In 1997, IBM's Deep Blue defeated world chess champion Garry Kasparov. In 2011, Watson won Jeopardy against all-time champions. In 2016, AlphaGo beat the world's best Go player. Each milestone prompted the same breathless question: has AI surpassed human intelligence?
Each time, the answer was the same - no, it had surpassed humans at one specific task. A chess engine cannot write a poem. Watson cannot comfort a grieving friend. AlphaGo cannot cross a busy street.
The comparison between artificial and human intelligence is not a race along a single dimension but a study in fundamentally different architectures producing fundamentally different capabilities.
The question "is AI smarter than humans?" is similar in structure to "is a calculator better at arithmetic than a human?" - the answer is obviously yes, but the question is not particularly interesting.
What is interesting is understanding where the differences lie, why they exist, and what they imply for how AI and human intelligence might best work together.
The year 2026 is particularly revealing as a moment for this comparison. Large language models now pass bar exams, generate commercially published music, write code deployed in production systems, and engage in apparently sophisticated reasoning across domains.
The easy answers - "AI is just pattern matching" or "AI will never really understand anything" - have become harder to sustain while remaining genuinely uncertain.
A clear-eyed examination of what current AI systems actually do, how they compare to what humans do, and where the meaningful differences lie is more useful than either dismissiveness or uncritical awe.
What Current AI Systems Do Well
"Current AI systems are extraordinarily capable narrow tools. The moment we imagine they are general intelligences - that they understand in the way we understand - we set ourselves up for predictable failures." - Gary Marcus, Rebooting AI, 2019
| Capability | AI Advantage | Human Advantage | Current State (2026) |
|---|---|---|---|
| Pattern recognition at scale | Processes millions of examples; consistent accuracy; no fatigue | Robust generalization from few examples; handles novel categories | AI exceeds human performance on well-defined classification tasks |
| Language understanding | Fluent generation across any topic; multilingual; fast | True comprehension, common-sense grounding, world model | AI fluent but unreliable; hallucination remains a systematic problem |
| Mathematical computation | Perfect arithmetic; symbolic manipulation; exhaustive search | Mathematical creativity; novel proof construction | AI strong on calculation, weak on genuinely novel problem-solving |
| Physical world navigation | Excellent in structured, predictable environments | Robust generalization to unexpected situations; embodied intuition | Autonomous vehicles functional in limited conditions; general robotics unsolved |
| Social and emotional intelligence | Simulates appropriate responses; reads text cues | Genuine emotional experience; rapport built through shared vulnerability | AI mimics social intelligence; does not experience or genuinely understand it |
| Creative production | Generates enormous volume of plausible content quickly | Intentional creativity; meaningful novelty; genuine expression | AI outputs are impressive statistically; breakthrough originality rare |
| Long-term planning | Effective within well-defined state spaces and reward functions | Flexible goal revision; value prioritization; uncertainty tolerance | AI strong in constrained domains; poor at open-ended long-horizon planning |
The capabilities of current AI systems are broad and in many domains genuinely impressive. Understanding specifically where AI excels - and why - provides the foundation for meaningful comparison.
Pattern Recognition at Scale
AI systems, particularly deep neural networks, excel at recognizing patterns in large datasets. Image recognition systems can identify thousands of object categories with accuracy exceeding the best human performance.
Speech recognition systems transcribe human speech with error rates lower than professional human transcribers in many contexts.
Medical imaging AI identifies cancer and other conditions in X-rays, MRIs, and pathology slides with accuracy comparable to or exceeding specialists.
The mechanism is consistent: AI pattern recognition is trained on large labeled datasets, learning statistical features that distinguish one category from another. When the training distribution matches the deployment distribution, accuracy can be exceptional.
The limitation is that AI pattern recognition depends on this distributional match - it does not understand what it is recognizing in the way that humans understand.
Example: Google's retinal screening AI, developed by Google with datasets from clinics in India and the US, identifies diabetic retinopathy from retinal photographs with accuracy matching the best specialist ophthalmologists.
