Learning: On March 9, 2016, Lee Sedol, one of the greatest Go players alive, sat down across a board from a screen displaying moves made by a computer program. Go is a board game of ancient Chinese origin that has roughly 10^170 possible board positions, a number that dwarfs the number of atoms in the observable universe.
For decades, AI researchers considered Go effectively unsolvable by machine because the game's complexity made brute-force search, the method that had worked for chess, computationally impossible.
The conventional wisdom was that mastering Go required deep intuition and a kind of holistic pattern recognition that machines could not replicate.
AlphaGo, developed by DeepMind, won the match four games to one. It was not playing by a script. It had learned to play Go by training on hundreds of thousands of human games and then playing millions of games against itself.
The moves it made in the match, including Move 37 in Game 2, a placement on the fifth line that professional commentators described as something no human player would have chosen, emerged from the learned representations in its deep neural network, not from any rule a human had written.
That moment illustrated something important about deep learning: at sufficient scale and with sufficient data, hierarchical learning in neural networks can discover non-obvious patterns that human experts did not know to look for.
What Makes It "Deep"
The word "deep" in deep learning refers to depth in the architectural sense: the number of layers in a neural network between the input and the output.
An early neural network with one or two hidden layers is "shallow." A modern deep learning model might have dozens, hundreds, or in the case of the latest large language models, effectively thousands of processing layers.
"The key insight of deep learning is that good features are not hand-designed. They are learned from data using a general-purpose learning procedure.", Yoshua Bengio
This distinction matters because depth fundamentally changes what a network can represent. A shallow network can, in theory, approximate any function given enough neurons in a single layer, a result known as the universal approximation theorem.
But approximating complex functions with a single layer requires an impractically large number of neurons. Multiple layers allow the same expressive power with exponentially fewer parameters, and more importantly, they allow the network to learn hierarchical representations.
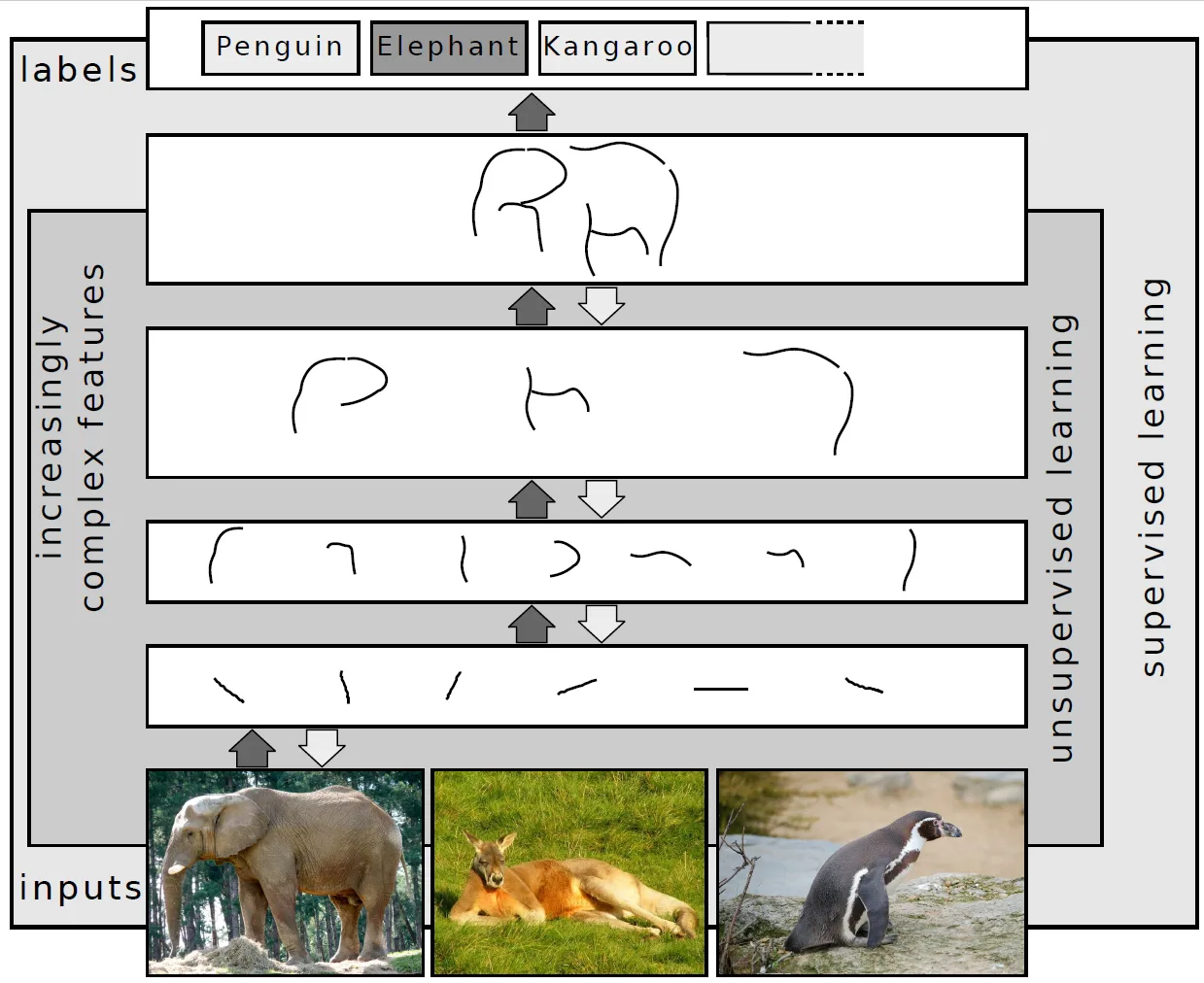
Hierarchical representation is the core insight of deep learning. Consider how you recognize a face. You do not process raw pixels directly as a face.
Your visual system first detects edges, then combines edges into curves and lines, then assembles lines into features like eyes and noses, then combines features into face-level recognition. Each stage of abstraction builds on the previous stage.
Deep neural networks replicate this hierarchy computationally.
In an image recognition network, early layers learn to detect simple features: oriented edges, color gradients, corners. Middle layers combine those simple features into more complex ones: eyes, wheels, leaves, fur textures.
Deep layers represent high-level semantic concepts: the distinction between a golden retriever and a Labrador, between a genuine smile and a polite one, between a tumor and benign tissue.
