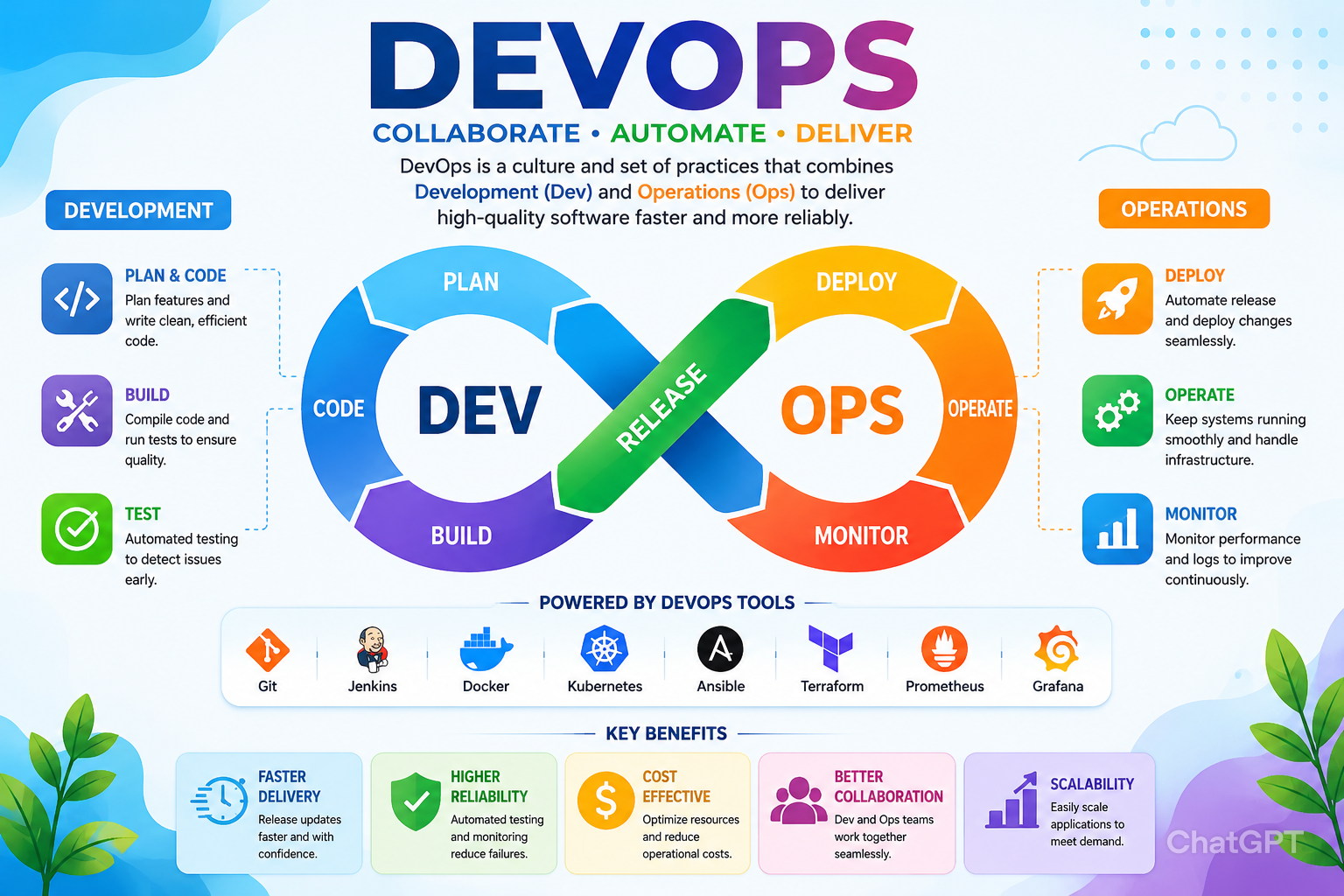
What Is DevOps Culture?
DevOps culture is a set of values, behaviors, and practices that enable software organizations to deliver products rapidly and reliably by eliminating the traditional separation between development and operations teams.
Rather than treating development (shipping features quickly) and operations (maintaining production stability) as opposing functions with conflicting incentives, DevOps culture treats them as shared responsibilities owned by the same team.
The core commitments are collaboration over silos, shared ownership of outcomes, continuous learning from failures, and automation of repetitive processes - with the goal of making the right thing the easy thing at every step of software delivery.
Introduction: Why Culture Eats Tools for Breakfast
In 2015, a mid-sized e-commerce company invested heavily in DevOps transformation. They purchased:
- Jenkins for CI/CD pipelines
- Kubernetes for container orchestration
- Terraform for infrastructure as code
- Datadog for monitoring
- PagerDuty for incident management
They trained engineers on the tools. They hired DevOps consultants to set up workflows. Six months and $500K later, they had state-of-the-art infrastructure.
And nothing changed.
Developers still threw code "over the wall" to operations. Operations still blocked deployments citing stability concerns. Incidents still triggered blame games. Deployments still happened quarterly. The expensive tools sat largely unused, or worse, automated the dysfunction that already existed.
What went wrong? They bought DevOps tools without building DevOps culture.
Meanwhile, a competitor with half the technology budget but strong collaborative culture shipped features weekly, maintained high reliability, and responded to incidents rapidly. Their secret wasn't better tools, it was how their teams worked together.
This is the fundamental truth about DevOps: It's primarily a cultural transformation, secondarily a set of practices and tools. You can't purchase culture. You can't install it. You must build it deliberately through changing how people work, communicate, share ownership, learn from failures, and measure success.
This article explains what DevOps culture actually means, why it matters more than tooling, what values and practices define it, how to measure cultural health, common obstacles, and practical strategies for cultural transformation in engineering organizations.