In a 2016 JAMA paper (Gulshan et al.), the system achieved greater than 90% sensitivity and specificity on a large validation dataset.
The system has since been deployed in clinical settings in multiple countries, genuinely expanding access to screening in under-resourced healthcare systems.
This is a case where AI pattern recognition is not just comparable to human performance - it is scalably deployable in ways that human specialists are not.
Language Processing and Generation
Large language models - GPT-4, Claude, Gemini, and their successors - demonstrate capabilities in language that have surprised even their developers.
They can engage in extended conversations, answer questions across domains, generate creative writing in multiple styles, explain complex concepts, translate between languages, and perform many language-based reasoning tasks at levels that benchmark well against human performance.
In 2023, GPT-4 passed the bar exam at roughly the 90th percentile of test takers - meaning it performed better than 90% of human law school graduates who take the test. In the same year, it passed medical licensing exams with scores that would qualify for medical practice.
These are not trivial achievements; they represent genuine capability in domains that have historically required years of human training.
The qualification matters: passing an exam is not the same as practicing medicine or law competently. Medical practice requires integrating textbook knowledge with physical examination, patient communication, emotional intelligence, and clinical judgment developed through experience.
The exam measures a subset of required competencies; it does not measure the full picture.
Complex Game Playing and Optimization
AI systems have dominated human performance in well-defined strategic environments. Beyond chess and Go, DeepMind's AlphaFold has essentially solved a fifty-year protein structure prediction problem that was expected to take decades more human research.
DeepMind's AlphaTensor discovered novel matrix multiplication algorithms that eluded decades of mathematical research. These achievements represent genuine scientific contributions, not merely impressive performance in predefined games.
Example: AlphaFold 2, released in 2020, predicted protein structures with accuracy previously achievable only through expensive experimental methods.
The European Bioinformatics Institute used AlphaFold to predict structures for nearly all known protein sequences, creating a database of over 200 million protein structures freely available to researchers worldwide.
Discoveries enabled by this database were being published at a rate impossible under previous research paradigms. This represents AI genuinely advancing the frontier of human scientific knowledge.
What Humans Do That AI Systems Do Not
The capabilities where human intelligence clearly exceeds current AI systems illuminate the nature of the difference between the two.
Common Sense and Embodied Understanding
Human intelligence is grounded in physical experience of the world. We understand that water is wet because we have touched water. We understand that fire is dangerous because we have experienced heat. We know what tired feels like because we have been tired.
This embodied knowledge is so pervasive in human cognition that we are largely unconscious of it, but it underlies an enormous range of reasoning that current AI systems struggle with.
AI systems can state facts about physical properties of the world but often fail in reasoning tasks that require applying common sense to novel situations. They may not reliably answer whether a heavy book would break a thin piece of ice, or whether a wet floor would be slippery to someone wearing socks.
These failures reveal that AI "knowledge" is patterns in text rather than models of physical reality grounded in experience.
The field of AI research has made progress on grounding - connecting language to physical experience through multimodal training on images, video, and sensor data. But current AI systems remain substantially weaker than humans at the kind of intuitive physical reasoning that children master before the age of five.
General Learning and Transfer
Humans learn new concepts quickly and transfer knowledge across distant domains with apparent ease. A person who has learned to ride a bicycle can transfer the concept of balance and coordination to roller skating and surfing.
A person who has learned to negotiate in a professional context applies those skills to personal relationships. A person who has studied history applies historical pattern recognition to current events.
AI systems are generally optimized for specific tasks and do not transfer well to different tasks. A language model that achieves human-level performance on reading comprehension benchmarks may fail completely on novel reasoning tasks that require similar underlying capabilities.
A model trained to classify images of cats does not automatically acquire the ability to classify dogs without substantial additional training.
This distinction - what researchers call "general intelligence" or "transfer learning" - is one of the most significant gaps between current AI systems and human intelligence.
Humans are remarkably general learners; current AI systems are remarkably specialized ones, achieving human or superhuman performance within defined domains but failing to generalize beyond them.