This automatic learning of hierarchical features from raw data, without any human specifying what the intermediate representations should be, is what makes deep learning qualitatively different from earlier machine learning approaches.
How It Differs From Traditional Machine Learning
To appreciate what deep learning contributes, it is useful to understand what the field looked like before it.
"Deep learning allows computational models composed of multiple processing layers to learn representations of data with multiple levels of abstraction.
These methods have dramatically improved the state-of-the-art in speech recognition, visual object recognition, object detection and many other domains.", Geoffrey Hinton, Yann LeCun, and Yoshua Bengio, Deep Learning, Nature 2015
Traditional machine learning requires feature engineering: humans who understand the domain must examine the raw data, decide which aspects of it are relevant to the task, and create numerical representations of those aspects.
For fraud detection on financial transactions, a domain expert might create features like "ratio of transaction amount to 30-day average," "number of countries visited in 24 hours," or "time since last transaction." These features encode human knowledge about what distinguishes fraudulent from legitimate behavior.
| Dimension | Traditional Machine Learning | Deep Learning |
|---|---|---|
| Feature Engineering | Required, humans manually design features from raw data | Not required, learned automatically from raw data |
| Data Needs | Can work with thousands of examples | Typically needs hundreds of thousands to millions of examples |
| Interpretability | Often high, features and weights are human-readable | Low, representations are distributed across millions of parameters |
| Best For | Structured tabular data, smaller datasets, regulated decisions | Raw images, audio, text; large-scale unstructured data |
Feature engineering is expensive and requires both domain expertise and machine learning expertise. It also imposes a ceiling on performance: if the engineers did not know to create a feature, the model cannot use the information it would have encoded.
And it does not scale to domains where meaningful features cannot be identified by inspection, like raw pixel values in images or raw audio waveforms.
Deep learning largely eliminates feature engineering for the data types it handles well. You provide raw images, raw audio, or raw text, and the network learns its own internal features through training.
This is why deep learning has had its most dramatic impact in domains like computer vision, speech recognition, and natural language processing, exactly the domains where raw data is abundant but human-specified features are inadequate.
The tradeoff is that deep learning is significantly more demanding of both data and computation. A traditional machine learning model might train effectively on a few thousand carefully featurized examples.
A deep learning model achieving state-of-the-art performance might require millions of examples and days of training on specialized hardware.
The Data and Compute Requirements
Deep learning is famously data-hungry. The intuitive reason is that hierarchical representations can only be learned if the data contains enough information to constrain all the levels of the hierarchy. If you have 1,000 training images of dogs, the network can learn only the crudest representations.