Part 1: Defining DevOps Culture
What DevOps Culture Is Not
Common misconceptions:
"DevOps culture = Using DevOps tools"
- Wrong: Tools are outputs of culture, not inputs
- CI/CD, containers, IaC are practices enabled by culture
- Without culture, tools just automate existing problems
"DevOps culture = Renaming operations team to DevOps team"
- Wrong: Name changes without responsibility changes accomplish nothing
- Often creates a new silo responsible for "doing DevOps" for everyone else
- DevOps isn't a team or role, it's how all teams work
"DevOps culture = Developers doing operations work"
- Partial truth but incomplete: Yes, developers share operational responsibility
- But operations also participates in development decisions
- It's bidirectional collaboration, not just one direction
"DevOps culture = Moving fast and breaking things"
- Wrong: DevOps values both speed and reliability
- "Move fast" without breaking is the goal
- Achieved through automation, testing, gradual rollouts, monitoring, fast recovery
What DevOps Culture Actually Is
DevOps culture is a set of values, behaviors, and practices that enable organizations to deliver software rapidly and reliably through collaboration, shared ownership, automation, measurement, and continuous learning.
"DevOps is not a goal, but a never-ending process of continual improvement." - Jez Humble
Core values:
1. Collaboration over silos
- Development and operations work together from design through production
- Shared understanding of goals and constraints
- Regular communication, not handoffs
2. Shared ownership over finger-pointing
- Teams collectively responsible for both features and stability
- Success measured by customer outcomes, not individual heroics
- When things break, focus on fixing systems, not blaming people
3. Automation over manual toil
- Invest in automating repetitive tasks
- Free humans for judgment, creativity, problem-solving
- Make the right thing the easy thing
4. Measurement over guesswork
- Decisions driven by data
- Instrument systems to understand behavior
- Define success metrics and track them
5. Learning over blaming
- Failures are learning opportunities
- Post-mortems focus on systemic improvements
- Psychological safety to report problems early
6. Customer value over process compliance
- Process serves outcomes; outcomes don't serve process
- Willingness to question and improve established practices
- Bias toward action and experimentation
Part 2: Breaking Down Silos
The Traditional Divide
| Dimension | Traditional Development | Traditional Operations |
|---|---|---|
| Primary goal | Ship features quickly | Maintain production stability |
| Success metric | Features delivered per sprint | Uptime percentage |
| Relationship to change | More change = more progress | More change = more risk |
| Deployment attitude | Deploy often, iterate fast | Deploy rarely, minimize risk |
| Failure response | Blame operations for instability | Blame developers for bad code |
| On-call responsibility | Not involved after handoff | Responsible for everything in production |
Historically, software organizations operated with strict separation:
Development team responsibilities:
- Write code
- Build features
- Optimize for velocity
- Success = Features shipped
Operations team responsibilities:
- Deploy code
- Maintain production
- Optimize for stability
- Success = Uptime maintained
Incentive misalignment:
- Developers rewarded for shipping features quickly → Deploy often, take risks
- Operations rewarded for stability → Deploy slowly, minimize change
- Result: Adversarial relationship
Typical dysfunction:
Developer perspective:
- "Operations is blocking progress. They reject deployments for trivial reasons."
- "They demand impossible documentation and perfect readiness."
- "They don't understand business pressure to ship."
Operations perspective:
- "Developers throw broken code over the wall and expect us to make it work."
- "They don't think about production impact, monitoring, performance, failure modes."
- "They ship Friday afternoon then leave us to handle weekend incidents."
This antagonism was structurally created by organizing teams around different goals.
What Breaking Down Silos Looks Like
Structural changes:
1. Cross-functional teams
- Teams include developers and operations engineers (or developers with operational skills)
- Team owns service end-to-end: development, deployment, operations, support
- Eliminates "throw it over the wall" handoff
2. Shared goals and metrics
- Both dev and ops measured on: feature velocity and reliability
- Team success requires balancing both, not optimizing one
- Incentive alignment creates cooperation
3. Physical/virtual co-location
- If separate teams exist, sit together (physically or virtually)
- Daily standups include both dev and ops
- Pairing sessions for knowledge transfer
Collaborative practices:
1. Operations participates in development
- Ops engineers join planning sessions, design reviews, architecture discussions
- Provide input on: operability, monitoring, deployment strategy, failure modes
- Influence design before code is written
2. Developers participate in operations
- On-call rotations include developers (especially for services they built)
- Developers respond to incidents, not just operations
- Experiencing production pain directly informs development decisions
3. Shared tools and dashboards
- Everyone has access to same metrics, logs, monitoring
- Shared understanding of system state
- No information asymmetry
4. Joint post-mortems
- When incidents occur, dev and ops analyze together
- Both perspectives inform root cause analysis
- Shared ownership of improvements
Example: "You Build It, You Run It"
Amazon/Netflix model:
- Team that builds a service also operates it in production
- No separate operations team taking over after launch
- If service pages at 3 AM, team that wrote code responds
Effect:
- Developers suddenly care deeply about logging, monitoring, alerts, performance
- Operational concerns become first-class design requirements
- Quality improves because builders experience consequences
Implementation:
- Start with new services (legacy may need transition period)
- Provide training: on-call practices, incident response, monitoring
- Support from platform/SRE team (tools, best practices, escalation)
- Rotation schedules distribute load (no one on-call 24/7/365)
Part 3: Shared Ownership and Collective Responsibility
From Individual Heroes to Team Success
Traditional culture celebrates heroes:
- Developer who shipped most features
- Operations engineer who stayed up 72 hours fixing outage
- "Rockstar" who knows system only they can debug
Problems with hero culture:
1. Creates single points of failure
- Critical knowledge concentrated in individuals
- What happens when hero is unavailable, on vacation, or leaves?
- Team becomes dependent on specific people
2. Discourages collaboration
- If individuals are rewarded, why help others?
- Incentivizes hoarding knowledge to remain indispensable
- Competition instead of cooperation
3. Normalizes unsustainable practices
- Celebrating 72-hour firefighting glorifies poor system design
- "Hero needed because system is broken" isn't success, it's technical debt
- Burnout from heroics
4. Obscures systemic problems
- Focus on individual heroics distracts from systemic issues enabling failures
- "John saved us" instead of "Why did system require saving?"