Example: Gary Marcus, a cognitive scientist and AI researcher, has documented numerous cases where large language models fail on tasks that would be trivially easy for most adults: understanding novel metaphors that require common sense to interpret, counting words in a sentence, reasoning about spatial relationships described in text.
These failures are revealing because the tasks are well within human capability and the failures are systematic rather than random - suggesting something structural about the difference between language model cognition and human cognition.
Social Intelligence and Emotional Understanding
Human intelligence is deeply social. We read emotional states from subtle facial expressions, vocal tones, and body language. We model other people's mental states, beliefs, and intentions (what researchers call "theory of mind").
We navigate complex social hierarchies, obligations, and norms. We form and maintain relationships characterized by genuine care, trust, and reciprocal investment.
Current AI systems simulate some of these capacities in language: they can describe emotional situations accurately, suggest appropriate responses to social situations, and engage in conversations that feel emotionally attuned.
But the underlying mechanism is pattern matching to training data rather than genuine emotional experience or social understanding.
This distinction has practical implications. AI systems can be genuinely helpful as conversational partners for working through problems, but they cannot replace the value of human relationships.
The therapist who has walked their own difficult path and genuinely cares about their client's wellbeing offers something categorically different from a language model producing therapeutically appropriate language patterns.
The friend who shows up when you are in crisis offers something categorically different from an AI that can simulate that conversation.
Creativity and Novel Problem Solving
The question of whether AI systems are genuinely creative remains genuinely contested. Current AI systems can generate music, visual art, poetry, and other creative content that is often indistinguishable from human output in blind evaluations.
They can propose solutions to problems that humans had not considered. They can combine ideas in ways that are novel with respect to any single source.
But the creativity of current AI systems is constrained by their training data: they can recombine and interpolate within the space of what they have seen but struggle with truly out-of-distribution creative leaps.
The mathematician who develops an entirely new area of mathematics, the artist who creates a new movement, the scientist who proposes a revolutionary paradigm - these forms of creativity that genuinely extend the boundary of human knowledge rather than recombining what already exists within that boundary remain distinctly human achievements.
Example: In 2022, an AI-generated image won first prize at the Colorado State Fair's art competition in the "digital arts/digitally-manipulated photography" category. The creator used Midjourney to generate the image and was open about the process.
The result sparked substantial debate about whether AI-generated work constitutes art in a meaningful sense - not because the image was not aesthetically accomplished but because of questions about the nature of creativity when the generative intelligence is statistical pattern matching rather than intentional expression.
Architectural Differences Underlying the Capability Gap
The differences in capability between AI systems and human intelligence reflect fundamental architectural differences between how these two forms of intelligence are built.
Learning Mechanism
Humans learn from remarkably small amounts of data, especially for high-level concepts. A child who sees three instances of "dog" can recognize a novel dog with high accuracy. Large language models require training on hundreds of billions of text tokens to achieve their capabilities.
This sample efficiency difference reflects different learning architectures. Human learning benefits from strong inductive biases: built-in assumptions about the structure of the world (objects persist, causes precede effects, other agents have minds) that allow rapid generalization from limited experience.
Current deep learning systems learn these biases only if they are present in training data, and they require enormous amounts of data to extract them.
One-shot and few-shot learning - the ability to learn from very limited examples - is an active research area. Large language models show surprising few-shot capability: given a few examples of a task in the context window, they can often perform the task acceptably.
But this few-shot capability remains substantially weaker than human few-shot learning for most tasks.
Memory Architecture
Human memory is associative, reconstructive, and dynamic. We do not store memories as fixed records; we reconstruct them from fragments each time we retrieve them, with reconstruction influenced by subsequent experience and current context.
This architecture is error-prone in some ways but highly flexible - memories update as our understanding evolves.
Current AI systems have a different memory architecture. Their "knowledge" is encoded in model weights through training and does not update during deployment.
They can use context windows (recent conversational history) as temporary working memory, but this working memory is typically limited to tens or hundreds of thousands of tokens and is not persistent across sessions.
This architectural difference has significant practical implications: AI systems do not learn from individual interactions in the way that humans learn from experience. A language model that has a conversation does not update its underlying capabilities based on that conversation; the next user starts from the same baseline.
