What Is GraphQL?
GraphQL is a query language for APIs and a server-side runtime for executing those queries, developed at Facebook in 2012 and open-sourced in 2015, that allows clients to request exactly the data they need and nothing more.
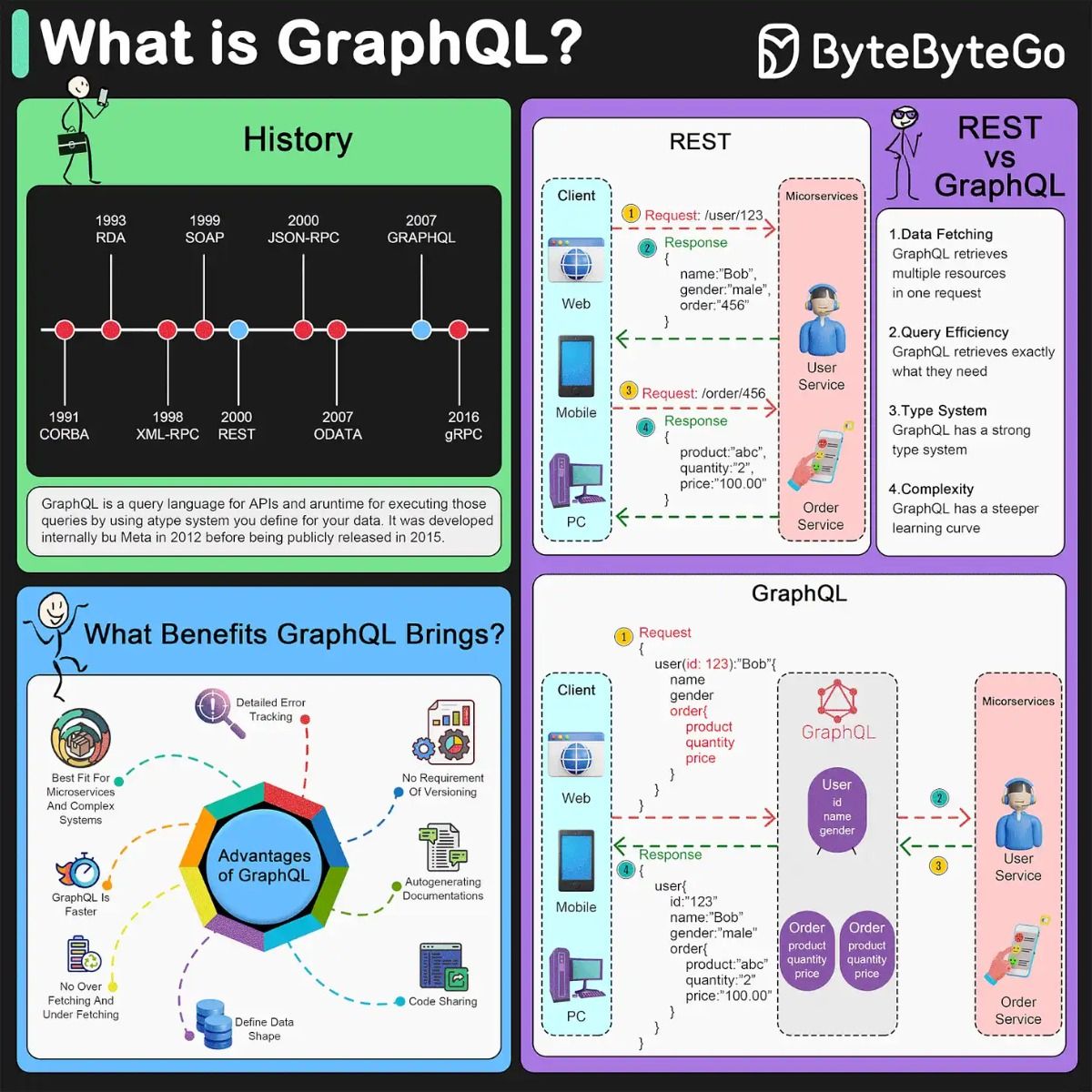
Unlike REST APIs, which expose fixed endpoints that return predetermined data structures, GraphQL exposes a single endpoint through which clients submit typed queries specifying their exact data requirements; the server responds with a JSON object shaped precisely to the query.