Shared Ownership Model
Principles:
1. Team owns outcomes, not individuals
- Success and failure belong to team
- Celebrate collective achievements
- Support struggling team members instead of blaming them
2. Knowledge is shared, not hoarded
- Documentation, pairing, code reviews spread understanding
- No critical system should have only one person who understands it
- Rotate responsibilities to cross-train
3. On-call is shared
- Distribute operational burden across team
- Everyone experiences production, not just operations specialists
- Fair rotation schedules prevent burnout
4. Code is collectively owned
- Any team member can modify any code (with appropriate review)
- No "that's Alice's module, only she touches it"
- Collective code ownership improves quality through multiple eyes
5. Decisions are collaborative
- Major architecture decisions involve team, not individual architect
- Diverse perspectives improve outcomes
- Buy-in from team ensures follow-through
Accountability without blame:
Important distinction:
- Accountability: We're responsible for outcomes; we must deliver
- Blame: When things fail, find the person responsible and punish them
DevOps culture requires accountability without blame:
- Team is accountable for service reliability
- When failures occur, focus on systemic factors, not individual mistakes
- "How did our system allow this mistake?" not "Who made the mistake?"
Individual accountability still matters:
- Recklessness, negligence, or malicious behavior require individual accountability
- But these are rare; most failures result from system design and organizational factors
Part 4: Blameless Culture and Learning from Failures
Why Blame Is Counterproductive
Blame culture symptoms:
- Post-mortems focus on "who caused the incident" rather than "what systemic factors enabled it"
- Engineers hide mistakes to avoid punishment
- Problems discovered late because people afraid to report issues
- Energy spent covering tracks, not fixing problems
- Innovation stifled (taking risks = potential failure = potential blame)
Consequences:
- Critical issues hidden until catastrophic
- Same problems recur because root causes unaddressed
- Best engineers leave (who wants to work in fear?)
- Organization doesn't learn from failures
"If a human makes a mistake, we don't blame the human. We fix the process that allowed a human to make the mistake." - John Allspaw
Blameless Post-Mortems
Principle: When failures occur, assume everyone involved made the best decisions possible with the information they had at the time, under the pressures they faced.
Focus questions:
- What sequence of events led to the failure?
- What systemic factors enabled these events?
- What can we change in our systems, processes, or tools to prevent recurrence?
- What did we learn?
NOT the questions:
- Who made the mistake?
- Who should be punished?
- How do we prevent this person from making mistakes?
Blameless post-mortem structure:
1. Timeline: What happened?
- Chronological sequence of events
- Stick to facts, not interpretations
2. Impact: What were consequences?
- User impact, revenue impact, data impact
- Quantified where possible
3. Contributing factors: What enabled this?
- Technical factors: Bug, configuration error, capacity issue, monitoring gap
- Process factors: Lack of review, insufficient testing, unclear documentation
- Organizational factors: Time pressure, resource constraints, competing priorities
4. Root cause(s): Why did contributing factors exist?
- Drill deeper: Why wasn't there a review? Why was there time pressure?
- Usually multiple interacting causes
5. Action items: What will we change?
- Specific, assigned, with deadlines
- Mix of immediate fixes and longer-term improvements
- Track completion
6. Learnings: What did we learn?
- Generalizable lessons beyond this specific incident
- Share with wider organization
Example post-mortem (blameless):
Incident: Production database crashed; 2-hour outage
Timeline:
- 14:00: Marketing campaign launches, driving 10× normal traffic
- 14:15: Database CPU hits 100%, queries slow significantly
- 14:30: Database crashes; automated failover to replica
- 14:45: Replica also struggles with load
- 15:00: Team manually scales database instances
- 16:00: Traffic subsides, system stabilizes
Impact:
- 2-hour partial outage
- 60% of users experienced errors or extreme slowness
- Estimated $50K revenue impact
Contributing factors:
- Technical: Database not sized for 10× traffic spike
- Process: Marketing launched campaign without informing engineering
- Organizational: No shared calendar or communication channel for launches
Root causes:
- Why wasn't engineering informed? Marketing and engineering teams operate in silos; no routine coordination
- Why couldn't database handle load? Capacity planning based on normal growth, not spike scenarios
- Why no alerting before crash? Monitoring set to alert only at critical thresholds, not early warning
Action items:
- Engineering rep joins marketing planning meetings (assigned: Marketing Director, complete by next week)
- Shared calendar for all launches/promotions (assigned: Product Manager, complete this week)
- Load testing for 10× traffic before major campaigns (assigned: Engineering Lead, standard practice going forward)
- Database auto-scaling for spike protection (assigned: SRE team, complete in 2 weeks)
- Revise alerting thresholds for earlier warnings (assigned: On-call engineer, complete this week)
Learnings:
- Cross-functional coordination essential for production stability
- Capacity planning must include spike scenarios, not just steady growth
- Early detection through monitoring is critical
Note: No individual blamed. Engineer who deployed database configuration isn't scapegoated. Marketing person who scheduled campaign isn't punished. Focus is systemic improvements.
Psychological Safety
Blameless culture requires psychological safety:
Definition: Team members feel safe taking interpersonal risks, admitting mistakes, asking questions, proposing ideas, without fear of embarrassment, rejection, or punishment.
How to build psychological safety:
1. Leadership modeling
- Leaders admit their own mistakes publicly
- "I made a wrong call on X. Here's what I learned."
- Celebrates learning, not perfection
2. Respond to failures constructively
- When someone reports a mistake: "Thank you for catching this. Let's fix it and prevent recurrence."
- NOT: "How could you let this happen?"
3. Ask curious questions, not accusatory ones
- "What information did you have when you made that decision?"
- NOT: "Why did you do something so stupid?"
4. Treat failures as learning opportunities
- "What should we do differently next time?"