With one million images, it can learn representations fine-grained enough to distinguish breeds and individual animals.
"If we want machines to think, we need to teach them to see.", Fei-Fei Li, on founding ImageNet and why scale of visual data is the key bottleneck for AI progress
ImageNet, the dataset that became the proving ground for deep learning in computer vision, contains roughly 14 million labeled images across 21,000 categories. Building it required years of work and the annotation effort of Amazon Mechanical Turk workers who labeled each image manually.
The dataset was assembled by Fei-Fei Li at Princeton and Stanford, who had the insight that the scale of labeled data was the bottleneck preventing progress in vision AI. AlexNet's 2012 breakthrough was only possible because ImageNet existed.
In language, the data requirements are even larger. GPT-3 was trained on roughly 570 gigabytes of text after filtering, drawn from Common Crawl, books, Wikipedia, and other sources. That corresponds to hundreds of billions of words. GPT-4's training data is not publicly specified but is almost certainly substantially larger.
Compute requirements have grown even faster than data requirements. Training AlexNet took a week on two NVIDIA GTX 580 GPUs. Training GPT-3 was estimated by OpenAI to cost in the range of four to twelve million dollars in cloud compute, using thousands of GPUs.
Training GPT-4 is estimated to have cost over 100 million dollars. The compute used to train state-of-the-art AI models has roughly doubled every 9 months since 2012, a faster scaling rate than Moore's Law applied to hardware.
This compute intensity is both an opportunity and a structural problem. It is an opportunity because the results have proven worth the investment: the largest models have capabilities that smaller models do not.
It is a structural problem because it concentrates AI development in the hands of organizations with sufficient resources to fund these training runs.
The Breakthroughs That Defined an Era
Several specific advances mark the deep learning era as historically distinct from what came before.
ImageNet 2012, and AlexNet's demonstration that deep convolutional networks could achieve dramatically better image recognition than any prior approach, is the conventional starting point.
It validated the hypothesis that depth and scale, combined with GPU training, would pay off in the domain of visual perception. Within three years, convolutional networks had achieved superhuman performance on the benchmark.
Real-time speech recognition became practical through deep learning improvements in acoustic modeling. Google's transition to deep neural networks for speech recognition in 2012 improved word accuracy by roughly 25 percent, enabling the practical speech interfaces that appeared in smartphones shortly after.
The key insight was that raw audio features fed into deep networks outperformed hand-engineered spectral features fed into shallower models.
AlphaGo in 2016, and then AlphaZero in 2017, demonstrated that deep reinforcement learning could master games of extraordinary complexity and do so by learning from self-play rather than from human examples.
AlphaZero's single system mastered chess, shogi, and Go to superhuman level, starting from only the rules of each game, within 24 hours of self-play for each.
Large language models, beginning with GPT-2 in 2019 and accelerating through GPT-3 in 2020 and subsequent models, demonstrated that scaling transformer networks in parameters and training data produced emergent capabilities: the ability to perform tasks the model was never explicitly trained for, including translation, reasoning, and code generation, simply by learning language at sufficient scale.
AlphaFold 2 in 2020 applied deep learning to protein structure prediction and effectively solved a problem that had defeated computational biology for 50 years. The protein folding problem matters because protein structure determines function, and function determines drug target behavior.
AlphaFold's predictions, released as a free database covering virtually all known proteins, have already accelerated drug discovery research at institutions worldwide.
Transfer Learning: The Democratization of Deep Learning
Training a deep learning model from scratch requires enormous resources. For most organizations and individual practitioners, this is not feasible. Transfer learning is the technique that makes deep learning practically accessible.
A pre-trained model, trained on a large general dataset, has already learned rich general-purpose representations. For an image recognition model trained on ImageNet, those representations encode a sophisticated understanding of visual features at multiple levels of abstraction.
For a language model trained on hundreds of billions of words, those representations encode detailed statistical knowledge about language across many domains.
Transfer learning takes these pre-trained representations and fine-tunes them for a specific downstream task, using a much smaller dataset. The pre-trained weights provide an excellent starting point that captures general structure, and fine-tuning adjusts them to the specific requirements of the new task.
This can reduce the data requirement by orders of magnitude: tasks that would require millions of examples from scratch may require only thousands with transfer learning.
The BERT language model, released by Google in 2018, demonstrated transfer learning for language tasks at scale. BERT was pre-trained on 3.3 billion words and achieved state-of-the-art performance on eleven natural language processing benchmarks when fine-tuned on relatively small task-specific datasets.