Building persistent learning into AI systems - allowing them to update from deployment experience - raises significant alignment challenges (how to ensure the updates do not degrade safety properties) that are active areas of research.
Embodiment and Sensorimotor Grounding
Human intelligence developed in and remains deeply integrated with a physical body. Cognition is not separate from sensation and movement but is shaped by the fact that intelligence evolved to control physical behavior in physical environments.
The philosopher Hubert Dreyfus spent decades arguing that this embodied, embedded nature of human cognition is what makes many aspects of human intelligence so difficult to replicate in purely symbolic or statistical systems.
Current large language models are disembodied: they process text (and images) without any connection to physical experience or action. Robotics and multimodal AI research is working to create AI systems that are more embodied - that act in physical environments and learn from physical experience.
But the integration of physical embodiment with the abstract language capabilities of current large language models remains a significant open research challenge.
The Collaboration Paradigm
The most productive framing for the AI vs. human intelligence comparison is not competition but complementarity. The capabilities that AI systems have and humans lack, and the capabilities that humans have and AI systems lack, point toward collaboration patterns that outperform either working alone.
Where AI Augments Human Intelligence
Information processing: Humans are limited in how much information they can process and retain. AI systems can process vast amounts of information and present synthesized, relevant summaries.
A doctor who uses AI to review a patient's complete medical history, flag drug interactions, and suggest differential diagnoses that warrant consideration is practicing medicine augmented by capabilities that extend what any individual physician can do.
Consistency and availability: Human performance varies with fatigue, emotional state, and distraction. AI systems provide consistent performance regardless of these factors. AI systems can be available continuously, in any language, without the staffing constraints that limit human availability.
This makes AI particularly valuable for high-volume, consistent tasks where variation in performance quality is costly.
Speed and scale: AI systems can perform certain tasks much faster than humans and can scale to serve many users simultaneously. Medical image screening AI can review thousands of images per day; a human radiologist can review hundreds.
The scale advantage is not merely efficiency - it enables capabilities (universal screening of populations, real-time processing of large data streams) that are simply not possible with human-only approaches.
Where Humans Augment AI Systems
Judgment on edge cases: AI systems perform well on the center of the distribution of their training data and struggle on edge cases and out-of-distribution inputs. Human judgment - particularly expert judgment - remains more reliable for unusual, complex, or high-stakes situations that fall outside the AI's training distribution.
Ethical reasoning and accountability: Decisions that involve ethical trade-offs - that require weighing competing values, considering stakeholder interests, and accounting for consequences that are difficult to specify in advance - benefit from human judgment and require human accountability.
An AI system can surface ethical considerations and model consequences, but the responsibility for ethically weighty decisions belongs with humans.
Trust and relationship: Many domains where AI could technically provide capable assistance also depend on trust, relationship, and human connection for their effectiveness.
Medical care, education, counseling, management - the technical competence component can be augmented by AI, but the relational component remains distinctively human in value.
Example: The pathology company Paige.AI uses AI to assist pathologists in reviewing cancer biopsies, flagging concerning areas for pathologist attention and providing quantitative measurements.
The AI functions as a tool that extends the pathologist's capacity and consistency; the pathologist provides the clinical judgment, the integration of pathology findings with patient context, and the accountability for diagnosis. Neither alone achieves what they achieve together.
This augmentation model - AI handling the pattern recognition at scale, humans providing the judgment, context, and accountability - is the design pattern emerging across high-stakes applications.
Intelligence as a Spectrum, Not a Hierarchy
The temptation to rank AI and human intelligence on a single scale - who is smarter? who is better? - reveals a fundamental misconception about the nature of intelligence. Intelligence is not a single dimension but a vast multidimensional space of capabilities, and AI systems and humans occupy very different regions of that space.
Current AI systems are extraordinarily capable in some dimensions: they can process language, generate content, recognize patterns, and reason within their training distribution in ways that are genuinely impressive and increasingly economically significant.