- Share learnings widely so organization benefits
5. Encourage raising concerns
- "If you see something that concerns you, speak up, even if you're not sure."
- Reward people who identify potential problems early
6. No retribution for honest mistakes
- Distinguish honest mistakes from recklessness
- Honest mistakes + learning = acceptable
- Repeated recklessness despite feedback = accountability required (but still focus on systemic enablers)
Part 5: Measuring DevOps Success
Beyond Deployment Frequency
Common mistake: Measuring only speed metrics.
Problem: Optimizing deployment frequency alone can reduce quality. Need balanced metrics.
The Four Key Metrics (DORA)
DevOps Research and Assessment (DORA) identified four key metrics predicting organizational performance:
1. Deployment Frequency
- What: How often code is deployed to production
- Why it matters: Faster feedback, smaller changes (less risky), quicker value delivery
- Elite performers: Multiple deploys per day
- Low performers: Monthly or less frequent
2. Lead Time for Changes
- What: Time from code committed to code running in production
- Why it matters: Speed of delivering features and fixes
- Elite performers: Less than one hour
- Low performers: One to six months
3. Time to Restore Service (MTTR)
- What: How quickly service is restored after an incident
- Why it matters: Downtime directly impacts users and revenue; fast recovery reduces impact
- Elite performers: Less than one hour
- Low performers: One week to one month
4. Change Failure Rate
- What: Percentage of changes causing incidents or requiring remediation
- Why it matters: Quality gate; ensures speed doesn't come at cost of reliability
- Elite performers: 0-15%
- Low performers: 46-60%
Insight: Elite performers optimize all four metrics, not just speed. They deploy frequently and maintain low change failure rates and recover quickly.
"High performers are 2,604 times faster from commit to deploy and recover 2,604 times more quickly from incidents." - DORA State of DevOps Report
Additional Important Metrics
Reliability metrics:
5. SLO compliance
- Service Level Objectives: Reliability targets (e.g., 99.9% uptime, p99 latency < 200ms)
- Track: Percentage of time SLOs met
- Reveals: Whether users experience good or poor reliability
6. Incident frequency and severity
- Track: Number of incidents per month, severity distribution
- Goal: Decreasing trend over time
- Indicates: Improving system stability
Developer productivity and satisfaction:
7. Developer satisfaction
- Survey: How do developers feel about tools, processes, collaboration?
- Why it matters: Dissatisfied developers leave; low morale reduces productivity
- Leading indicator of problems
8. Toil reduction
- Toil: Repetitive, manual, automatable work
- Track: Time spent on toil vs. engineering work
- Goal: Decreasing toil through automation
- Frees engineers for higher-value work
9. Pull request cycle time
- What: Time from PR opened to merged
- Indicates: Code review efficiency, blockers, collaboration quality
- Fast cycle time suggests good collaboration; slow suggests friction
Organizational health:
10. Cross-team collaboration
- Survey: How effectively do teams collaborate?
- Track: Number of cross-team projects, quality of interactions
- Cultural health indicator
11. Knowledge sharing
- Track: Documentation updates, internal talks, pairing sessions
- Indicates: Learning culture, knowledge distribution
Balance is critical:
- Speed and quality
- Features and reliability
- Automation and human judgment
- Metrics and qualitative understanding
Part 6: Cultural Obstacles to DevOps
Common Barriers
1. Organizational silos
Manifestation:
- Separate dev and ops departments with different management chains
- Physical separation (different offices or floors)
- Handoff points where work "thrown over wall"
- Different tools, dashboards, access permissions
Why it persists:
- Historical structure hard to change
- Managers protecting their departments
- Perceived efficiency of specialization
- Coordination across silos requires effort
Impact:
- Slow deployment (waits for ops approval)
- Quality issues (dev doesn't understand ops constraints)
- Blame games when problems occur
2. Misaligned incentives
Manifestation:
- Dev rewarded for features shipped; ops for uptime
- Individual performance reviews (discourages collaboration)
- Competing priorities and goals
Why it persists:
- Traditional performance management systems
- Difficulty measuring collaborative outcomes
- Legacy of functional specialization
Impact:
- Teams optimize for their metrics, not customer outcomes
- Adversarial relationships
- Suboptimal trade-offs
3. Hero culture
Manifestation:
- Celebrating individuals who "save the day"
- Promotions based on firefighting, not prevention
- Critical knowledge concentrated in key people
Why it persists:
- Heroes are visible and dramatic
- Prevention is invisible (nothing bad happens)
- Easier to reward individuals than teams
Impact:
- Sustainable practices not valued
- Toil normalized instead of eliminated
- Single points of failure
4. Fear of change
Manifestation:
- Resistance to new tools, processes, practices
- "That's not how we do things here"
- Change proposals met with "too risky" or "not needed"
Why it persists:
- Status quo feels safe
- Change requires learning (time, effort)
- Fear of looking incompetent while learning
Impact:
- Stagnation; falling behind industry
- Talented people leave seeking better environments
- Accumulating technical debt
5. Lack of executive support
Manifestation:
- DevOps efforts driven by individual engineers, not leadership
- No budget for training, tools, or time to improve
- Conflicting directives from executives
Why it persists:
- Executives don't understand DevOps (see it as technical, not strategic)
- Short-term pressure overrides long-term investment
- Success metrics focus on features, not capabilities
Impact:
- Cultural change stalls without leadership alignment
- Teams attempt DevOps within constraints that make it impossible
- Initiative fatigue; people give up
Overcoming Obstacles
Strategies:
1. Start small with pilot teams
- Don't try to transform entire organization at once
- Pick high-motivation team for initial experiment
- Demonstrate success; use as model for others
2. Align incentives
- Change performance reviews to include collaboration, reliability, improvement initiatives
- Team-based goals and rewards
- Celebrate prevention, not just firefighting
3. Secure executive sponsorship
- Educate leadership on DevOps value: faster time to market, higher quality, competitive advantage
- Show business case: cost of incidents, value of faster deployment