Its release transformed natural language processing practice: instead of training specialized models for each task, practitioners began fine-tuning BERT variants, which were faster, cheaper, and more accurate.
Hugging Face, a company founded in 2016, has built a platform for sharing and accessing pre-trained models that has become one of the most important resources in applied deep learning. As of 2024, Hugging Face hosts more than 400,000 models that practitioners can download, fine-tune, and deploy.
This has made state-of-the-art deep learning accessible to teams without the resources to train from scratch.
Frameworks: PyTorch and TensorFlow
Two frameworks dominate practical deep learning work, and understanding their difference clarifies both the history of the field and how practitioners actually work.
TensorFlow was released by Google in 2015. It uses a static computation graph: you define the network architecture as a graph before training begins, compile the graph, and then execute training.
This approach is efficient and well-suited to production deployment because the compiled graph can be optimized and deployed on various hardware targets.
TensorFlow's production ecosystem, including TensorFlow Serving for model deployment, TensorFlow Lite for mobile devices, and TensorFlow Extended for full ML pipelines, is mature and widely used in industrial applications.
PyTorch was released by Meta in 2016. It uses a dynamic computation graph: the network is defined as ordinary Python code, and the graph is constructed during each forward pass. This makes debugging natural: you can use standard Python debugging tools, insert print statements anywhere, and inspect intermediate values directly.
The flexibility made PyTorch much more popular for research, where rapidly iterating on new architectures is essential. By 2019, PyTorch had overtaken TensorFlow in research paper usage, and it currently dominates both academic research and, increasingly, production deployment.
The practical choice for most practitioners today is PyTorch. Its interface is more intuitive for new users, its community produces more educational resources, and the gap in production capability has narrowed substantially with the maturation of PyTorch's deployment tools.
TensorFlow remains the choice at organizations with large existing TensorFlow investments and specific deployment requirements that TensorFlow's production tools address.
Hardware: GPUs and TPUs
The deep learning revolution was as much a hardware story as an algorithmic one. The computations that drive deep learning, primarily matrix multiplications, are parallelizable in ways that map perfectly to GPU architecture.
GPUs were designed to render graphics by performing many simple computations in parallel. A modern GPU has thousands of small processing cores operating simultaneously. The matrix multiplications that dominate neural network training can be distributed across these cores, making training orders of magnitude faster than on a CPU.
NVIDIA recognized this opportunity and invested in CUDA, a programming platform for GPU computation, which became the infrastructure on which the deep learning ecosystem was built.
NVIDIA's GPUs, particularly the A100 and H100 series, have become the standard hardware for deep learning training. A single H100 GPU costs over 30,000 dollars, and large model training runs use thousands of them simultaneously.
Google developed Tensor Processing Units, TPUs, as custom silicon specifically optimized for the matrix operations in neural network training. TPUs offer higher throughput and energy efficiency than GPUs for large-scale training jobs.
Google uses TPUs extensively internally and makes them available through Google Cloud. AlphaGo, BERT, and Google's internal large language models were all trained on TPUs.
The hardware bottleneck is real and consequential. The organizations training the most capable models are those with the largest GPU and TPU fleets. AWS, Google Cloud, and Microsoft Azure have invested billions in building data centers with dense GPU deployments specifically to serve this demand.
The environmental cost of this infrastructure is significant: training a single large language model can produce as much carbon as five American cars over their lifetimes, according to a 2019 study by Emma Strubell and colleagues at the University of Massachusetts.
"Generative adversarial networks is the most interesting idea in the last ten years in machine learning.", Ian Goodfellow, inventor of GANs, on the technique he developed in 2014 that enabled a new era of AI-generated content
Limitations: Where Deep Learning Falls Short
The impressive capabilities of deep learning systems are real, and so are their limitations. Understanding both is essential for anyone building or deploying systems that use these methods.
Interpretability remains a fundamental problem. When a neural network makes a prediction, tracing the cause through millions of weights is not practically feasible. This is not merely an inconvenience. In medicine, a clinician needs to understand why an AI flags something suspicious to integrate it with clinical judgment.
In credit decisions, fairness and regulatory requirements may demand explanations. In safety-critical systems, engineers need confidence that the network's reasoning is sound, not just that it performed well on a test set.
Data hunger limits applicability in domains where labeled data is expensive or scarce. Medical imaging systems require expert annotation by physicians, which is costly and slow to accumulate. Rare events by definition provide few training examples.