This architecture eliminates the over-fetching and under-fetching problems endemic to REST, reduces the number of network round-trips required to assemble complex views, and gives front-end teams independent control over their data requirements without requiring back-end changes.
In 2012, engineers at Facebook were dealing with a problem that had become common at large technology companies: their API was built for desktop browsers, but mobile was growing fast.
The mobile app needed much less data - just a user's name and profile photo - but the existing API returned a full user object with dozens of fields. Every request shipped kilobytes of unnecessary data over slow mobile networks.
At the same time, some features required assembling data from three or four different REST endpoints, meaning the app had to make multiple sequential requests before it could render a screen.
The solution Facebook's team built was GraphQL - a query language for APIs that lets the client specify exactly what it needs, and the server returns exactly that.
In 2015, Facebook open-sourced GraphQL. By 2016, GitHub had migrated its public developer API to GraphQL. Today, it is used at scale at Shopify, Twitter, Airbnb, Netflix, and hundreds of other companies. It has become one of the most consequential shifts in API design in the last decade.
According to the 2023 State of JavaScript survey, GraphQL adoption among JavaScript developers reached approximately 29 percent, up from 20 percent three years earlier.
The annual GraphQL Foundation landscape report (2023) counted over 20,000 open-source projects tagged with GraphQL on GitHub, reflecting an ecosystem that has matured from experimental to mainstream.
For teams building products across mobile, web, and third-party integrations simultaneously, GraphQL has moved from a curiosity to a standard tool in the professional API designer's toolkit.
The Problems GraphQL Solves
To understand what GraphQL does, you first need to understand what REST does wrong - or more precisely, where REST's design creates friction at scale.
Over-Fetching
Over-fetching occurs when an API endpoint returns more data than the client needs.
Consider a REST endpoint for a user profile: GET /users/123
A typical response might include:
{
"id": 123,
"name": "Sarah Chen",
"email": "sarah@example.com",
"bio": "Software engineer...",
"avatar_url": "https://...",
"follower_count": 1402,
"following_count": 387,
"post_count": 89,
"created_at": "2019-03-14",
"location": "San Francisco",
"website": "https://...",
"verified": false,
...
}A mobile app that only needs to display a name and avatar in a list view must still download the entire object.
At scale - millions of users making dozens of requests per session - this is a meaningful performance and bandwidth cost.Netflix's API team documented internal cases where REST responses contained up to 10x more fields than any single client consumed.
On constrained mobile networks common across Asia and Latin America - two of the fastest-growing markets for digital services - this represents both user experience degradation and real monetary cost to users on metered data plans.
Under-Fetching
Under-fetching occurs when a single endpoint doesn't return enough data, requiring multiple requests to assemble what the client needs.
Building a social media feed might require:
GET /feed- returns a list of post IDsGET /posts/456- get the post contentGET /users/123- get the post author's name and avatarGET /posts/456/comments?limit=3- get preview commentsFour round trips, each with its own network latency, before the feed can render. On a fast desktop connection, this is inconvenient. On a slow mobile network or poor cellular signal, it is the difference between a good and a terrible user experience.
Researchers at Akamai (2017) found that a 100-millisecond delay in website load time can reduce conversion rates by 7 percent. For e-commerce and content platforms, the cascading latency of multiple REST round trips is not just a technical inconvenience - it has measurable revenue implications.
The N+1 Problem
A specific variant of under-fetching is the N+1 problem: to display a list of N posts with their authors, you make 1 request for the posts, then N additional requests for each author. If you're displaying 20 posts, that's 21 API calls for one screen.
GraphQL is designed to eliminate all three of these problems through a fundamentally different approach to data fetching.
How GraphQL Works
GraphQL exposes a single endpoint - typically something like
/graphql- that accepts queries written in the GraphQL query language. The client specifies exactly what fields it wants, and the server returns exactly those fields, nothing more.Queries
A GraphQL query for a user profile, asking for only name and avatar, looks like this:
query { user(id: "123") { name avatarUrl } }The server response:
{ "data": { "user": { "name": "Sarah Chen", "avatarUrl": "https://..." } } }Only the requested fields are returned. The same endpoint can serve a desktop app that needs more fields:
query { user(id: "123") { name email bio followerCount postCount location } }Both clients use the same endpoint, the same server code, and the same schema - they simply ask for different data.