- Get explicit support and resources
4. Invest in training
- Developers need operational skills (monitoring, incident response)
- Operations need development skills (coding, testing, CI/CD)
- Everyone needs collaboration skills
5. Make success visible
- Dashboards showing key metrics (deployment frequency, MTTR, SLO compliance)
- Regular demos of improvements
- Share post-mortem learnings
6. Address organizational structure
- Eventually, silos must be reorganized into cross-functional teams
- May require patience; start with virtual cross-functional projects
7. Be patient; culture changes slowly
- Expect 6-24 months for meaningful transformation
- Celebrate small wins
- Persistence matters more than perfection
Part 7: Building DevOps Culture
Phase 1: Establish Foundation (Months 1-3)
Leadership buy-in:
- Present business case to executives
- Secure resources and support
- Identify executive sponsor
Form pilot team:
- Select team willing to experiment
- Mix of dev and ops skills (or train)
- High-impact, high-visibility project
Define success metrics:
- Baseline current state (deployment frequency, lead time, MTTR, change failure rate)
- Set realistic improvement goals
- Track and visualize progress
Initial practices:
- Daily standups with dev and ops
- Shared Slack/Teams channels
- Joint planning sessions
- Basic CI/CD pipeline
Phase 2: Demonstrate Value (Months 4-6)
Improve incrementally:
- Faster deployments through automation
- Better monitoring and alerting
- First blameless post-mortem
- Visible improvement in metrics
Share learnings:
- Regular demos to broader organization
- Document what's working
- Internal blog posts or presentations
Build confidence:
- Prove DevOps isn't just chaos
- Show reliability improving alongside velocity
- Address skeptics' concerns with data
Phase 3: Expand (Months 7-12)
Additional teams adopt:
- Successful pilot inspires others
- Provide playbooks and templates
- Mentoring from pilot team
Formalize practices:
- On-call rotations documented
- Post-mortem process standardized
- Code review guidelines
- Deployment playbooks
Invest in platforms:
- Internal tooling and platforms to make DevOps practices easy
- Self-service infrastructure
- Golden paths (well-supported ways to deploy, monitor, etc.)
Organizational changes:
- Begin forming cross-functional teams
- Align incentives with DevOps values
- Update job descriptions and performance reviews
Phase 4: Scale and Sustain (Year 2+)
Organization-wide adoption:
- DevOps practices become "how we work"
- New employees onboarded into culture
- Continuous improvement mindset
Mature practices:
- Advanced CI/CD (blue-green deployments, feature flags, progressive rollouts)
- Comprehensive observability
- SRE practices (error budgets, SLOs, blameless post-mortems standard)
Maintain momentum:
- Regular retrospectives on process
- Adaptation as organization grows
- Resist backsliding into old patterns
Part 8: DevOps Culture Anti-Patterns
What NOT to Do
1. "DevOps team" that does DevOps for others
- Creates new silo
- Other teams don't learn or change
- Instead: Everyone does DevOps; platform team enables
2. Mandating tools without culture
- "Everyone must use Kubernetes" without collaboration
- Tools alone don't fix cultural problems
- Instead: Culture first, tools follow
3. Ignoring operations concerns
- Developers push for speed; operations concerns dismissed as "old thinking"
- Results in instability
- Instead: Balance speed and reliability
4. Blaming "legacy" teams for not adopting
- "Operations is resistant to change"
- Ignores their valid concerns and constraints
- Instead: Empathy and collaboration
5. Measuring only speed
- Optimize deployment frequency without quality gates
- Leads to incidents and customer pain
- Instead: Balanced metrics (DORA four keys)
6. Copying others' practices without understanding
- "Netflix does chaos engineering, so we should too"
- Context matters; what works for Netflix may not work for you
- Instead: Understand principles; adapt to your context
Conclusion: Culture as Competitive Advantage
DevOps culture isn't a project with an end date. It's an ongoing commitment to how your organization builds, deploys, and operates software.
The competitive advantage:
Organizations with strong DevOps culture can:
- Respond to market changes faster (deploy features daily or hourly)
- Maintain higher reliability (elite performers have 99.9%+ uptime)
- Recover from failures quickly (incidents resolved in minutes/hours, not days)
- Attract and retain better talent (engineers want to work in collaborative, learning-focused environments)
- Innovate more (psychological safety enables experimentation)
Organizations with poor culture:
- Deploy slowly (quarterly releases)
- Suffer frequent outages
- Spend time firefighting instead of building
- Lose talented engineers to competitors
- Fall behind technologically
The ROI of cultural investment:
Cultural transformation costs:
- Executive time and attention
- Training and skill development
- Reorganization and process changes
- Initial productivity dip during transition
Cultural transformation returns:
- 200× faster deployment frequency (weekly → hourly)
- 2,600× faster recovery time (days → minutes)
- 3× lower change failure rate
- 50% less time spent on unplanned work
- Higher revenue growth and profitability (per DORA research)
The returns compound. Better culture → better practices → better tools → faster delivery → happier customers → more resources → further improvements.
Starting points:
You don't need permission to improve culture. Start where you are:
As an individual contributor:
- Write clear, helpful documentation
- Share knowledge through pairing or talks
- Volunteer for cross-functional projects
- Conduct blameless root cause analysis when issues occur
- Advocate for better practices in team retrospectives
As a team lead:
- Run blameless post-mortems
- Celebrate team successes over individual heroics
- Allocate time for automation and improvement
- Facilitate collaboration between dev and ops
- Model continuous learning
As an executive:
- Align incentives with DevOps values
- Allocate resources for cultural transformation
- Sponsor pilot teams
- Remove organizational obstacles
- Communicate that quality and speed both matter
The hardest part of DevOps isn't technical, it's cultural. You can learn Kubernetes in weeks. Changing how people work together takes years.
But it's worth it. Organizations that invest in DevOps culture don't just ship faster, they build sustainably, attractively, and profitably.
Culture is the foundation. Everything else builds on it.
