetry, spatial relationships) that humans apply effortlessly.
Chollet designed ARC-AGI explicitly to be resistant to the memorization and pattern-matching approaches that allow LLMs to score well on many benchmarks: "Current AI systems are not generally intelligent.
They have impressive narrow capabilities but struggle with tasks requiring genuine abstraction and flexible reasoning. ARC is designed to measure this gap" (Chollet, 2019).
| Test | What It Measures | Current AI Performance | Human Performance |
|---|---|---|---|
| Turing Test | Human-like conversation | LLMs routinely pass informal versions | N/A (baseline) |
| Winograd Schema | Commonsense reasoning | LLMs perform at ~90%, near human levels | ~95% |
| ARC-AGI | Novel rule inference from few examples | Best systems ~30-50% | ~85% |
| MATH benchmark | Mathematical reasoning | LLMs ~50-85% depending on difficulty | ~95% for undergrads |
| BIG-Bench Hard | Diverse reasoning tasks | Frontier models ~60-70% | ~90% |
ARC-AGI is deliberately designed to resist memorization. Because each task uses novel grid configurations, a model cannot succeed by remembering similar training examples. It must generalize.
The Total Turing Test
Philosopher Stevan Harnad proposed the Total Turing Test as an extension requiring not just text communication but also the ability to perceive and act in the physical world, responding to visual inputs, manipulating objects, and navigating environments.
This would require general sensorimotor intelligence far beyond what current systems possess.
The Total Turing Test is rarely discussed as a practical benchmark because no current system comes close to meeting it. But it is philosophically useful because it highlights how the standard Turing Test's text-only channel allows deception through linguistic fluency alone, while embodied intelligence is much harder to fake.
Collaborative and Creative Benchmarks
More recent proposals focus on tests that require sustained collaboration, creative problem-solving, and genuine novelty:
MMMU (Massive Multidisciplinary Multimodal Understanding) requires answering expert-level questions across 30 academic disciplines using both text and images. Frontier models score roughly 50-60%, compared to expert human performance of 80-90%.
GPQA (Graduate-Level Google-Proof Questions) presents questions specifically designed so that they cannot be answered by searching the web, they require genuine expert reasoning in biology, physics, and chemistry. GPT-4 scores around 40%, compared to PhD-level experts at 65%.
These benchmarks operationalize dimensions of intelligence that the Turing Test ignores entirely, providing much more informative signals about AI capability and its limits.
The Consciousness Question: What We Still Don't Know
The most profound implication of the Turing Test debate is the realization that consciousness, the thing we most want to attribute or deny to AI systems, is poorly understood even in the biological systems we are most confident possess it.
The philosopher Thomas Nagel's 1974 paper "What Is It Like to Be a Bat?" established the core problem: even if we knew everything about bat neuroscience, we would not know what it is subjectively like to experience the world via echolocation.
The subjective, first-person character of experience cannot be captured by third-person scientific description.
Applied to AI, this creates a fundamental epistemic barrier: no behavioral test, including the Turing Test, can conclusively demonstrate presence or absence of consciousness, because consciousness is by definition a first-person phenomenon and behavioral tests are third-person measurements. We can test behavior. We cannot test experience.
This is not just a philosophical curiosity. As AI systems become more sophisticated and are deployed in contexts where users form genuine emotional relationships with them, therapy chatbots, social companions, educational assistants, the question of whether these systems have any morally relevant inner life has practical ethical implications.
If AI systems can suffer or flourish in some meaningful sense, our obligations toward them differ from our obligations toward calculators.
Gabriel (2021) and others in the emerging field of machine ethics argue that we need frameworks for AI moral status that do not depend on resolving the hard problem of consciousness, practical guidelines for treating AI systems that take seriously the uncertainty about their inner lives.
Why the Turing Test Still Matters
Despite its limitations as a benchmark, the Turing Test remains intellectually significant for several reasons.
It operationalized the question. Before Turing, asking whether machines could think was largely a philosophical or science-fiction exercise. Turing turned it into an empirical question with testable implications. That move shaped the entire trajectory of AI research.
It identified the right problem. The test captures something real: that behavioral equivalence creates genuine uncertainty about inner states.
If a machine responds to every input in ways indistinguishable from a conscious entity, the practical question of how to treat it becomes urgent regardless of whether it is "really" conscious.
It forces clarity about what we mean by intelligence. Every criticism of the Turing Test has led to more precise thinking about what distinguishes genuine cognition from its simulation, from Searle's intentionality to Chollet's fluid reasoning to Chalmers' hard problem of consciousness.
It predicted a real milestone. Turing's 1950 prediction that computers would be capable of fooling trained human judges in five-minute conversations within fifty years was remarkably accurate. Modern LLMs can fool most casual users indefinitely.
The test's enduring legacy is not as a definitive measure of machine intelligence but as a philosophical provocation that forced humanity to be more precise about what it means to think, to understand, and to be intelligent.
The Stakes: Why This Matters Now
The Turing Test was a thought experiment when computing was in its infancy. Today, LLMs are deployed in customer service, education, mental health support, legal research, and countless other domains where users form genuine relationships with AI systems and rely on their outputs for consequential decisions.
A 2023 survey by the Pew Research Center found that 55% of American adults had heard of ChatGPT, and 18% had used it, with substantially higher rates among younger and more educated users.
The deployment of conversational AI at this scale means that questions about machine intelligence that were once academic have become design problems with immediate consequences.