Legal texts, scientific papers in specialized fields, and many industrial sensor datasets do not have the scale that deep learning systems need to perform reliably.
Brittleness to distribution shift is perhaps the most practically consequential limitation. A deep learning system trained on data from one distribution will degrade when deployed in a different distribution. Self-driving systems trained and tested in California encounter difficulties in Michigan winters.
Medical diagnosis systems trained on data from one hospital may underperform at another hospital with different imaging equipment and patient demographics. The system does not know when it has drifted out of its training distribution and cannot reliably signal its own uncertainty.
Adversarial vulnerability, demonstrated by the panda-gibbon example in the neural network literature, extends to language and other modalities. Language models can be manipulated through carefully constructed inputs to bypass safety guidelines or produce incorrect outputs.
This vulnerability is not yet fully understood and has no complete solution.
Where Deep Learning Is Heading
The trajectory of deep learning from 2012 to the present has involved consistent scaling: more layers, more parameters, more data, more compute, with consistent capability improvements. There is active debate about how long this scaling trajectory can continue and what comes after.
Multimodal models that integrate vision, language, audio, and other modalities simultaneously are a significant current frontier. GPT-4 with vision, Google's Gemini, and Anthropic's Claude models can all process images alongside text. Future systems will likely extend this to audio and video in tighter integration.
Efficiency improvements are making capable deep learning systems smaller and cheaper to deploy. Techniques like quantization, pruning, and knowledge distillation reduce model size and inference cost while retaining most capability.
This is driving deployment of capable AI on edge devices: smartphones, vehicles, and industrial equipment, rather than requiring cloud connectivity.
Reasoning capabilities remain a significant area of active research. Current large language models can exhibit impressive reasoning-like behavior but fail systematically on problems that require robust logical or mathematical reasoning.
Whether improvements to architecture, training, or new techniques like chain-of-thought prompting will close this gap, or whether fundamentally different approaches are needed, is an open question.
Practical Takeaways
For practitioners evaluating whether to use deep learning for a specific problem, the decision criteria are clear.
Deep learning is the right choice when you have large amounts of labeled data, when the input is raw and unstructured, particularly images, audio, or text, and when you have access to the compute resources needed for training or can leverage pre-trained models through transfer learning.
Deep learning is probably not the right choice when your dataset is small and labeled, when you need to explain individual predictions to regulators or users, or when you need high reliability in environments that may differ significantly from your training data.
For anyone seeking to understand the field technically, the most important concepts to master are the basics of neural networks, backpropagation, and gradient descent, followed by the specific architectural innovations of convolutional networks for vision and transformers for language.
These two architectures account for the vast majority of deep learning applications currently deployed in production.
The field is advancing quickly, but the foundational principles have proven durable. Gradient descent, learned representations, and hierarchical abstraction have remained central from AlexNet in 2012 through the largest language models of 2025.
Whatever architectural innovations emerge in the coming years will almost certainly build on these foundations rather than replace them.
What Research Shows About Deep Learning Capabilities and Limits
The academic literature on deep learning has accumulated substantial empirical findings about where the approach succeeds, where it fails, and why - findings that are essential context for anyone deploying these systems.
Geoffrey Hinton, Yann LeCun, and Yoshua Bengio - who shared the 2018 Turing Award for their foundational contributions to deep learning - published a landmark survey in Nature in 2015 titled "Deep Learning" that synthesized the theoretical basis for why hierarchical representation learning outperforms hand-engineered features on high-dimensional perceptual data.
The paper documented that deep convolutional networks trained on ImageNet (1.4 million labeled images) had reduced image classification error from 26 percent (the best non-deep-learning result in 2011) to 3.5 percent (achieved by 2015) - a reduction achieved through architectural depth, training on large datasets, and GPU computing.
LeCun's convolutional network architecture, developed at AT&T Bell Labs in the late 1980s, had been computationally intractable for large images until GPU training made it feasible.
The 2015 survey paper, which has been cited over 80,000 times as of 2024, established the theoretical framework - hierarchical feature learning, gradient descent optimization, and transfer learning - that subsequent deep learning research has built upon.
Hinton's subsequent resignation from Google in 2023 and his public statements about AI risk represented a significant shift: the researcher most responsible for practical deep learning becoming the field's most prominent internal critic of unconstrained development.
Emma Strubell, Ananya Ganesh, and Andrew McCallum at the University of Massachusetts Amherst published "Energy and Policy Considerations for Deep Learning in NLP" (ACL 2019), the first systematic study of the energy costs of training large language models.