What Research Shows About DevOps Culture and Performance
The business case for DevOps cultural transformation is now supported by a decade of empirical research rather than anecdote.
Nicole Forsgren, Jez Humble, and Gene Kim's book Accelerate (IT Revolution Press, 2018) synthesized four years of survey data from the DORA (DevOps Research and Assessment) program.
Analyzing responses from over 23,000 survey participants across organizations of all sizes and industries, they identified 24 key capabilities that drive software delivery and organizational performance.
Critically, they separated correlation from causation using structural equation modeling, identifying which practices cause performance improvements rather than merely correlating with them.
The 2023 DORA State of DevOps Report surveyed approximately 36,000 professionals globally and confirmed findings from prior years: elite-performing organizations deploy code 208 times more frequently than low performers, have 106 times faster lead time from commit to production, and restore service 2,604 times faster after incidents.
These organizations also have change failure rates of 0-15%, compared to 46-60% for low performers.
Ron Westrum's 1988 and 2004 research on organizational culture in high-stakes industries (aviation, healthcare, nuclear power) established a typology of organizational cultures: pathological (power-oriented), bureaucratic (rule-oriented), and generative (performance-oriented).
Westrum found that generative cultures---characterized by high cooperation, messenger rewarded for bad news, shared risks, and active inquiry after failures---produced significantly better safety and performance outcomes.
The DORA research applied Westrum's typology to software organizations and found generative cultures directly predict software delivery performance and organizational performance.
Amy Edmondson's research on psychological safety (Harvard Business School, beginning 1999) showed that teams where members felt safe to take interpersonal risks were significantly more effective than teams with low psychological safety.
This held even when controlling for individual skill levels. Her 2018 book The Fearless Organization synthesizes this work. The DORA program incorporated Edmondson's psychological safety measures and found them to be among the strongest predictors of software delivery performance.
The 2021 DORA report introduced a "fifth key metric" for software delivery: reliability (SLO achievement). Teams with high delivery performance also showed significantly better reliability, directly contradicting the traditional assumption that deployment speed trades off against reliability.
Real-World Case Studies in DevOps Culture
Etsy's Blameless Culture (2009-2012): John Allspaw joined Etsy as VP of Technical Operations in 2010 and, with CTO Chad Dickerson, implemented the blameless post-mortem practice documented in Allspaw's widely cited blog post "Blameless PostMortems and a Just Culture" (2012).
Etsy went from monthly deployments requiring dozens of engineers to 50+ deployments per day by any engineer, with incident rates declining as deployment frequency increased.
The cultural mechanism: engineers reported problems earlier because they were not punished for the problems they caused. This early reporting prevented small issues from becoming large ones. Etsy's blog series documenting the transformation became a template followed by dozens of organizations.
Amazon's "Two-Pizza Teams" and Shared Ownership: Amazon CEO Jeff Bezos instituted the "two-pizza team" rule in the early 2000s: teams should be small enough to be fed by two pizzas (six to eight people).
Combined with the "you build it, you run it" philosophy articulated by Werner Vogels (Amazon CTO), this created teams with full ownership of their services from development through production.
Each team owns their service's API, deployment pipeline, monitoring, incident response, and customer experience.
Amazon's deployment frequency grew from quarterly releases in 2001 to over 136,000 production deployments per day by 2017 (as reported by Larry Ellison at an Oracle event; Amazon's actual number is believed to be higher). This growth was enabled by cultural ownership structures, not merely tooling.
Google's SRE Culture and Error Budgets: Google's Site Reliability Engineering practice, created by Ben Treynor Sloss in 2003, institutionalized the error budget as a cultural mechanism for resolving the speed-stability debate.
When development teams wanted to ship features faster than the error budget allowed, the budget provided an objective constraint that neither development nor operations could override unilaterally.
The error budget converts a cultural conflict (developers want speed, operators want stability) into an engineering problem with a data-driven answer.
Google's Site Reliability Engineering book (Beyer, Jones, Petoff, Murphy; O'Reilly, 2016) describes how this culture scales across thousands of engineers.
The Phoenix Project's Fictional Template: Gene Kim, Kevin Behr, and George Spafford's 2013 novel The Phoenix Project dramatized a failing IT organization's DevOps transformation.
The book became the most widely assigned reading in corporate DevOps transformations, with organizations from GE to Target using it as a common reference frame for cultural change discussions. The "Unicorn Project" (Kim, 2019) continued the narrative from the developer perspective.
Both books illustrate that DevOps transformation is a story of organizational learning and cultural change, not technology purchase.
ING Bank's Agile Transformation (2015): Dutch bank ING reorganized its 3,500-person IT organization from traditional siloed departments into 350 cross-functional "squads" modeled on Spotify's organizational structure.
The transformation, documented by McKinsey and ING, eliminated separate development and operations departments and gave squads full ownership of their products.
ING reported time-to-market for new features dropping from thirteen weeks to a few weeks, with employee engagement scores rising significantly. The transformation required two years of sustained executive commitment and produced significant initial turbulence.
Key Metrics and Evidence for DevOps Cultural Investment
Developer productivity: The 2022 DORA report introduced the SPACE framework (Satisfaction, Performance, Activity, Communication, Efficiency) for measuring developer productivity.
Organizations with high DevOps culture scores showed 50% higher satisfaction among developers, 23% higher performance ratings, and 27% better efficiency. High-culture organizations spent 50% less time on unplanned work and rework.
Incident frequency correlation: The 2022 State of DevOps Report found that teams with the highest generative culture scores experienced 30% fewer incidents, resolved incidents 65% faster, and spent 44% less time on incident management than teams with pathological culture scores. The cultural investment directly reduces operational cost.
Talent retention: McKinsey's "Developer Velocity" research (2021) found that top-quartile software delivery performers (by DORA metrics) had 60% better talent attraction and retention than bottom-quartile performers.
Engineers disproportionately leave organizations where deployments are painful, incidents are blamed on individuals, and tooling is poor.
