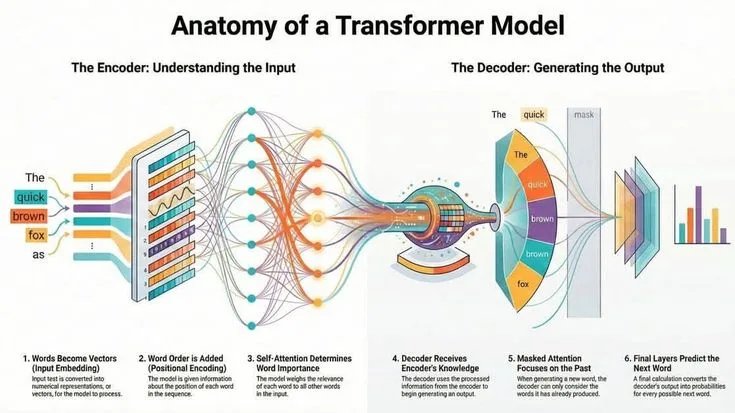
Understanding: In June 2017, eight researchers at Google published a paper titled "Attention Is All You Need." The title was a provocation, a claim that the dominant paradigm for processing sequential data was unnecessary.
Recurrent neural networks, long short-term memory networks, convolutional sequence models: the field had spent years refining these architectures for processing text, audio, and other sequential data.
The Google researchers proposed replacing all of it with a single mechanism called self-attention.
The paper introduced the transformer architecture. Within three years, virtually every major advance in artificial intelligence would be built on it. GPT, BERT, T5, PaLM, LLaMA, Claude, Gemini, all are transformers.
The image models, the audio models, the protein folding models, the code generation models, nearly all are transformers or transformer-derived. The architecture changed the field more profoundly than any single development since backpropagation.
Understanding the transformer, what it does, why it works, and what it replaced, is understanding the foundation of every modern AI system.
"The Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.", Vaswani et al., Attention Is All You Need (2017)
The original paper by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin has become one of the most cited papers in the history of computer science.
As of 2024, it had accumulated over 100,000 citations, a number that reflects not academic tribute but the practical reality that virtually every significant AI system built in the last seven years depends on its ideas.
Key Definitions
Transformer, A neural network architecture that processes sequential data using self-attention rather than recurrence or convolution. Introduced by Vaswani et al. (2017) at Google. The basis of virtually all large-scale AI language models, and increasingly applied to image, audio, video, and protein structure data.
Self-attention, The core mechanism of the transformer. For each position in an input sequence, self-attention computes a weighted representation that reflects the relationships between that position and every other position in the sequence.
The weights (attention scores) determine how much each other position contributes to the representation at the current position.
Attention mechanism, A general technique for computing context-dependent representations by selectively focusing on relevant parts of the input. Self-attention is a specific form of attention where a sequence attends to itself. The attention mechanism pre-dates transformers but was previously used as a supplement to recurrent networks.
Recurrent neural network (RNN), A neural network architecture that processes sequences one element at a time, maintaining a hidden state that accumulates information from previous elements. RNNs were the dominant architecture for sequence processing before transformers.
Their key limitation: information from early in a long sequence degrades as it passes through many processing steps before influencing later outputs.
Long short-term memory (LSTM), A variant of RNNs with gating mechanisms designed to learn longer-range dependencies. LSTMs significantly improved on vanilla RNNs for long sequences but still processed inputs sequentially, preventing parallelization during training.
Token, The basic unit of input for a transformer. Text is tokenized, split into words, subwords, or characters depending on the tokenizer, and each token is converted to a numerical vector (embedding) before processing. Modern language models typically use byte-pair encoding (BPE) or similar subword tokenization schemes.
Embedding, A numerical vector representation of a token. Embeddings encode semantic relationships: tokens with similar meanings have embeddings that are geometrically close. The transformer converts input tokens to embeddings, processes them, and converts output embeddings back to tokens.
Positional encoding, Information added to token embeddings to convey the position of each token in the sequence. Because transformers process all positions simultaneously, they have no inherent sense of order. Positional encodings inject this information.
The original paper used fixed sinusoidal functions; modern architectures often use learned or rotary position encodings.
Multi-head attention, Running multiple self-attention computations in parallel, each potentially capturing different types of relationships. The outputs are concatenated and linearly transformed. Multiple heads allow the model to represent different aspects of input relationships simultaneously.