Their analysis found that training a single large transformer model with neural architecture search consumed approximately 626,155 pounds of CO2 equivalent - comparable to the lifetime emissions of five American automobiles.
Training BERT (without architecture search) consumed approximately 1,507 pounds of CO2, and fine-tuning BERT on a downstream task consumed roughly 35 pounds of CO2. The Strubell paper provoked significant attention because it made visible the environmental cost that AI research had largely ignored.
Subsequent analyses by Patterson et al. at Google (2021) and Lannelongue et al.
at the European Bioinformatics Institute (2023) refined these estimates and found that the carbon cost varies by a factor of 10-80 depending on where training is conducted, because the carbon intensity of electricity grids varies dramatically by location and energy mix.
Data centers in regions powered by renewable energy (Pacific Northwest, Scandinavia) produce dramatically lower carbon emissions per training run than data centers in regions with coal-dominated grids.
Alexey Dosovitskiy and colleagues at Google Brain published "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" (ICLR 2021), demonstrating that the Transformer architecture developed for language tasks could match or exceed convolutional networks for image classification when trained on sufficiently large datasets.
The Vision Transformer (ViT) achieved 88.55 percent accuracy on ImageNet when pre-trained on Google's internal JFT-300M dataset (300 million labeled images), compared to 87.1 percent for the best contemporary convolutional networks trained on comparable data.
The ViT result was significant because it suggested that the specialized architectural inductive biases of convolutional networks (local connectivity, translation equivariance) are not necessary for strong vision performance if sufficient training data is available - a finding that subsequently led to the Swin Transformer and other architectures that have largely supplanted convolutional networks for high-accuracy image tasks.
Dosovitskiy's result also demonstrated the general applicability of the attention mechanism: the same architectural principle that enables language models to capture long-range dependencies in text also captures spatial dependencies in images.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun at Microsoft Research Asia published "Deep Residual Learning for Image Recognition" (CVPR 2016), introducing residual connections (skip connections that add a layer's input directly to its output).
The residual connection solved the degradation problem: simply adding more layers to a deep network was found to degrade performance, contradicting the theoretical expectation that more capacity should never hurt.
He et al. demonstrated that a 152-layer ResNet outperformed a 34-layer network on ImageNet classification, while training reliably through standard gradient descent - which had previously been impossible for networks of that depth.
The ResNet architecture won the ILSVRC 2015 competition with a top-5 error rate of 3.57 percent, surpassing human performance (estimated at 5 percent).
Residual connections are now a standard component of virtually all deep learning architectures, including Transformers, where they appear in every encoder and decoder layer. The paper has been cited over 250,000 times as of 2024, making it the most cited paper in computer vision research.
Real-World Case Studies in Deep Learning Deployment
AlexNet and the ImageNet Moment: The Shift in Computer Vision. The 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is considered the pivotal moment in the deep learning era.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton at the University of Toronto submitted AlexNet, a deep convolutional network with 60 million parameters trained on two NVIDIA GTX 580 GPUs over five days.
AlexNet achieved a top-5 error rate of 15.3 percent, compared to 26.2 percent for the second-best entry - a gap of almost 11 percentage points, far exceeding typical year-over-year progress on the benchmark.
The victory demonstrated that deep learning, GPU training, and large labeled datasets (ImageNet's 1.2 million training images) could produce qualitatively better image recognition than any prior approach.
Within three years, every top entry in ILSVRC used deep convolutional networks, and the challenge's top-5 error rate fell to 3.57 percent - below human performance. The academic impact was immediate: ArXiv submissions on deep learning increased 400 percent between 2012 and 2014.
The commercial impact followed within years: deep learning-based computer vision entered consumer products (Google Photos, Facebook face recognition, Apple's Face ID) and industrial applications (medical imaging, autonomous vehicle perception, manufacturing quality control).
DeepMind AlphaGo and AlphaZero: Deep Reinforcement Learning Validated. DeepMind's AlphaGo, described in a 2016 Nature paper by David Silver and colleagues, combined deep convolutional networks (for board position evaluation) with Monte Carlo tree search to defeat Lee Sedol, a 9-dan professional Go player, four games to one in March 2016.
The match was broadcast live across Asia to an estimated 200 million viewers and established deep learning's capacity to master tasks previously thought to require human-specific intuition.
AlphaGo was trained on 160,000 games from the KGS Go server and then refined through self-play reinforcement learning using approximately 1,202 TPU cores.