Nested Queries: Solving the N+1 Problem
GraphQL allows you to request related data in a single query:
query { feed { posts { id content createdAt author { name avatarUrl } comments(limit: 3) { text author { name } } } } }What would have required 20+ REST requests now requires one GraphQL query.
The server resolves all the nested relationships internally and returns a single response.Mutations
While queries read data, mutations write it. A mutation to create a new post:
mutation { createPost(input: { content: "GraphQL changed how I think about APIs" tags: ["graphql", "api-design"] }) { id content createdAt } }The mutation response includes the newly created post's data - the fields the client requested - so the client doesn't need a subsequent read operation to get the created object's ID.
Subscriptions
Subscriptions enable real-time updates. A client subscribes to an event and receives data pushed from the server when that event occurs:
subscription { newComment(postId: "789") { text author { name avatarUrl } createdAt } }The server sends data to the client each time a new comment is posted to that post. Subscriptions are typically implemented over WebSockets.
The Schema: GraphQL's Type System
One of GraphQL's most powerful features is its strongly typed schema. The schema defines every type of data the API can return and every operation it supports. It acts as a contract between client and server and as self-documenting API documentation.
A simplified schema for a blogging platform:
type User { id: ID! name: String! email: String! posts: [Post!]! } type Post { id: ID! title: String! content: String! author: User! comments: [Comment!]! createdAt: String! } type Comment { id: ID! text: String! author: User! } type Query { user(id: ID!): User post(id: ID!): Post feed: [Post!]! } type Mutation { createPost(input: CreatePostInput!): Post! }The
!denotes non-nullable fields.The schema is introspectable - tools like GraphiQL and Apollo Studio let developers explore the schema interactively, see what queries are possible, and test them without reading documentation.The introspection capability is particularly valuable for teams with many developers. When a frontend engineer wants to know what fields are available on the
Usertype, they can query the schema itself rather than reading documentation that may be stale.Lee Byron, one of GraphQL's co-creators at Facebook, described this as treating the API as a "living document" - the schema is always authoritative because the server itself can be queried for its own capabilities (Byron, 2015).
GraphQL vs. REST: A Direct Comparison
| Dimension | REST | GraphQL |
|---|---|---|
| Endpoints | Multiple (one per resource) | Single endpoint |
| Data shape | Server-defined | Client-defined |
| Over-fetching | Common | Eliminated |
| Under-fetching | Common | Eliminated |
| Versioning | URL versioning (/v1/, /v2/) | Schema evolution without versioning |
| Caching | HTTP caching works natively | Requires custom caching (Apollo, etc.) |
| Error handling | HTTP status codes | Application-level errors in response |
| Tooling maturity | Very mature | Rapidly maturing |
| Learning curve | Low | Moderate |
| File uploads | Native | Requires workarounds |
| Real-time | Requires SSE or WebSockets manually | Subscriptions built into spec |
| Type safety | Optional (OpenAPI/Swagger) | Built into spec |
| Schema documentation | External (Swagger, Postman) | Introspectable from the API itself |
Where REST Wins
REST is not being replaced by GraphQL across the board. REST genuinely works better in several situations:
Simple CRUD APIs: If your API is straightforward create-read-update-delete operations and your clients are all similar, REST's simplicity is an advantage. GraphQL's flexibility is most valuable when you have heterogeneous clients with divergent needs.
HTTP caching: REST responses can be cached at the network level using HTTP cache headers, CDNs, and browser caches. This is extremely valuable for read-heavy APIs with large audiences.
GraphQL queries are typically POST requests (the body varies per query), which standard HTTP caches can't cache. You can work around this with persisted queries and GET requests, but it adds complexity.
Public APIs for unknown consumers: When you're building a public API and don't know who will use it or how, REST's simplicity and familiarity lower the adoption barrier. Many developers already understand REST; GraphQL requires learning the query language and tooling.
File uploads and binary data: GraphQL handles text data well but wasn't designed for file uploads or binary streams. These require multipart form data extensions that add complexity.
Team familiarity: REST has been the dominant API paradigm for 20 years. Most developers have deep REST experience; GraphQL expertise is less universal.
Where GraphQL Wins
Multiple client types: A mobile app, web app, and third-party integration that all need the same data in different shapes benefit enormously from GraphQL's flexibility. One API serves all clients without multiple versions or field proliferation.