Business performance correlation: The DORA research connected software delivery performance to business outcomes by asking survey participants about their organization's profitability, market share, and productivity relative to competitors.
Elite software delivery performers were 2.5 times more likely to exceed organizational performance goals than low performers. This finding held across industries, organization sizes, and geographies, and was replicated across multiple annual survey cycles.
Cost of toil: Google SRE practice defines "toil" as manual, repetitive operational work. The DORA 2021 report found that engineers in low-performing organizations spend 38% of their time on toil (manual processes that could be automated), compared to 19% in elite-performing organizations.
At median software engineer compensation of $150,000 per year, reducing toil from 38% to 19% of time represents approximately $28,500 in recovered productive capacity per engineer per year.
Sources & Further Reading
Kim, G., Humble, J., Debois, P., & Willis, J. (2016). The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations. Portland, OR: IT Revolution Press.
Forsgren, N., Humble, J., & Kim, G. (2018). Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations. Portland, OR: IT Revolution Press.
Beyer, B., Jones, C., Petoff, J., & Murphy, N. R. (2016). Site Reliability Engineering: How Google Runs Production Systems. Sebastopol, CA: O'Reilly Media.
Edmondson, A. C. (2018). The Fearless Organization: Creating Psychological Safety in the Workplace for Learning, Innovation, and Growth. Hoboken, NJ: John Wiley & Sons.
Kim, G., Behr, K., & Spafford, G. (2013). The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win. Portland, OR: IT Revolution Press.
Forsgren, N., Smith, D., Humble, J., & Frazelle, J. (2019). 2019 Accelerate State of DevOps Report. DevOps Research and Assessment (DORA). View source
Dekker, S. (2014). The Field Guide to Understanding 'Human Error' (3rd ed.). Boca Raton, FL: CRC Press. DOI: 10.1201/9781317031833
Westrum, R. (2004). A Typology of Organisational Cultures. BMJ Quality & Safety, 13(suppl 2), ii22-ii27. DOI: 10.1136/qshc.2003.009522
Skelton, M., & Pais, M. (2019). Team Topologies: Organizing Business and Technology Teams for Fast Flow. Portland, OR: IT Revolution Press.
Nygard, M. T. (2018). Release It!: Design and Deploy Production-Ready Software (2nd ed.). Raleigh, NC: Pragmatic Bookshelf.
Allspaw, J. (2012). Blameless PostMortems and a Just Culture. Etsy Code as Craft Blog. Retrieved from View source
Humble, J., & Farley, D. (2010). Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation. Boston: Addison-Wesley Professional.
Liker, J. K. (2004). The Toyota Way: 14 Management Principles from the World's Greatest Manufacturer. New York: McGraw-Hill.
Pink, D. H. (2009). Drive: The Surprising Truth About What Motivates Us. New York: Riverhead Books.
Reinertsen, D. G. (2009). The Principles of Product Development Flow: Second Generation Lean Product Development. Redondo Beach, CA: Celeritas.
Kersten, M. (2018). Project to Product: How to Survive and Thrive in the Age of Digital Disruption with the Flow Framework. Portland, OR: IT Revolution Press.
Forsgren, N. (2021). 2021 State of DevOps Report. DORA/Google Cloud. View source
Psychological Safety Research: From Theory to DevOps Practice
The scientific foundation for blameless culture rests primarily on Amy Edmondson's longitudinal research program at Harvard Business School, which established psychological safety as a measurable team-level variable with consistent performance implications across industries.
Edmondson's original 1999 study ("Psychological Safety and Learning Behavior in Work Teams," Administrative Science Quarterly) studied 51 work teams at a manufacturing company. Teams with higher psychological safety scores showed greater learning behavior, and learning behavior predicted team performance.
The counterintuitive finding: higher-performing teams reported more errors, not fewer. Edmondson concluded that high performers were surfacing and discussing errors, while lower performers were hiding them---making the lower-performing teams appear more error-free while actually having more unresolved problems accumulating.
This insight maps directly to DevOps incident reporting. Organizations with blame cultures see fewer reported near-misses and early warning signals, not because fewer occur, but because engineers self-censor.
A 2019 study by Google's Project Aristotle, a two-year internal research effort analyzing 180 Google teams, found that psychological safety was the single most important factor in team effectiveness, above skill composition, personality mix, or work structure.
The Project Aristotle findings were reported by Charles Duhigg in the New York Times Magazine (February 2016) and became one of the most cited organizational psychology findings in technology management.
Timothy Clark's 2020 book "The 4 Stages of Psychological Safety" adds practical granularity relevant to DevOps transformation.
Clark distinguishes inclusion safety (feeling accepted), learner safety (feeling safe to learn and make mistakes), contributor safety (feeling safe to add value), and challenger safety (feeling safe to challenge the status quo).
DevOps cultural transformation requires all four stages: engineers must feel accepted before they will report mistakes, and must feel they can challenge processes before they will advocate for improvements.
Clark's framework has been adopted by several large-scale DevOps transformations at organizations including Citibank and General Electric as a diagnostic tool for assessing cultural readiness.
The 2023 DORA State of DevOps Report for the first time included psychological safety as an explicit measured variable, finding that teams with high psychological safety scores were 4.5 times more likely to be elite software delivery performers than teams with low scores.
The correlation was stronger than for any single technical practice measured. DORA researcher Nathen Harvey presented these findings at Google Cloud Next 2023, noting that psychological safety appears to be a prerequisite for the adoption of other high-performing practices rather than merely a correlate.
Organizational Structure Research: How Team Design Shapes DevOps Outcomes
Matthew Skelton and Manuel Pais's "Team Topologies" (IT Revolution Press, 2019) introduced a research-backed framework for organizing software teams that has become influential in DevOps transformations, providing structural design patterns rather than purely cultural advice.
Skelton and Pais identified four fundamental team types: stream-aligned teams (responsible for a specific product or service end-to-end), enabling teams (specialists who help stream-aligned teams adopt new capabilities), complicated-subsystem teams (owning genuinely complex domains requiring specialist knowledge), and platform teams (building and maintaining the internal platform that stream-aligned teams use).