AlphaGo Zero (2017) trained exclusively through self-play without any human game data, starting from random play, and surpassed the version that defeated Lee Sedol after 40 days of training.
AlphaZero (2017) generalized the approach, mastering chess, shogi, and Go simultaneously from their rules alone, achieving superhuman performance in each game within 24 hours of self-play training per game.
The AlphaZero chess player was evaluated by former World Chess Champion Garry Kasparov, who described its play as demonstrating "a game with a very high aesthetic quality" involving positional sacrifices and strategic planning patterns that human grandmasters had not discovered.
DeepMind's David Silver led both projects and described the key finding: "Perfect information two-player zero-sum games are now a solved problem for AI."
Google Brain Word2Vec: Deep Learning Changes Natural Language Processing. Tomas Mikolov and colleagues at Google Brain published "Distributed Representations of Words and Phrases and their Compositionality" (NIPS 2013), introducing Word2Vec, a technique that represents words as dense vectors in a continuous space where geometrically close vectors correspond to semantically similar words.
Word2Vec demonstrated the now-famous property that vector arithmetic on word representations captures semantic relationships: the vector for "king" minus "man" plus "woman" produces a vector close to "queen," and "Paris" minus "France" plus "Germany" produces a vector close to "Berlin." Word2Vec vectors were trained on the Google News corpus (approximately 100 billion words) using a shallow neural network predicting words from context.
The representations learned were dramatically more useful for downstream NLP tasks than previous bag-of-words or TF-IDF representations, and Word2Vec adoption transformed NLP practice within a year of publication.
Google subsequently applied word vector representations to improve Google Translate, reducing translation errors by approximately 60 percent on several language pairs where training data was limited, by allowing the model to use semantic similarity between words to generalize from examples to related vocabulary.
Tesla Full Self-Driving: Large-Scale Deep Learning in Safety-Critical Deployment. Tesla's Autopilot and Full Self-Driving (FSD) systems represent the largest deployment of deep learning for safety-critical perception in consumer products, processing sensor data from over 6 million Tesla vehicles globally as of 2024.
Tesla's director of AI Andrej Karpathy (until his 2022 departure) described the system's architecture at Tesla AI Day 2021 and 2022: a neural network processing inputs from eight cameras (providing 360-degree coverage) through a shared multi-scale feature extractor, producing vector space representations of the environment that feed into planning and control modules.
The system is trained on a fleet dataset that grows by approximately 1 million new video clips per day from edge cases and disengagements flagged by the production fleet.
NHTSA's investigation of FSD-related incidents (Special Order for Autopilot and FSD data, 2023) examined approximately 400 collisions involving Autopilot or FSD engaged.
The agency's analysis found that the system's failure rate in specific adverse conditions (low-light intersections, sun glare, temporary traffic controls) was significantly higher than its overall performance statistics suggested - an example of the distribution shift problem at scale, where rare conditions that are underrepresented in training data account for a disproportionate share of safety-critical failures.
Tesla's data-driven fleet learning approach, while producing rapid improvement in common conditions, faces fundamental challenges in improving rare failure modes where even a large fleet generates limited training examples.
Sources & Further Reading
- LeCun, Yann, Bengio, Yoshua, and Hinton, Geoffrey. "Deep Learning." Nature, 521(7553), 436-444, 2015. DOI: 10.1038/nature14539
- Krizhevsky, Alex, Sutskever, Ilya, and Hinton, Geoffrey. "ImageNet Classification with Deep Convolutional Neural Networks." NeurIPS, 2012. View source
- He, Kaiming et al. "Deep Residual Learning for Image Recognition." CVPR, 2016. View source
- Silver, David et al. "Mastering the game of Go with deep neural networks and tree search." Nature, 529, 484-489, 2016. DOI: 10.1038/nature16961
- Silver, David et al. "Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm." arXiv, 2017. View source
- Vaswani, Ashish et al. "Attention Is All You Need." NeurIPS, 2017. View source
- Dosovitskiy, Alexey et al. "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale." ICLR, 2021. View source
- Strubell, Emma, Ganesh, Ananya, and McCallum, Andrew. "Energy and Policy Considerations for Deep Learning in NLP." ACL, 2019. View source
- Mikolov, Tomas et al. "Distributed Representations of Words and Phrases and their Compositionality." NIPS, 2013. View source
- Devlin, Jacob et al. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." NAACL, 2019. View source
Frequently Asked Questions
What is deep learning and how is it different from regular machine learning?