Rapid front-end iteration: Front-end teams can add fields to their queries without coordinating with back-end engineers to modify endpoint responses. This reduces cross-team coordination overhead significantly.
API aggregation: GraphQL is excellent for building a unified API layer on top of multiple backend services. Clients query a single GraphQL API; the GraphQL server fetches data from microservices, databases, and third-party APIs and composes the response.
Developer experience: The introspectable schema, in-browser IDE tools, and type safety create a development experience that REST, with its often-inconsistent documentation, rarely matches.
Reducing mobile data usage: For mobile apps where bandwidth and battery matter, requesting only needed fields reduces both. GitHub reported significant payload reductions after switching to GraphQL.
How GraphQL Is Used at Scale
GitHub
GitHub launched its GraphQL API (v4) in 2016, making it the highest-profile early adopter outside Facebook. GitHub's stated reasons: REST's fixed endpoints made it hard to serve the diverse needs of its developer community; too many endpoints returned far more data than clients needed; adding new fields required versioning.
Kyle Daigle, then GitHub's director of ecosystem engineering, noted in the 2016 launch announcement that the GraphQL API returned "just the data you request, which is great for the varying needs of mobile clients." GitHub's GraphQL API covers repositories, pull requests, issues, commits, and virtually every other GitHub entity.
Third-party tools that integrate with GitHub can now request precisely the data they need - a significant improvement for IDE integrations and CI/CD tooling that only need narrow slices of GitHub's data model.
Shopify
Shopify uses GraphQL as its primary API for both the Storefront API (used by themes and headless commerce frontends) and the Admin API (used by app developers).
Shopify serves millions of merchant stores and as many third-party app integrations; serving them all through REST would have required proliferating endpoints or sending massive over-fetched responses to mobile-first storefronts.
By 2022, Shopify's GraphQL Admin API had become the recommended path for new app development, with the company investing documentation and tooling resources proportionately. The company cited query flexibility and schema-driven development as central reasons for the shift.
Meta
Facebook and Instagram continue to use GraphQL internally at a scale no other organization approaches. Facebook's mobile app has used GraphQL since 2012; the query language was refined over three years of internal use before being published.
Meta's experience demonstrates GraphQL's viability at extreme scale - billions of queries per day.
Nick Schrock, another co-creator of GraphQL at Facebook, described the internal development process as solving "real problems at massive scale before we ever wrote a specification" (Schrock, 2015).
This production-first lineage distinguishes GraphQL from many API standards that were designed theoretically and only later tested against production complexity.
Twitter / X
Twitter adopted GraphQL for portions of its API during its major architecture rebuilds between 2020 and 2023.
The platform's "Twitter API v2" documentation explicitly described efforts to reduce over-fetching from its legacy REST endpoints - a problem particularly visible to researchers and data consumers who were downloading entire tweet objects to extract a single field.
Common Misconceptions About GraphQL
"GraphQL is always faster than REST." Not necessarily. GraphQL's resolver architecture can introduce N+1 problems on the server side if not carefully implemented with data loader patterns. The client-side performance benefits are real, but server-side efficiency requires attention.
"GraphQL replaces REST completely." No. REST remains the better choice for many use cases. Most modern systems mix both: a public REST API for simplicity, GraphQL for internal consumption or mobile clients.
"GraphQL is only for React applications." GraphQL can be used from any language or framework. There are mature GraphQL client libraries for Python, Ruby, Java, Go, Swift, Kotlin, and virtually every other language. It is not tied to the JavaScript ecosystem.
"GraphQL has no versioning problems." GraphQL does reduce the need for major version bumps by allowing schema evolution (adding fields without breaking existing queries). But removing fields or changing types still requires deprecation strategies and coordination.
"GraphQL is always more complex to implement." For simple use cases, this is true - REST is faster to start. But for complex, multi-client scenarios, GraphQL typically reduces long-term complexity even if the initial learning curve is steeper.
A 2022 developer survey by Postman found that among teams with three or more client types consuming the same API, satisfaction rates with GraphQL were 34 percent higher than with REST.
Getting Started with GraphQL
For those evaluating whether to adopt GraphQL, a practical starting point:
Identify your pain points: Are multiple client types consuming your API with different data needs? Are you making many round trips? Is over-fetching hurting mobile performance? If yes to any of these, GraphQL may help.