Feed-forward layer, Each transformer layer includes a position-wise feed-forward network after the attention sublayer: a two-layer fully connected network applied independently to each position. This component introduces non-linearity and increases model capacity.
Layer normalization, A normalization technique applied at each sublayer to stabilize training by normalizing the values flowing through the network. Helps prevent the gradient problems that plagued deep networks before normalization techniques were developed.
Encoder, The transformer component that processes the full input sequence bidirectionally, producing a rich representation of the input. Encoder models (BERT and its variants) are well-suited for understanding tasks.
Decoder, The transformer component that generates output sequences autoregressively, one token at a time, with each new token attending only to previously generated tokens and the encoder output. Decoder models (GPT and its variants) are well-suited for generation tasks.
Autoregressive generation, The process by which decoder transformers generate output: producing one token at a time, with each token generated by sampling from a probability distribution conditioned on all previous tokens. The model generates the most probable continuation given everything that came before.
The Problem Transformers Solved
Sequential Processing Was a Bottleneck
Recurrent neural networks were the standard architecture for sequence processing through the mid-2010s. An RNN processes a sequence element by element: at each step, it takes the current input and the previous hidden state, produces a new hidden state, and optionally an output.
This hidden state is supposed to carry information about everything the model has seen so far.
The problem is that the hidden state is a fixed-size vector. For long sequences, compressing all relevant information into a single vector at each step is increasingly difficult. Information from early in the sequence must survive many transformations before it can influence outputs near the end of the sequence.
The further apart two elements are in the sequence, the harder it is for the network to learn the relationship between them.
LSTMs and GRUs (Gated Recurrent Units) improved on vanilla RNNs by adding gating mechanisms that helped the network selectively retain and forget information. But the fundamental bottleneck remained: sequential processing, one element at a time.
"Long Short-Term Memory can learn to bridge minimal time lags in excess of 1000 discrete-time steps by enforcing constant error flow through 'constant error carousels' within special units.", Sepp Hochreiter and Jurgen Schmidhuber, Neural Computation (1997)
LSTMs were a genuine improvement, but they did not eliminate the sequential bottleneck. And sequential processing meant sequential training: you could not start computing step 50 until you had finished step 49. This severely limited the efficiency of training on modern parallel hardware.
Machine Translation: The Domain That Exposed RNN Limits
The clearest evidence of RNN limitations emerged in machine translation. For short sentences, RNN-based sequence-to-sequence models performed well. For longer sentences, quality degraded, not because the vocabulary was harder but because the model was losing track of relationships between sentence elements separated by many words.
In a typical long sentence like "The economic policies that the government introduced last year, despite significant opposition from industry groups and several parliamentary debates, appear to have had the intended effect," an RNN must carry information about "policies" through dozens of tokens before connecting it to "appear" and "effect." Each intermediate step potentially overwrites part of the relevant state.
Bahdanau, Cho, and Bengio's 2015 attention paper (Neural Machine Translation by Jointly Learning to Align and Translate) addressed this by allowing the decoder to directly access all encoder hidden states rather than only the final one.
Their experiments showed significant improvement in translation quality for long sentences, the first clear empirical evidence that direct attention mechanisms could overcome the distance limitation.
What Vaswani et al. recognized was that attention was not a supplement, it was sufficient. If you could compute relationships between any two positions in a sequence directly, without needing recurrence to propagate information, you did not need recurrence at all.
How Self-Attention Works
The transformer processes each input token by computing a weighted combination of all tokens, where the weights reflect how relevant each token is to the current one. The mechanism uses three learned projections of each token's embedding:
Query (Q): What this token is looking for.Key (K): What this token offers to others.Value (V): What information this token contributes when attended to.
For each position, the attention weight with every other position is computed as the dot product of the query at the current position with the key at the other position, scaled and passed through a softmax function to produce a probability distribution over all positions.
The output is a weighted sum of the values, weighted by these attention probabilities.
The mathematical formulation is:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) * Vwhere d_k is the dimension of the key vectors. The scaling by sqrt(d_k) prevents the dot products from growing too large in magnitude, which would push the softmax into regions with very small gradients.
The result: each token's output representation is a mixture of all tokens' value vectors, with higher weight given to tokens that are more relevant to the current query. A token can effectively look at the entire context and incorporate information from wherever it is most relevant.