They are extraordinarily limited in other dimensions: embodied understanding, general learning, genuine creativity, social intelligence, and the judgment that comes from lived experience with consequences.
Humans are extraordinarily capable in their own dimensions: general intelligence, social cognition, embodied understanding, creativity, and moral reasoning.
They are limited by their biological architecture: slow information processing, limited working memory, susceptibility to cognitive biases, emotional regulation costs, and finite time.
The practical question - for individuals, organizations, and society - is not which form of intelligence is superior but how to combine them to produce outcomes neither could achieve alone.
That combination, thoughtfully designed, is where the genuine promise of AI lies: not in replacing human intelligence but in extending what human intelligence can accomplish.
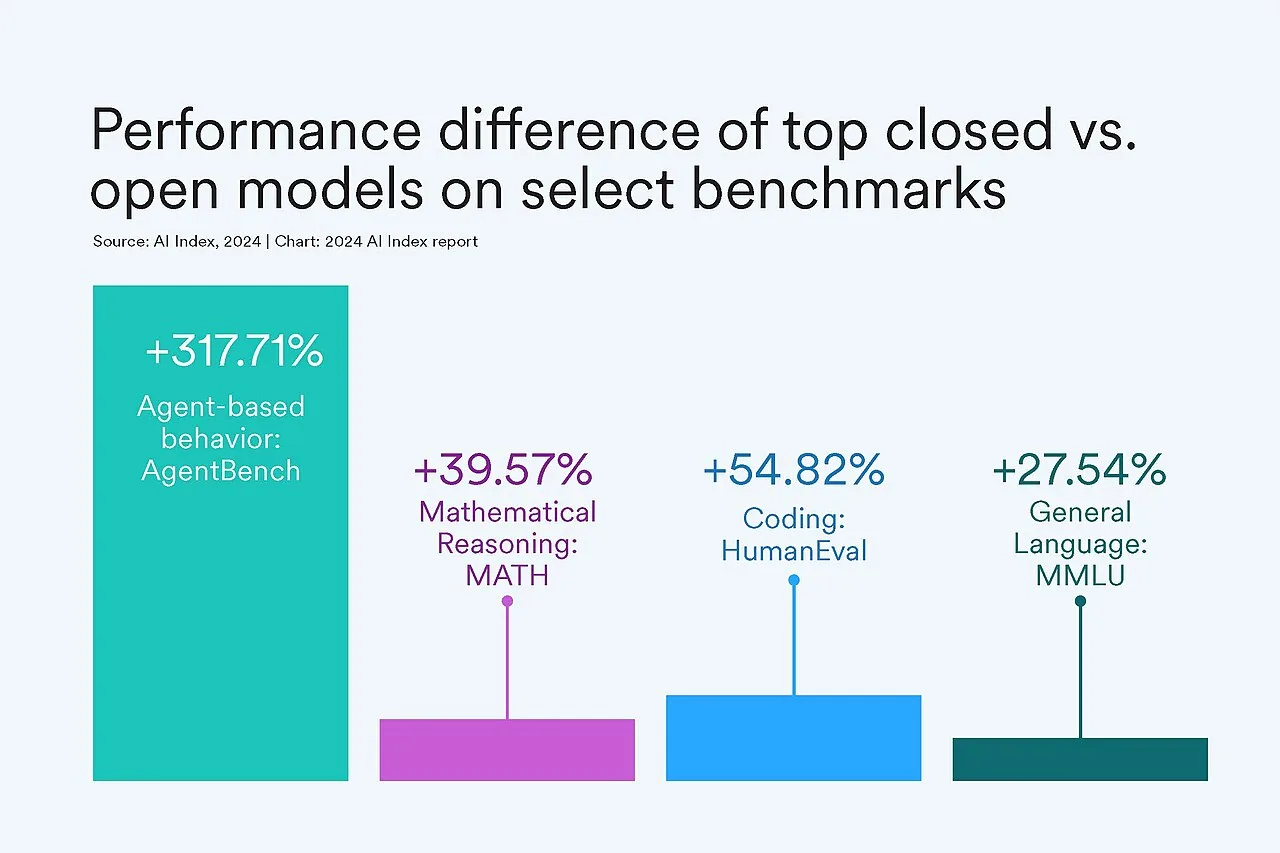
Benchmark Evidence: Where the Performance Gap Has Closed
Systematic benchmarking across cognitive domains provides the most rigorous evidence for where AI has achieved parity or superiority over human performance, and where it has not.