Start with one service: Rather than migrating an entire REST API, introduce GraphQL for one domain (e.g., a user profile service or a product catalog) and observe the developer experience improvement.
Use established tooling: Apollo Server (Node.js), Strawberry or Ariadne (Python), graphql-ruby (Rails), and gqlgen (Go) are mature, well-documented implementations.
Implement DataLoader from the start: The N+1 problem on the server side is real. Facebook's DataLoader pattern - batching and caching resolver calls - should be implemented as a foundational pattern, not retrofitted later.
Consider GraphQL Federation for microservices: If you have multiple services, Apollo Federation allows multiple teams to build and deploy their own GraphQL schemas that are composed into a single unified API. This is how large organizations (including Airbnb and Netflix) use GraphQL across teams.
GraphQL is not a universal solution to API design challenges, but for the problems it was designed to solve - flexible client-driven queries, elimination of over and under-fetching, unified API layers across diverse clients - it is genuinely excellent. Understanding when it helps and when it doesn't is the skill that matters most.
GraphQL Performance Considerations
"GraphQL is not a replacement for REST. It is a different tool with a different design center. REST is optimized for simplicity and cacheability. GraphQL is optimized for client flexibility and developer experience at the cost of more complex server-side work." - Lee Byron, one of GraphQL's original creators
Performance in GraphQL is more nuanced than REST because the flexibility that makes it powerful also creates new server-side challenges.
The N+1 problem (server-side): When resolving a list of posts and their authors, a naive GraphQL implementation issues one database query for the posts and then N separate queries for each author - the N+1 pattern. For a page of 20 posts, that's 21 database queries.
The standard solution is DataLoader, which batches all author lookups from a single resolver execution into a single database query using a collect-and-batch pattern.
Query depth and complexity: Because clients can request arbitrarily nested data, a malicious or naive client could construct a deeply nested query that creates massive server load. Production GraphQL APIs typically implement:
- Depth limiting: Rejecting queries nested deeper than a threshold (e.g., 7 levels)
- Complexity scoring: Assigning cost scores to fields and rejecting queries that exceed a complexity budget
- Query whitelisting (persisted queries): Only allowing pre-approved query shapes, which also enables caching
Caching strategy: Unlike REST, where a GET /posts/123 response can be cached by URL, GraphQL's single endpoint and variable query bodies require custom caching. Common approaches:
- Response caching: Cache the full query response keyed by query + variables hash (Apollo's default)
- Normalized caching: Cache individual objects by ID and reconstruct responses from the cache (Apollo Client's default on the frontend)
- Persisted queries with CDN caching: Convert POST queries to GET requests with a pre-registered query ID, enabling CDN caching
The caching complexity is a real cost. For APIs where caching is critical to performance (high-traffic read-heavy APIs), REST's native HTTP caching remains a significant advantage.
GraphQL Federation: Scaling Across Teams
One of the most significant recent developments in the GraphQL ecosystem is Federation - a model for composing multiple GraphQL schemas, each owned by a separate team, into a single unified API that clients interact with as though it were a monolith.
Apollo Federation, introduced in 2019, addresses one of GraphQL's most challenging scaling problems: how do large organizations with many independent teams (each responsible for different data domains) collaborate on a single coherent API?
In a federated architecture, each team defines and deploys their own subgraph - a self-contained GraphQL schema covering their domain (users, products, orders, reviews). A central gateway or router composes these subgraphs into a single unified schema.
A client query that spans multiple domains is automatically decomposed by the router, dispatched to the appropriate subgraphs, and the responses assembled into a single coherent response.
Netflix's API team described using a federated GraphQL architecture to coordinate data from over 400 internal microservices into a single developer-facing API. Rather than requiring a central platform team to integrate every microservice into one monolithic schema, each service team owns their subgraph.
The result is organizational scalability: teams can evolve their subgraphs independently without coordinating through a centralized API team.
GraphQL Subscriptions and Real-Time Architecture
GraphQL subscriptions are the real-time component of the specification, allowing clients to receive data pushed from the server when specific events occur. The client subscribes to a defined event type and the server streams updates over a persistent connection, typically WebSocket.
A subscription for live comment feeds:
subscription {
commentAdded(postId: "789") {
id
text
author {
name
avatarUrl
}
}
}The server maintains the connection and pushes data whenever a new comment is added to that post. The client receives the data in the same shape as a regular GraphQL response.