An Intuition: Subject-Verb Agreement
Consider the sentence "The books that the student borrowed are overdue." The transformer, processing the word "are," needs to determine that it should agree with "books" (the subject of the main clause), not "student" (the grammatically closer noun).
Self-attention allows "are" to directly compute a relationship with "books" regardless of the distance between them, something RNNs struggled with.
Attention analyses of trained transformers have confirmed that attention heads do learn to capture exactly these kinds of grammatical long-range dependencies.
Multi-Head Attention
Multi-head attention runs the attention computation multiple times in parallel with different learned projections. Each "head" may capture a different type of relationship: grammatical dependencies, semantic similarity, positional patterns, coreference. The outputs of all heads are concatenated and linearly transformed.
Research by Clark et al. (2019), "What Does BERT Look At? An Analysis of BERT's Attention," found that different attention heads in trained transformers learned qualitatively different functions, some heads focused on attending to the next or previous token (positional patterns), while other heads learned to attend across long-range syntactic dependencies such as verb-object pairs.
This division of function across heads emerged from training, not from explicit design.
Encoder vs. Decoder Architectures
The original transformer paper described a full encoder-decoder architecture for sequence-to-sequence tasks like translation. Subsequent work showed that the encoder and decoder components could be used independently for different purposes.
| Architecture | Attention Direction | Primary Use | Examples |
|---|---|---|---|
| Encoder-only | Bidirectional (each position attends to all positions) | Understanding tasks: classification, named entity recognition, question answering | BERT, RoBERTa, ELECTRA |
| Decoder-only | Causal (each position attends only to previous positions) | Generation tasks: text completion, dialogue, code generation | GPT-2, GPT-3, GPT-4, LLaMA, Claude |
| Encoder-decoder | Encoder: bidirectional; Decoder: causal + cross-attention to encoder | Seq-to-seq tasks: translation, summarization, question answering | T5, BART, original Transformer |
BERT: Bidirectional Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova at Google introduced BERT (Bidirectional Encoder Representations from Transformers) in 2018. The key insight: for understanding tasks, you want to use context from both before and after a token.
BERT used a pretraining task called masked language modeling, randomly masking tokens and training the model to predict the masked token from its surrounding context in both directions.
BERT's impact on the field was immediate and dramatic. Within six months of its release, BERT-based models set new state-of-the-art results on 11 NLP benchmarks.
The pattern of pretraining on large text corpora followed by fine-tuning on specific tasks became the dominant paradigm for natural language processing through the early 2020s.
GPT: The Path to Generative Power
OpenAI's GPT (Generative Pretrained Transformer) series took a different approach: a decoder-only architecture trained purely on the task of predicting the next token. Radford et al.
(2019) showed in "Language Models are Unsupervised Multitask Learners" that sufficiently large GPT-style models could perform diverse tasks, translation, summarization, question answering, as a consequence of their generative training, without task-specific fine-tuning.
GPT-3 (Brown et al., 2020), with 175 billion parameters, demonstrated that scale alone could produce remarkable emergent capabilities: few-shot learning, arithmetic, code generation, and complex reasoning that no one had explicitly trained it for.
This established the "scale hypothesis", that continued scaling of transformer language models would continue producing qualitative capability improvements.
Why Transformers Scaled So Well
Parallelization During Training
Because self-attention processes all positions simultaneously, transformers can leverage modern GPU and TPU hardware far more efficiently than RNNs, which process positions sequentially. Training an RNN on a 512-token sequence requires 512 sequential steps.
Training a transformer on the same sequence requires a fixed number of matrix operations that can be parallelized completely.
This parallelization advantage means transformers can be trained on far more data in a given amount of compute than their predecessors. More data plus more compute equals better models. The scaling advantage became a decisive factor as the field moved toward larger datasets and larger models.
The Scaling Laws
Jared Kaplan et al. at OpenAI published empirical scaling laws for transformer language models in 2020.
They found that model performance, measured by language modeling loss, follows smooth power-law relationships with model size (number of parameters), training data size (number of tokens), and compute. The relationships held across many orders of magnitude.
"We find that language modeling performance depends strongly on scale, the number of model parameters, the size of the dataset, and the amount of compute used for training, and only weakly on the model architecture within a class.", Kaplan et al., Scaling Laws for Neural Language Models (2020)
This was a profound result: it meant that making transformers better was largely a matter of making them bigger and training them on more data. The architecture was not the bottleneck, scale was. And transformers were far better positioned to scale than any previous architecture.