The MMLU benchmark (Massive Multitask Language Understanding), developed by Dan Hendrycks at UC Berkeley and colleagues in 2020, tests performance across 57 academic subjects from elementary mathematics to professional law. When published, human experts scored approximately 89.8 percent on their domains.
GPT-3 scored 43.9 percent. GPT-4, evaluated in 2023, scored 86.4 percent overall, approaching expert human performance across domains. By 2024, frontier models were achieving scores above 90 percent, technically exceeding the human expert benchmark on this measure.
However, Hendrycks and colleagues published follow-up work in 2024 documenting that models scoring above human benchmarks on MMLU still showed systematic failures on MMLU-Pro, a harder variant requiring multi-step reasoning, where human performance was 72 percent and the best AI systems scored 62 percent.
Varun Gulshan at Google Health and colleagues published a landmark study in JAMA in 2016 demonstrating that a deep learning algorithm trained on 128,175 retinal photographs could detect diabetic retinopathy with a sensitivity of 97.5 percent and specificity of 93.4 percent, exceeding the average performance of eight ophthalmologists on the same dataset.
A follow-up study in Nature Medicine in 2018, led by Lily Peng at Google, extended the finding to multiple eye diseases simultaneously and found the AI system matched specialist performance on a 12-condition classification task.
By 2023, the system had been validated in real-world deployment across Thailand, India, and other countries with limited specialist access, screening over 300,000 patients in settings where ophthalmologists were unavailable.
Gary Marcus at New York University and colleagues have documented the counterpoint systematically. A 2022 paper examining large language model performance on abstract reasoning tasks found that GPT-3 scored only 3 percent on Raven's Progressive Matrices, a test of fluid intelligence where average adult humans score around 50 percent.
Even GPT-4 scored significantly below human average on novel pattern completion tasks designed to prevent memorization from training data.
Marcus argues these results reveal that language models achieve high benchmark scores through memorization and interpolation rather than general reasoning, a position supported by findings that model performance drops substantially when benchmark formats are slightly modified.
Francois Chollet at Google Brain designed the ARC (Abstraction and Reasoning Corpus) benchmark in 2019 specifically to test general intelligence by using visual pattern tasks requiring flexible rule induction from a handful of examples. Average adult humans score approximately 85 percent on ARC.
As of 2024, the best AI systems score approximately 34 percent, and models that perform well on ARC tend to have been specifically optimized for it rather than demonstrating general transfer.
The ARC prize competition, launched in 2024 with a $1 million award for achieving 85 percent, has attracted substantial research attention as a practical test of human-level general reasoning.
Human-AI Collaboration Outcomes: Evidence from High-Stakes Domains
The most practically consequential question is not whether AI outperforms humans in isolation, but how human-AI teams perform relative to either alone, particularly in high-stakes professional settings.
Babak Ehteshami Bejnordi at Radboud University Medical Center and colleagues organized a rigorous comparison study published in JAMA in 2017. Twenty-three pathologists competed against deep learning algorithms in detecting lymph node metastases from breast cancer tissue slides.
The best individual pathologist achieved an AUC of 0.966; the best algorithm achieved 0.994. The human-AI team, with a pathologist given access to the algorithm's output for ambiguous cases, achieved 0.995 with a 85 percent reduction in the error rate compared to the pathologist alone.
The finding that human-AI teams outperformed either alone became influential in shaping clinical AI deployment frameworks.
Ethan Mollick at the Wharton School conducted a series of controlled experiments in 2023 examining GPT-4's performance compared to MBA students and consultants on realistic business tasks.
In a study of 758 Boston Consulting Group consultants, those using GPT-4 completed tasks 25 percent faster and produced outputs rated 40 percent higher quality than consultants without AI access.