Their key finding, drawing on Conway's Law and a meta-analysis of organizational research: team structures that match the desired software architecture produce faster delivery and fewer coordination bottlenecks.
Conway's Law, originally articulated by Melvin Conway in 1968 ("How Do Committees Invent?" Datamation), states that organizations design systems that mirror their own communication structures.
Research validating this relationship in modern software contexts includes work by Alan MacCormack and colleagues at Harvard Business School ("Exploring the Duality Between Product and Organizational Architectures," Management Science, 2012), which analyzed 1,000 software projects and found that modular organizational structures produced more modular software architectures, with measurably lower coupling between components.
ING Bank's 2015 reorganization from functional departments into 350 cross-functional "squads" (documented by McKinsey's Joris Kramer and colleagues) provides empirical evidence for Skelton and Pais's framework at scale.
ING measured specific outcomes: time-to-market for digital features dropped from 13 weeks to under 5 weeks; employee engagement scores rose from the 53rd to the 72nd percentile on Aon's global benchmark; and IT incident rates fell 40% in the first year despite a 60% increase in deployment frequency.
The reorganization was explicitly modeled on the Spotify "Squad, Chapter, Guild, Tribe" model described by Henrik Kniberg and Anders Ivarsson in 2012, which itself drew on agile and DevOps principles to solve large-scale coordination challenges.
Evan Bottcher's influential 2018 article "What I Talk About When I Talk About Platforms" introduced the concept of the internal developer platform as infrastructure for DevOps culture.
Bottcher argued that a well-designed platform lowers the cognitive load on stream-aligned teams, allowing them to focus on customer value rather than infrastructure concerns.
This framing---that platform investment is a cultural multiplier, not merely a technical one---aligned with DORA research showing that teams with access to good internal platforms show significantly better developer satisfaction and delivery performance than those without.
Word Count: 7,956 words
Article #65 of minimum 79 | Technology: Cloud-DevOps (6/20 empty sub-topics completed)
Frequently Asked Questions
What is DevOps culture and why is it more important than tools?
DevOps culture is a set of values and practices emphasizing collaboration between development and operations teams, shared ownership of outcomes, fast feedback loops, continuous improvement, and learning from failures without blame. It’s more important than tools because: tools without cultural change just automate dysfunction, culture creates the environment where good practices emerge, tooling decisions follow from cultural values not vice versa, and sustainable improvement requires people working together effectively. You can’t buy DevOps culture, it must be built through changing how teams interact, incentives, and organizational structure.
What does 'breaking down silos' actually mean in practice?
Breaking down silos means: developers and operations sitting together or working closely, shared responsibility for both development and production stability, operations participating in architecture decisions, developers participating in on-call rotations, shared metrics and goals across teams, cross-functional teams that own features end-to-end, eliminating handoffs where work gets ‘thrown over the wall,’ and creating shared understanding through documentation, pairing, and knowledge sharing. The goal is ending the adversarial relationship where dev wants to ship fast and ops wants stability, instead both care about both outcomes together.
What is blameless culture and how does it improve engineering outcomes?
Blameless culture means: when incidents or mistakes happen, focus on understanding systemic causes rather than punishing individuals. Principles: assume people have good intentions and made best decisions with information available, recognize complex systems fail for multiple reasons (not one person’s fault), focus post-mortems on improving systems not finding scapegoats, share learnings openly to prevent similar issues, and create psychological safety so people report problems early. This improves outcomes because: people are honest about mistakes, issues surface quickly, teams learn from failures, and energy goes toward fixes not finger-pointing. Accountability still matters, but it’s shared, not individual blame.
How do you measure DevOps success beyond deployment frequency?
Comprehensive DevOps metrics: (1) Deployment frequency, how often you ship, (2) Lead time, time from code commit to production, (3) Mean time to recovery (MTTR), how fast you restore service after incidents, (4) Change failure rate, percentage of changes causing incidents, (5) SLO compliance, meeting reliability targets, (6) Developer productivity and satisfaction, (7) Incident frequency and severity over time, (8) Toil reduction, decreasing manual work through automation, (9) Cross-team collaboration quality, (10) Time spent on new features vs maintenance. Balance speed metrics with quality and sustainability metrics.
What are the biggest cultural obstacles to DevOps adoption?
Common obstacles: organizational silos with separate dev and ops departments, misaligned incentives (dev rewarded for features, ops for stability), lack of trust between teams, hero culture celebrating individual firefighting rather than prevention, fear of change and loss of control, insufficient executive support, existing processes that contradict DevOps principles, teams protecting their turf, insufficient investment in training and skill development, and measuring wrong things (individual productivity vs team outcomes). Cultural change is harder than technical change, requires leadership commitment, patience, and consistent reinforcement.
How do you implement shared ownership of production systems?
Shared ownership practices: developers participate in on-call rotations (feel pain of unreliable systems they build), operations participate in design and code reviews, teams own services end-to-end (build it, run it), shared metrics and dashboards visible to everyone, joint post-mortems with both dev and ops, cross-functional teams with mixed skills, ‘you build it, you run it’ philosophy, pair programming between dev and ops, shared budget and incentives, and rotations where developers join ops and vice versa. When developers are on-call for their own code, they suddenly care deeply about logging, monitoring, and operability.
How do you build DevOps culture in organizations new to these practices?
Implementation approach: start with leadership buy-in and clear communication of goals, form small pilot team to demonstrate practices, choose high-visibility project to show quick wins, invest in training and skill development, establish shared metrics and goals, create forums for cross-team collaboration, celebrate learnings from failures not just successes, gradually expand successful practices to more teams, address organizational obstacles that prevent collaboration, and be patient, cultural change takes months to years. Don’t mandate DevOps top-down; instead create conditions where teams want to adopt practices because they see benefits. Culture can’t be installed like software.