A subsequent refinement came from Hoffmann et al. (2022) at DeepMind in the "Chinchilla" paper, which found that the Kaplan et al. laws underestimated the importance of training data relative to model size.
Chinchilla (70B parameters, trained on 1.4 trillion tokens) substantially outperformed GPT-3 (175B parameters, trained on only 300 billion tokens), demonstrating that for a given compute budget, training a smaller model on more data generally outperforms training a larger model on less data.
Modern Developments
Sparse Attention and Efficient Transformers
Standard self-attention has quadratic complexity in sequence length: computing all pairwise attention scores for a sequence of length N requires N squared operations. For long sequences, this becomes prohibitively expensive. Numerous efficient attention variants have been developed to address this:
- Sparse attention (Child et al., 2019): Computing attention only between subsets of positions rather than all pairs, reducing complexity from O(N^2) to O(N√N)
- Linear attention (Katharopoulos et al., 2020): Approximating attention with linear complexity using kernel methods
- Sliding window attention (Beltagy et al., 2020, Longformer): Each position attends only to a local window of neighbors plus a few global tokens
- FlashAttention (Dao et al., 2022): Not reducing the theoretical complexity but dramatically improving the practical speed and memory efficiency of exact attention through careful GPU memory access patterns
FlashAttention deserves particular mention because it became nearly universally adopted in production transformer training by 2023, producing 2-4x speed improvements and enabling training on longer sequences without algorithmic approximations.
Rotary Position Encoding
The original paper used fixed sinusoidal positional encodings added to token embeddings. More recent architectures use Rotary Position Encoding (RoPE), introduced by Su et al. (2022) and adopted in LLaMA, PaLM 2, and GPT-NeoX.
RoPE incorporates position information directly into the attention computation by rotating the query and key vectors.
RoPE integrates more naturally with the attention mechanism and generalizes better to sequence lengths longer than those seen during training, a critical property for extending context windows.
Mixture of Experts
Mixture-of-Experts (MoE) architectures, popularized for transformers by Shazeer et al. (2017) and more recently in Google's Switch Transformer (Fedus et al., 2021), replace the standard feed-forward layer with multiple expert networks, selecting a subset of experts for each token rather than using all of them.
This allows models to have more total parameters without a proportional increase in compute, since only a fraction of parameters are active for any given input.
Mixtral 8x7B (Jiang et al., 2024) demonstrated that a MoE model with 46.7B total parameters but only 12.9B active parameters per forward pass could match or exceed the performance of dense 70B models while requiring less compute at inference time.
Vision Transformers
The transformer's reach has extended far beyond text. Vision Transformers (ViT), introduced by Dosovitskiy et al. (2020) at Google, applied transformers directly to images by splitting images into patches and treating each patch as a token.
ViT models trained on large datasets matched or exceeded convolutional neural networks on image classification benchmarks, demonstrating that the transformer architecture was not fundamentally linguistic.
Subsequent work applied transformers to audio (Whisper, AudioLM), video (VideoGPT), protein structure prediction (AlphaFold 2, ESMFold), weather forecasting (GraphCast), and even drug design, suggesting that the transformer represents a genuinely general-purpose architecture for learning from structured data.
AlphaFold 2: A Landmark Application
Perhaps the most dramatic single demonstration of the transformer's power outside of language came with AlphaFold 2 (Jumper et al., 2021), which solved the protein folding problem that had been considered one of biology's grand challenges for fifty years.
AlphaFold 2 used an attention-based architecture called the Evoformer to process multiple sequence alignments and structural features, achieving accuracy comparable to experimental methods.
Its results won the Critical Assessment of Protein Structure Prediction (CASP14) competition by a margin so large that many researchers described it as having "solved" the problem.
The Transformer's Limitations
Quadratic Attention Cost
The O(N^2) complexity of full self-attention limits practical sequence lengths. While techniques like FlashAttention and sparse attention alleviate this, processing extremely long contexts (millions of tokens) remains computationally expensive.
This is an active research area, with models like Mamba (Gu and Dao, 2023) proposing state-space model alternatives that achieve linear complexity.
Lack of Built-In Memory
Transformers process each input independently with no persistent memory across interactions. Everything the model can use must be in the context window. This differs from human cognition, where relevant past experiences are retrievable over much longer timescales.