The question of whether these systems truly understand, or are sophisticated pattern-matchers that simulate understanding, has practical consequences:
- Reliability: Systems that pattern-match without understanding may fail catastrophically in novel situations that fall outside their training distribution.
- Accountability: When an AI gives harmful advice, determining moral and legal responsibility requires understanding whether the system was following rules or exercising judgment.
- Rights and status: As AI systems become more sophisticated, questions about their moral status, currently purely theoretical, may become legally and ethically pressing.
- User trust calibration: Users who cannot distinguish machine comprehension from simulation may systematically over-rely on AI outputs in domains where that reliance is dangerous.
"The question is not whether machines can think. The question is whether the difference between a machine that thinks and a machine that perfectly simulates thinking is meaningful, and for whom.", paraphrased from Daniel Dennett's Consciousness Explained
Turing himself was skeptical of the deep philosophical questions. He was a pragmatist who believed that if a machine behaves intelligently in every observable respect, debating its inner life was a distraction from the real work of building and understanding computational systems.
That pragmatic attitude is increasingly influential as AI capabilities outpace our theoretical frameworks. We do not need to resolve the hard problem of consciousness to make decisions about how to design, deploy, and regulate AI systems.
But the Turing Test, and the debates it generated, gave us the vocabulary and conceptual tools to even begin asking the right questions.
Conclusion
Alan Turing proposed the Imitation Game to sidestep an unanswerable question and replace it with a tractable one. Seventy-five years later, machines routinely pass versions of the test he described, not because they think, but because thinking and its simulation have become, at least superficially, indistinguishable.
The test's limitations are real: it rewards deception, measures a narrow capability, and cannot distinguish genuine understanding from sophisticated pattern matching. The Chinese Room argument remains a serious philosophical challenge.
Better benchmarks like ARC-AGI, the Winograd Schema Challenge, and GPQA probe deeper dimensions of reasoning that LLMs still struggle with.
But the Turing Test accomplished something extraordinary. It took one of the most profound questions about minds and machines and made it a subject for science rather than speculation.
Every AI researcher working on reasoning, language, and general intelligence is, in some sense, still grappling with the questions Turing raised in that 1950 paper.
Whether machines will ever truly think remains open. Whether they will increasingly behave as if they do is no longer in doubt.
Sources & Further Reading
- Turing, A. M. (1950). Computing Machinery and Intelligence. Mind, 59(236), 433-460.
- Searle, J. R. (1980). Minds, Brains, and Programs. Behavioral and Brain Sciences, 3(3), 417-424.
- Levesque, H., Davis, E., & Morgenstern, L. (2012). The Winograd Schema Challenge. Proceedings of the 13th International Conference on the Principles of Knowledge Representation and Reasoning.
- Chollet, F. (2019). On the Measure of Intelligence. arXiv preprint arXiv:1911.01547. View source
- Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency.
- Butlin, P., et al. (2023). Consciousness in Artificial Intelligence: Insights from the Science of Consciousness. arXiv preprint arXiv:2308.08708.
- Chalmers, D. J. (1996). The Conscious Mind: In Search of a Fundamental Theory. Oxford University Press.
- Dennett, D. C. (1991). Consciousness Explained. Little, Brown and Company.
- Floridi, L., & Chiriatti, M. (2020). GPT-3: Its Nature, Scope, Limits, and Consequences. Minds and Machines, 30(4), 681-694.
- Marcus, G., & Davis, E. (2019). Rebooting AI: Building Artificial Intelligence We Can Trust. Pantheon Books.
- Nagel, T. (1974). What Is It Like to Be a Bat? The Philosophical Review, 83(4), 435-450.
- Epley, N., Waytz, A., & Cacioppo, J. T. (2007). On Seeing Human: A Three-Factor Theory of Anthropomorphism. Psychological Review, 114(4), 864-886.
- Weizenbaum, J. (1976). Computer Power and Human Reason: From Judgment to Calculation. W. H. Freeman and Company.
Frequently Asked Questions
What is the Turing Test?
The Turing Test is a method for evaluating machine intelligence proposed by Alan Turing in his 1950 paper ‘Computing Machinery and Intelligence.’ A human judge holds text conversations with both a human and a machine without knowing which is which. If the judge cannot reliably tell them apart, the machine is said to have passed the test.
Has any AI passed the Turing Test?
Several programs have claimed to pass the Turing Test under specific contest conditions, most notably the chatbot Eugene Goostman in 2014, which convinced 33% of judges it was human. However, most AI researchers consider these results to be more a reflection of the test’s weaknesses than genuine machine intelligence.
What is Searle's Chinese Room argument?
Philosopher John Searle’s 1980 Chinese Room thought experiment argues that passing the Turing Test does not imply understanding. In the scenario, a person who does not know Chinese follows rules to respond to Chinese symbols correctly without understanding the language. Searle uses this to argue that symbol manipulation alone cannot produce genuine comprehension or consciousness.
Why do large language models pass the Turing Test but may not be conscious?
Large language models like GPT-4 can produce convincing human-like text by predicting statistically likely word sequences based on vast training data. They can fool human judges in short conversations, but this is because they excel at surface-level pattern matching. There is no scientific consensus that this process involves subjective experience, intentionality, or consciousness.
What are better alternatives to the Turing Test?
Researchers have proposed several more rigorous tests. The Winograd Schema Challenge tests commonsense reasoning through pronoun disambiguation problems. The ARC-AGI benchmark (by Francois Chollet) measures general fluid intelligence using novel pattern recognition. These tests are harder to game through memorization and better distinguish genuine reasoning from statistical pattern matching.