Subscriptions add significant infrastructure complexity: they require stateful server connections (unlike REST or GraphQL query/mutations which are stateless), which means load balancers must handle WebSocket sessions consistently, and horizontal scaling requires a pub/sub layer (Redis is commonly used) to route events to the correct server instance.
For many real-time use cases, simpler alternatives (Server-Sent Events for one-way streaming, polling, or webhook callbacks) may achieve the same result with less architectural complexity.
GraphQL subscriptions are most appropriate when the WebSocket connection is already required for other reasons, or when the consistent GraphQL developer experience across queries, mutations, and subscriptions is worth the infrastructure cost.
The GraphQL Ecosystem in 2024 and Beyond
The GraphQL ecosystem has matured considerably from its 2015 open-source release. The GraphQL Foundation, hosted by the Linux Foundation since 2018, now stewards the specification, with member organizations including Meta, Google, Amazon, IBM, Microsoft, and Shopify contributing to the governance process.
This institutional backing has ensured that GraphQL's development is not controlled by a single company - a concern that arose early given Facebook's origin role.
Key ecosystem developments shaping the landscape:
GraphQL over HTTP: A formal specification (finalized 2023) standardizing how GraphQL should behave over HTTP, addressing ambiguities in the original specification that had led to inconsistent implementations.
Incremental delivery (@defer and @stream): Experimental directives allowing large query results to be streamed progressively - a significant performance improvement for queries that mix fast-returning data with slow-returning data.
Rather than waiting for the slowest resolver before sending anything, the server can stream partial results as they become available.
Schema Registry patterns: As GraphQL adoption scales, organizations have built schema registry services (similar to container registries) that track schema versions, validate proposed changes for backward compatibility, and provide a single source of truth for the composed API surface.
For teams beginning GraphQL adoption in 2024, the ecosystem is mature enough that the tooling risk is low.
The primary question is no longer "is GraphQL production-ready?" but "does GraphQL match my specific use case better than REST?" For most teams with heterogeneous clients and complex data relationships, the answer remains yes.
Frequently Asked Questions
What is GraphQL?
GraphQL is a query language for APIs and a runtime for executing those queries, developed by Facebook in 2012 and open-sourced in 2015. Unlike REST, which exposes fixed endpoints that return predetermined data shapes, GraphQL allows clients to specify exactly what data they need in a single request. The server returns precisely that data, no more, no less. GraphQL also provides a strongly typed schema that documents what data and operations are available.
What problem does GraphQL solve?
GraphQL primarily solves two problems that plague REST APIs: over-fetching and under-fetching. Over-fetching means receiving more data than the client needs (a mobile app requesting a full user object when it only needs a name and photo). Under-fetching means a single endpoint doesn’t return enough data, requiring multiple round trips to different endpoints to assemble what’s needed. GraphQL lets clients request exactly what they need in a single query, solving both problems simultaneously.
How does GraphQL differ from REST?
REST APIs use multiple URL endpoints, each representing a resource (e.g., /users, /posts, /comments). GraphQL exposes a single endpoint and uses a query language to specify what data to retrieve. REST responses are shaped by the server; GraphQL responses are shaped by the client. REST relies on HTTP verbs (GET, POST, PUT, DELETE) to indicate operations; GraphQL uses three operation types: queries (read), mutations (write), and subscriptions (real-time). REST is stateless and cacheable by default; GraphQL requires additional tooling for caching.
Who uses GraphQL in production?
GraphQL was created and is used at scale by Meta (Facebook and Instagram). GitHub migrated its public API to GraphQL in 2016, citing the need to support diverse client requirements with a single flexible API. Shopify uses GraphQL for its storefront and admin APIs. Twitter, Airbnb, Netflix, and many other large technology companies have adopted GraphQL for internal or public APIs. Its adoption has grown particularly strongly in companies with multiple client types (web, mobile, third-party integrations) that need to consume the same data in different shapes.
When should you use GraphQL instead of REST?
GraphQL is most valuable when you have multiple client types with different data needs (mobile apps needing minimal data, web apps needing more), when you need to aggregate data from multiple underlying services in a single request, or when clients require significant flexibility in what they retrieve. REST is often preferable for simple CRUD operations, when HTTP caching is critical, when your team has more REST expertise, or when you’re building a public API consumed by developers who prefer REST’s simplicity and tooling familiarity.