Retrieval-augmented generation (RAG) and external memory architectures are partial solutions, but the fundamental design does not support long-term memory natively.
Data Hunger
Transformers at scale require enormous training datasets. Models like GPT-4 and LLaMA were trained on trillions of tokens. This data appetite creates concerns about data quality, intellectual property, privacy, and the environmental cost of training.
The Chinchilla scaling laws partly addressed compute efficiency, but the fundamental data requirement remains.
For related concepts, see what is a neural network, large language models explained, and AI training explained.
Sources & Further Reading
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30. View source
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805. View source
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI Blog. View source
- Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361. View source
- Brown, T. B., et al. (2020). Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems, 33. View source
- Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735-1780. DOI: 10.1162/neco.1997.9.8.1735
- Bahdanau, D., Cho, K., & Bengio, Y. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. arXiv preprint arXiv:1409.0473. View source
- Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., de las Casas, D., Hendricks, L. A., Welbl, J., Clark, A., et al. (2022). Training Compute-Optimal Large Language Models. arXiv preprint arXiv:2203.15556. View source
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv preprint arXiv:2010.11929. View source
- Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Ronneberger, O., Tunyasuvunakool, K., Bates, R., Zidek, A., Potapenko, A., et al. (2021). Highly Accurate Protein Structure Prediction with AlphaFold. Nature, 596, 583-589. DOI: 10.1038/s41586-021-03819-2
- Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Re, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS 2022. View source
- Clark, K., Khandelwal, U., Levy, O., & Manning, C. D. (2019). What Does BERT Look At? An Analysis of BERT's Attention. ACL Workshop on BlackboxNLP. View source
Frequently Asked Questions
What is a transformer in AI?
A transformer is a neural network architecture designed to process sequential data, text, audio, images, by computing relationships between all elements of the input simultaneously rather than one element at a time. Introduced in 2017 in the paper ‘Attention Is All You Need’ by Vaswani et al., transformers became the foundation for virtually all major AI language models including GPT, BERT, and their successors.
What is self-attention in a transformer?
Self-attention is the mechanism by which a transformer computes relationships between every element of its input and every other element simultaneously. For a sentence, self-attention allows the model to determine how much each word relates to every other word when processing any given word, capturing long-range dependencies that previous architectures handled poorly. The output of self-attention is a weighted representation of the input that encodes these relationships.
Why did transformers replace recurrent neural networks?
Recurrent neural networks (RNNs) processed sequences one element at a time, passing information forward through a hidden state. This created a bottleneck: information from early in a long sequence had to pass through many processing steps to influence later outputs, which made learning long-range dependencies difficult. Transformers process all positions simultaneously and compute relationships between any two positions directly, regardless of their distance in the sequence.
What is the difference between encoder and decoder transformers?
Encoder transformers (like BERT) process the full input bidirectionally and are designed for tasks that require understanding: classification, question answering, named entity recognition. Decoder transformers (like GPT) process input left-to-right and are designed for generation: producing text one token at a time, with each token able to attend only to previous tokens. Encoder-decoder transformers (like the original architecture and T5) combine both, with the encoder processing input and the decoder generating output.
What is positional encoding in transformers?
Because transformers process all input positions simultaneously rather than sequentially, they have no inherent sense of order. Positional encoding is added to the input embeddings to give the model information about where each token appears in the sequence. The original paper used sinusoidal functions of different frequencies to represent positions. More recent architectures use learned positional embeddings or rotary position encoding (RoPE) that integrates position information into the attention computation directly.
What is multi-head attention?
Multi-head attention runs multiple attention computations in parallel, each learning to attend to different types of relationships. One head might capture syntactic dependencies, another might capture semantic relationships, a third might capture positional patterns. The outputs of all heads are concatenated and linearly transformed. Multiple heads allow the model to simultaneously represent different types of relationships between input elements, increasing representational richness.
How large are modern transformer models?
The original transformer paper described a model with 65 million parameters. GPT-2 (2019) had 1.5 billion parameters. GPT-3 (2020) had 175 billion parameters. Modern frontier models are estimated to have hundreds of billions to over a trillion parameters, with exact counts often not disclosed publicly. Model size correlates with capability, though the relationship is not linear and architecture, training data, and fine-tuning matter as much as raw parameter count.