Deep learning is a subset of machine learning that uses neural networks with many hidden layers, typically ten to hundreds of layers deep. Regular machine learning often requires human experts to select and engineer the features that the model will learn from, a process called feature engineering. Deep learning skips that step by automatically discovering useful representations of data through its many layers. This makes it especially powerful for raw, unstructured data like images, audio, and text, where meaningful features are not obvious or easy to specify by hand.
Why is it called deep learning?
The word deep refers to the depth of the neural network’s architecture, meaning the number of layers between the input and output. Early neural networks had only one or two hidden layers and were considered shallow. Modern deep learning systems may have dozens, hundreds, or even thousands of layers. Each additional layer allows the network to learn more abstract and complex representations of the data, building from simple features in early layers to sophisticated concepts in deeper layers. This hierarchical feature learning is what gives deep learning its extraordinary capability.
How does deep learning find patterns in data?
Deep learning networks process data through successive layers, with each layer transforming the representation of the data into something slightly more abstract and useful. In an image recognition network, early layers detect edges and colors, middle layers recognize shapes and textures, and deeper layers identify objects and scenes. This hierarchical feature learning happens automatically during training without humans specifying what to look for at each layer. The result is a system that can identify subtle patterns in raw data that would be invisible to a human analyst.
What breakthroughs has deep learning enabled?
Deep learning has driven dramatic improvements across many fields. It achieved superhuman performance in image classification in 2012, made real-time speech recognition practical for consumer devices, enabled machine translation that rivals professional translators in many language pairs, and produced AI systems that beat world champions at chess and Go. More recently it powered the large language models behind modern AI assistants and the image generators capable of producing photorealistic artwork from text descriptions. The period from roughly 2012 to the present has seen the most rapid progress in AI capabilities in history, almost entirely driven by deep learning.
What kind of data does deep learning require?
Deep learning typically requires large quantities of labeled training data, often millions of examples, to train effectively. It also tends to require data in raw form rather than pre-processed features. Images, audio waveforms, raw text, and video are all well-suited to deep learning. When only small datasets are available, techniques like transfer learning allow practitioners to start from a model already trained on a large dataset and fine-tune it on their specific problem, dramatically reducing data requirements and training time.
What hardware is needed to train deep learning models?
Training deep learning models effectively requires Graphics Processing Units (GPUs) or specialized chips like Google’s TPUs. GPUs were originally designed for rendering video games but proved ideal for the parallel matrix operations that underlie neural network training. Training a large deep learning model can require thousands of GPUs running for weeks and cost millions of dollars in computing resources. However, running pre-trained models for inference is much cheaper and can be done on consumer hardware, and cloud platforms make powerful training hardware available on demand.
What is transfer learning and why is it important?
Transfer learning is the practice of taking a model already trained on a large dataset and adapting it for a new, related task. Instead of training from scratch, you start with a model that already understands general features of images or language and fine-tune it on your specific data. This dramatically reduces the amount of training data and computing time needed to build a high-performing model. Most practical deep learning applications today use transfer learning rather than training from scratch, making powerful AI accessible to organizations without massive data or compute resources.
What are the limitations of deep learning?
Deep learning requires large amounts of data and computing power, can be difficult or impossible to interpret, and tends to fail in unexpected ways when encountering data very different from its training distribution. It also has a tendency to be brittle, performing well on the test set but breaking down on edge cases or adversarial inputs designed to fool it. Deep learning models do not generalize the way humans do and cannot apply reasoning to new situations outside their training distribution, which remains a fundamental limitation of the current approach.
Is deep learning the same as artificial general intelligence?
No. Deep learning is a specific technical approach to building AI systems, while artificial general intelligence (AGI) refers to a hypothetical system capable of performing any intellectual task a human can. Current deep learning systems, even the most impressive ones, are narrow AI tools trained for specific tasks. They do not understand, reason, or adapt the way humans do. There is significant debate among researchers about whether scaling deep learning will eventually lead to AGI or whether fundamentally different approaches will be required.
What deep learning concepts should beginners understand first?
Start by understanding what neural networks are and how they learn through backpropagation and gradient descent. Then explore convolutional neural networks for images and transformers for text, as these are the architectures behind most practical applications today. Learn about training, validation, and test sets to understand how models are evaluated without overfitting. Experiment with pre-trained models and transfer learning through tools like Hugging Face, which lets you apply powerful deep learning to real problems without training anything from scratch and without needing massive computing resources.