Critically, performance gains were largest for tasks within GPT-4's competency range: consultants using AI on tasks outside its ability performed worse than those not using AI, suggesting that knowing when not to rely on AI is a critical skill.
Reid Blackman at Virtue Consulting documented a counterexample in legal services: a study of contract lawyers using AI-assisted review found that lawyers given AI-generated preliminary analyses were 15 percent more likely to miss errors that the AI had also missed, a phenomenon the researchers termed "automation bias." The finding suggests that human-AI collaboration can produce worse outcomes than human alone when the AI's errors systematically align with human blind spots, and that appropriate skepticism toward AI outputs requires deliberate effort.
These results contributed to updated guidance from the American Bar Association on AI use in legal practice published in 2024.
See also: Practical AI Applications 2026, AI Safety and Alignment Challenges, and Future of AI: What's Coming Next.
Sources & Further Reading
- Marcus, Gary and Davis, Ernest. Rebooting AI: Building Artificial Intelligence We Can Trust. Pantheon, 2019. View source
- Mitchell, Melanie. Artificial Intelligence: A Guide for Thinking Humans. Farrar, Straus and Giroux, 2019. View source
- Jumper, John et al. "Highly accurate protein structure prediction with AlphaFold." Nature, 2021. View source
- Bubeck, Sebastien et al. "Sparks of Artificial General Intelligence: Early experiments with GPT-4." Microsoft Research, 2023. View source
- Dreyfus, Hubert. What Computers Can't Do: A Critique of Artificial Reason. Harper and Row, 1972.
- LeCun, Yann. "A Path Towards Autonomous Machine Intelligence." Meta AI Research, 2022. View source
- Gulshan, Varun et al. "Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs." JAMA, 2016. View source
- Kahneman, Daniel. Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011. View source
- Brynjolfsson, Erik and McAfee, Andrew. The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant Technologies. W.W. Norton, 2014. View source
- Silver, David et al. "A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play." Science, 2018. View source
Frequently Asked Questions
What does AI do better than humans?
Speed (process data instantly), scale (handle massive data), consistency (no fatigue), pattern recognition (in high-dimensional data), memory (perfect recall), and tirelessness. Excels at: repetitive tasks, computation, searching large spaces, and operating within defined parameters.
What do humans do better than AI?
Common sense reasoning, transferring knowledge across domains, few-shot learning (learn from few examples), causal reasoning, creativity (true novelty), emotional intelligence, ethical judgment, and handling novelty. Humans: flexible generalists, AI: narrow specialists.
Why can't AI match human common sense?
Common sense requires: world model built from embodied experience, causal understanding, intuitive physics, social reasoning, and context flexibility. AI lacks: physical grounding, life experience, causal models, and meta-cognitive awareness. Mimics common sense from patterns but doesn’t truly have it.
Do humans and AI think differently or similarly?
Fundamentally different: humans use embodied, causal, symbolic reasoning with consciousness. AI uses statistical pattern matching without understanding. Surface similarity (both solve problems) masks deep architectural differences. Humans: meaning-based. AI: correlation-based. Different paths, sometimes similar outputs.
Is general artificial intelligence (AGI) possible?
Open question. Optimists: scaling current approaches could reach AGI. Skeptics: fundamental architectural changes needed, consciousness/understanding may be required. Timeline estimates vary wildly (never to 10 years). Consensus: current AI not on verge of AGI, narrow intelligence only.
Why is augmentation more realistic than replacement?
Complementary strengths: AI handles scale/speed, humans provide judgment/creativity. Replacement assumes: AI masters human strengths (not there yet), we want fully autonomous systems (often we don’t), and ignores social/ethical considerations. Partnership more powerful than replacement.
How should we think about 'intelligence' when comparing AI and humans?
Avoid single dimension: intelligence is multifaceted (reasoning, creativity, social, emotional, practical). AI has narrow superhuman abilities, lacks general human capabilities. Different architectures solving problems differently. Better question: what’s each good for? Not: who’s smarter?